Swift struct (值类型) 与 class (引用类型) 区别及三种传参机制深刻关系和使用
在 Swift 中,struct(值类型)和 class(引用类型)的区别,不仅仅在于对象复制时候表现出来的差异,也不仅仅是构造器和继承的异同,本质上却是数据抽象层级的高低。
如果不能把值传参、地址传参和引用传参与类对象联系起来,也无法理解不同传参下对象的使用和 struct、class 的应用场景。
因为 struct 和 class 表现出来的是语法层面的差异,而项目使用中体现的是语义层级的差异。比如,Objective-C 里面的 NSString,它是引用类型,但是我们却在使用它的值语义。
1 | NSMutableString *oldname = @"hello".mutableCopy; |
我们使用了引用类型的 NSMutableString,但是 newname 并没有引用复制 oldname,仅仅是指针地址复制了 oldname。这样导致了 newname 并不是 oldname 的别名 (alias)。
如果 newname 是 oldname 的别名,那么对 newname 的所有 all 操作,都会同步到 oldname。
这里,newname 如果改变了对象数据是可以同步到 oldname,但是却不能改变 oldname 变量的值(oldname 的存储值,即 “hello” 的指针地址)。
所以,这里的 NSMutableString 虽然是引用类型,却具有值语义。
因为编程语言概念上的模糊,下面首先介绍 struct 和值类型的关系。
然后重点说明值类型和引用类型的区别,这是重点,直接解释了 struct 和 class 的根本区别。
最后加一点小彩蛋,介绍 Swift 里面 struct 特性。
0X00 struct 是什么?好像在哪里见过!struct 和值类型是什么关系?
好久好久之前,是没有 class 什么事的。那时候 C 语言活跃于各种应用场景,在上层抽象了汇编的实现,C 语言可以用于嵌入式、服务器、驱动等。为什么没有 class 什么事情?class 是类,是 OOP(面向对象编程 / 对象导向编程)的专属。而 C 语言是过程式语言,没有对象概念,也就没有 class 什么事情。
那时候,都用结构体,也就是 struct。如下:
1 | // C语言版本 |
那时候,这些数据都叫做值类型,而 struct 就是值类型的。值类型是变量直接包含值统称,其他的还有基础数据类型,如 Int,long,char,bool,以及自定义 struct(如上面的 Person)。
后面大家就知道了,出现了 C++/Java/C# 等 OOP 语言,class 开始活跃于千万家。更甚之,在某些语言上,值类型已经被淡化了。
1 | // Objective-C版本 .h |
以上为 OC 的版本,我们会这么描述它:我们创建了一个 Person 类。他具有名称属性和年龄属性。
而且,我们也确定,如果我们新建一个 Person 对象,如 Person *p = Person.new;,那么这个对象一定存放在堆内存。那我们为什么不能把对象创建在栈内存呢?
我们可以知道,上面 OC 创建的是 Class,对象存在于堆中。那我们可不可以把对象放在栈上?至少在 Objective-C 开发过程中,肯定不会想到这个,因为 struct / 结构体 / 值类型被淡化了。(Java 也是一样,号称纯 OOP 语言)
其实我们可以创建栈上的数据的,如局部变量中的 Int、long 等,都是在栈上的。说一个少见的,CGRect、CGSize 也是在栈上的。源码实现如下:
1 | /* Points. */ |
其实 OC 中使用的 CGRect 等,也就是 struct 值类型数据。只是我们很少顾及值类型,虽然一直用,但是感知不到他们的存在。
直到有一天,Swift 也成了苹果开发的官方语言,引入了 struct,一大堆开发人员开始迷惑,发生了什么事?我该怎么办?
1 | // Swift struct版本 |
同样的 Person,一个是 struct,一个是 class。一个复制的时候是全部数据复制,一个复制的时候是指针复制。一个有可能存放在栈上,一个只能存放在堆上。
放心了很多,原来 struct 和 Int、BOOL 等是一样的。他们本身不可以改变,只能被复制。struct 拥有和 Int 一样的外观。
等等,Swift 的 struct 可以引入方法,可以实现构造器,甚至可以通过 mutating 来改变自己。俨然已经上升可以和 class 平起平坐了(其实没有高低之分)。这怎么和 Int 又不太一样了?struct 到底是啥?
其实 struct 一直都没有消失。它一直在我们周边。仅仅是因为我们在个别面向对象语言的冲击下,淡化了值类型。
而现在,在 Swift 中,我们必须捡起来,因为值类型在 Swift 中不可或缺了。甚至 Swift 里面的 Int,String 等,都是通过 struct 直接实现的。
1 | /// A signed integer value type. |
相比之下,C++ 一直存在值类型,而且 C++ 里面的自定义的 struct 还可以继承和多态,完全面向对象化了。
0X01 值类型和引用类型的内存差异
值类型和引用类型,从语法上还是毕竟容易理解的。如果牵涉到语义,就比较复杂,因为上面说到的,引用类型就牵涉到了值语义。
我们先从语法上来理解值类型和引用类型的内存差异。
引用类型内存图
首先,class 是引用类型,一定是存放在堆内存上的。如下:
1 | // Swift class版本 |
那么我们定义一个 Person 对象时候的内存分布如下图: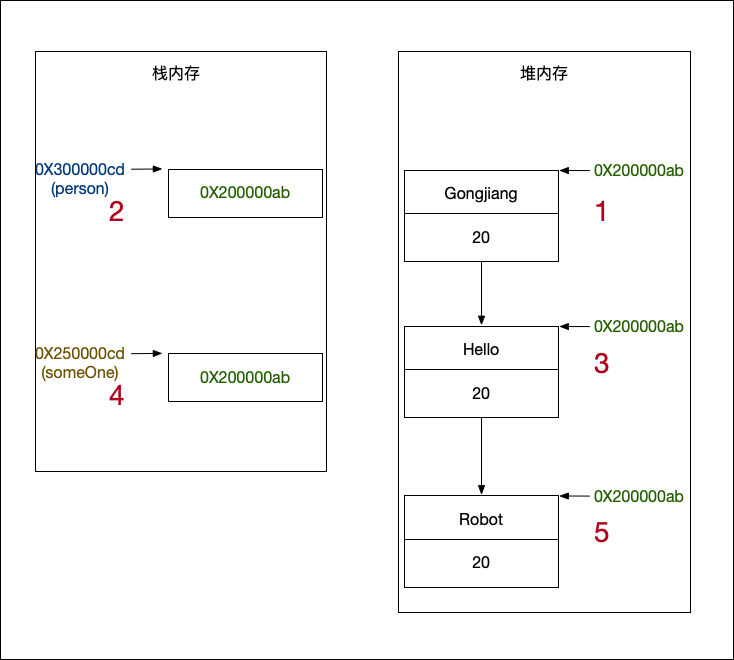
person 这个引用变量,我们使用的时候,可能存储在栈中的(也可能在堆中,但不是重点)。但是其指向的对象,却一定是在堆中的。
这里我们有两个名词认知不要弄混了,一个是 person 变量,一个是 person 对象。变量只是符号,编译的时候存储于符号表中的一个标记,对象才是我们使用的数据实体,变量用于找到对象。someOne 也是同理。下文中的变量和对象都是同理,后面不再做强调。
上面操作完成后,person 和 someOne 的 name 都变成 Robot 了,这是合情合理的,我们都司空见惯了,不做多描述。
值类型内存图
下面看看值类型,
1 | // Swift struct版本 |
内存分布如下图: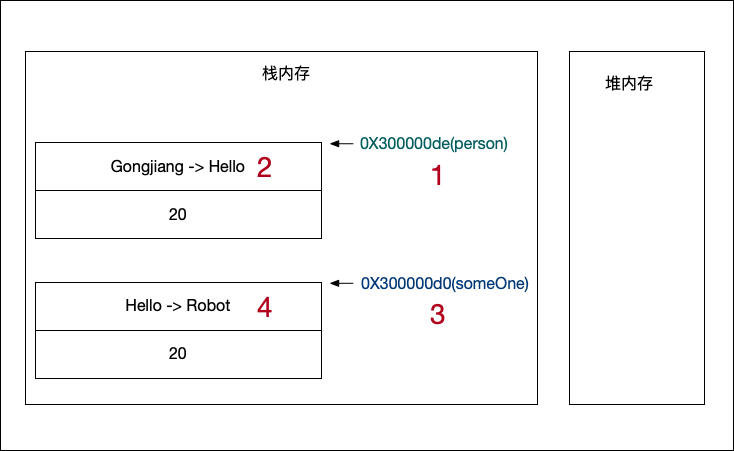
我们可以发现,值类型相比引用类型,person 和 someOne 这两个值变量,指向特征不那么明显了,更多的是复制。我们的 someOne 并没有指向 person,而是把 person 的数据完全复制了一份成为自己的。
更重要的,person 和 someOne 存储的,不再是对象的指针,而是真真实实的数据了。其实对象依旧还是对象,变量依旧是变量,如上面说的那样。但是,值变量,直接包含数据 (值类型的定义) 了,不再通过指针指向数据了。
当然,我们从图上看到的,值对象是在栈里面。当然值对象也会在堆里面,场景不一样,存储位置也会不一样。但是和引用对象不同的一点,值对象是可以存储在栈里面的。
我们经常使用的 Int 等,其实很多时候都是存储在栈里面的。上面 Person 引用类,其实也有 age 属性,这个 age 属性就是值对象存储在堆上,因为 person 对象是在堆上的。后面说到 struct 和 class 联动内嵌的时候,会详细说明
值类型和引用类型内存比较
显而易见,内存方式的不同,带来的优缺点也是迥异的。
最直接的,栈肯定是比堆快的。下面我们默认值对象存储在栈中,引用对象存储在堆中进行分析。
一来,值类型通过值变量直接定位数据,而引用类型需要通过引用变量的指针间接获取,在寻址方面就会出现时间劣势。
再者,栈通过 CPU 提供的指令寄存器操作数据,而堆通过操作系统支持。堆空间由程序员自行控制,包括垃圾回收等,CPU 不会干预过多。
其次,我们在栈上分配内存,是直接分配。而对于引用类型,只在栈上分配变量地址,对象需要另外分配堆内存空间。(可能会出现这种情况,需要 100 个对象,栈类型会在栈内存中直接分配完毕,而引用类型会在栈上一次性分配 100 个变量内存,然后在堆中需要进行 100 次对象内存分配。)
而且,由于堆内存是空间不连续性的(操作系统分配堆内存池供开发使用,如果一个对象销毁了,就会产生内存碎片),不连续堆空间会违背局部性原理,会增加高速缓存错失的几率(命中不了)。堆空间的高速缓存指的是二级缓存,而栈是依据 “LIFO” 的存储机制,不会出现内存碎片,天然增加了一级缓存的命中率。
特别,各种语言都会着重优化值类型,以达到更快的速度。毕竟栈处理速度的快慢,直接影响到程序的快慢。因为我们的代码运行根本依靠函数,而函数就是在栈中执行,如 main 函数和自定义函数。所以才会加入寄存器这样的快速单元,而堆里的数据,是可以通过异步来完成存储的。
因为值对象也是会存储在堆中,所以我们可以这样说:值类型有可能利用栈的优势,进一步提高程序的性能。
内存比较上,相比来说,值类型完胜引用类型。
引用类型相应的优点,
一来,发生在拷贝的过程中。值类型拷贝是完全拷贝,所有数据都会拷贝一遍,而引用类型,拷贝的仅仅是指针,从而提交效率。
二来,栈内存空间有有限的,相比堆内存空间,简直太小来,如著名的网站 “Stack Overflow” 的名字一样,动不动就会栈溢出。而堆内存,就是普通点的服务器,4G 容量不是问题的,高级点的服务器都是几十几百 G 容量。
我们可以看出,栈和堆相比,强于速度,弱于空间。虽然速度完胜,但除了空间,还有其他方面,引用类型却又是完胜值类型的。从 Java,Objective-C 这些语言上不难看出,引用类型的确是完胜值类型的。下面我们一点点来分析他们之间的不同和场景应用。
0X02 值类型和引用类型的相等性差异
值类型相等性比较
我们回顾一些最基础的值类型 Int 的相等性比较。
1 | var num1 = 100 |
上面代码编译运行,断言是可以通过的。值类型的比较,特别简单,就是比较数据是否一样。
因为值类型,不管存储在哪里,不变的一点是,值变量直接包含值对象。我们自定义一个值类型来看一下:
1 | // Swift struct版本 |
它们的内存图如下: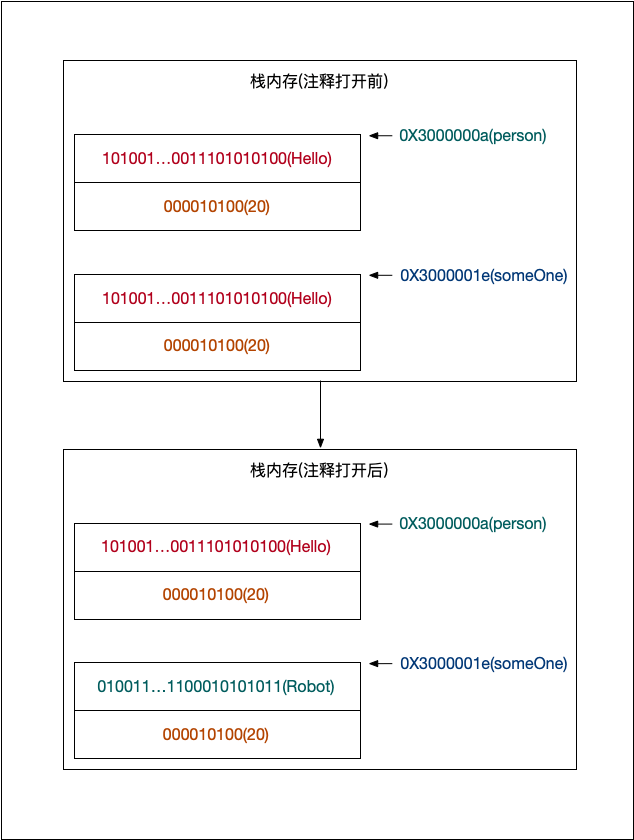
当两个值对象的 name 都是 Hello 的时候,两个值对象是相等的。如果 someOne 的 name 变成 Robot,两个值对象就是不想等的。(如果我们把注释的代码打开,相应注释位置上一行代码删除,会发现两个断言都是可以通过的。)
值类型的相等性比较真的非常简单,就是匹配字节码是否一致。只要值对象的所有字节码是一致的,那两个值对象就是相等的。字节码从哪里来?Hello 和 Robot,计算机不认识的,他们都会变成对应的码值然后转化成二进制存储内存中。所以值类型相等性判断就是查看二进制是否一样。
引用类型相等性比较
因为引用变量存储的是引用对象的内存地址。同样一个对象,可能有两个引用变量存储着其地址。
所以引用类型的比较,有两个方面,一个是比较存储的内存地址是否一致,另一个是比较内存地址对应的数据是否一致。
因为字符串在 Swift 里面是值类型的,我们用 Objective-C 里面的 NSString 来分析。
1 | NSString *str1 = [NSString stringWithFormat:@"%@", @"Hello"]; |
相应的内存图如下: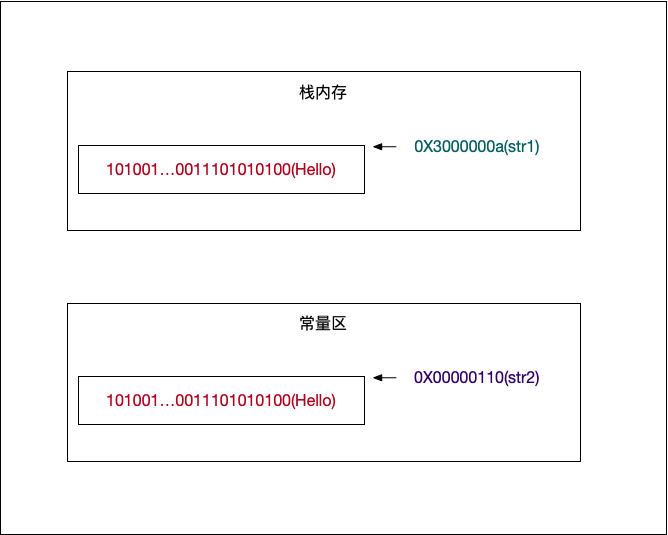
因为 Objective-C 对于字符串的生成比较考究(Objective-C 里面,字符串根据创建的形式不同和存储中英文的不同,有常量区、栈区、堆区不同表现形式),我们用上面方式建立两个不同地址的 Hello 字符串。其中比较相等性,一个是通过 **==,一个是通过 equal**。
引用类型的相等性比较,直接通过值类型的 == 比较的化,比较的是内存地址,显然 str1 和 str2,他们的内存地址不可能一样,所以他们并不相等。
而通过 equal 来比较,就变成了上面的值类型的字节码比较,Hello 的二进制存储都是一样的,他们就相等了。
0X03 值类型和引用类型在花式传参过程中的异同
如果不能把值传参、地址传参和引用传参与类对象联系起来,也无法理解不同传参下对象的使用和 struct、class 的应用场景。
为什么三种传参方式对 struct 和 class 的理解如此重要?其实他们本不重要,只是附带品。但是因为很多很多人对他们认知是错误的,所以才变得重要起来。
毕竟,错误的理论,总不能推导出来正确的知识。
首先,我们需要确定一个知识点,值传参、引用传参、地址传参和值类型、引用类型相比,虽然也有值和引用的区分,但他们不一一对应的关系,即不是值类型对应值传参。
值类型和引用类型是数据存在的方式,三种传参方式,是数据传递的方式。他们是对数据两个层面的操作控制。
所以,我们总共有 6 种情况需要分析:值类型下的值传参、引用传参、地址传参,引用类型下的值传参、引用传参、地址传参。
说明:因为引用传参很多语言默认都没有实现,如 Java、Objective-C、Swift 等等,所以需要通过 C++ 模拟。
值类型下的值传参、引用传参、地址传参
示例代码如下:
1 | // 值类型的值传参 |
1 | // 值类型的地址传参 |
1 | // 值类型的引用传参 |
上面的内存分布如图: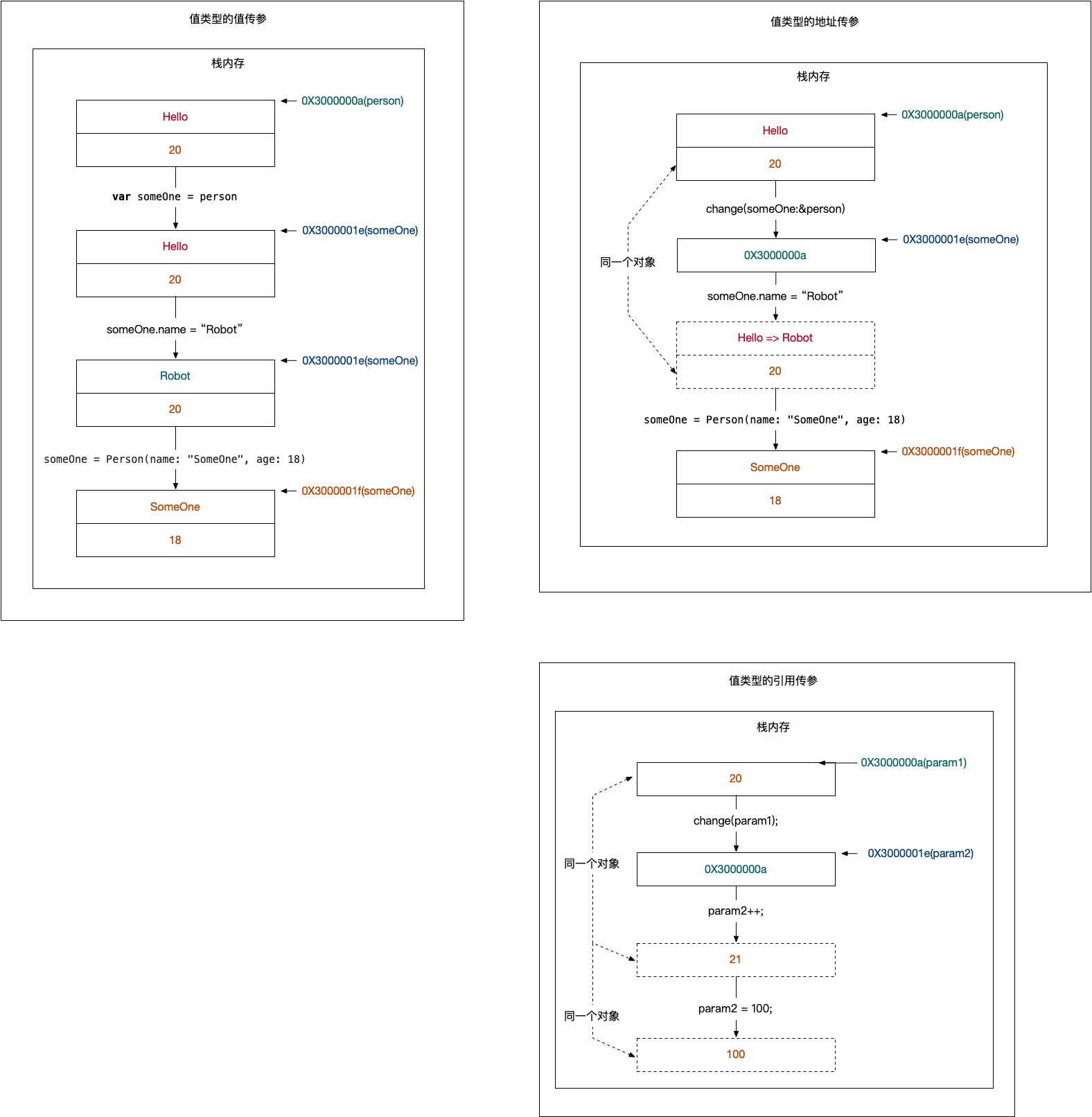
我们分析一下值类型下的三种传参,
- 值传参,就是行参对象原封不动的获取了实参对象的数据拷贝。两个对象之间不再有任何关联,对行参对象的内部修改 (someOne.name = “Robot”) 和自身修改 (someOne = Person (name: “SomeOne”, age: 18)),都不会更改另一个对象的任何数据。如上图所示,person 对象没有任何修改。
- 地址传参,就是行参对象原封不动的获取了实参对象的地址拷贝。所以行参实际存储的是实参的内存地址拷贝。那么通过内存地址对数据的内部修改 (someOne.name = “Robot”) 都会影响到原对象,毕竟对象只有一个。但是行参自身修改 (someOne = Person (name: “SomeOne”, age: 18)),却不会影响到原对象,因为行参是实参的地址拷贝,自身数据的改变就是改变了拷贝的那份内存地址,不会影响到实参。所以地址传参,本质还是值传参,因为拷贝了实参的内存地址(而非整个对象数据)。而通过内存地址修改原数据,这是一种途径,和传参无关,因为内存地址本身就是用来获取和修改数据的。
- 引用传参,分析起来其实最简单的。那就是,行参仅仅是实参的一个别名 (alias)。行参存储的依旧是实参的内存地址拷贝,但是对行参所有的操作,都会通过间接寻址的方式直接操作实参。注意,是所有操作,因为行参仅仅是实参的别名。所以我们看到,引用传参里面,行参不仅可以修改原对象数据,还可以更换原对象。(这个更换原对象,有两种方式,上图中是其中一种,即在原对象内部修改数据,没有创建新对象。还有一种方式是创建一个全新的对象,然后实参指向新对象,是以新换旧的思想。但是原理都不变,都是行参操作实参直接改变数据。)
通过上面值类型的三种传参,大家可能已经发现,在 Objective-C、Java、Swift 里面进行值类型的实参行参赋值的时候,其实都只是值传参和地址传参,并没有引用传参。只有个别语言如 C++ 里面才支持引用传参。
上面说明的是值类型,那么引用类型的三种传参是否会有一些不同呢?
引用类型下的值传参、引用传参、地址传参
示例代码如下:
1 | // 引用类型的值传参 |
1 | // 引用类型下的地址传参 |
1 | // 引用类型下的引用传参 |
上面的内存分布如图: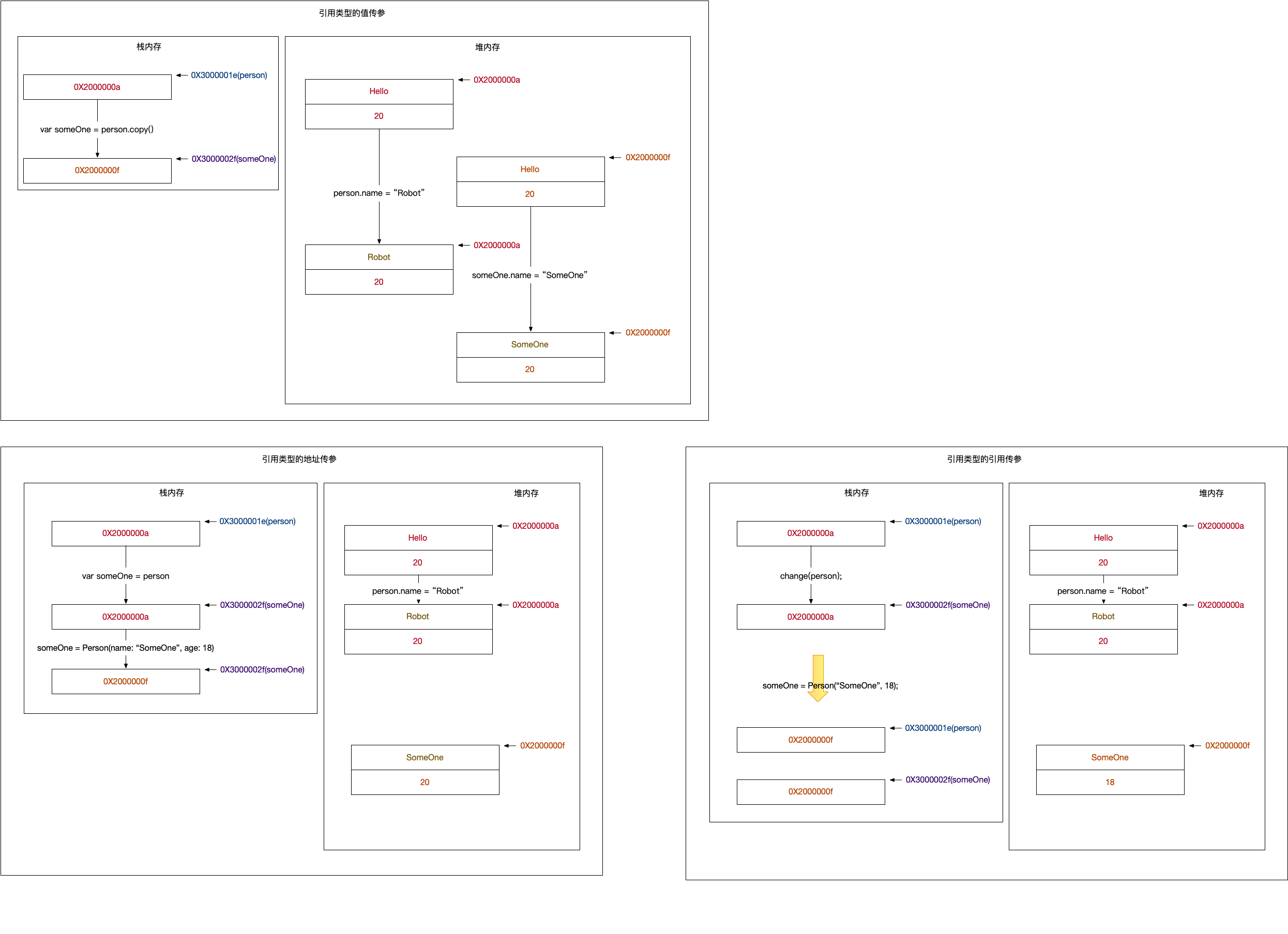
我们分析一下引用类型下的三种传参,
- 值传参,因为引用类型不支持值传参,所以我们使用 copy,模拟了值传参。这也是深拷贝的实现方式。我们通过自定义 copy 来实现引用类型的值传参。
- 地址传参,和值类型的地址传参没有区别。
- 引用传参,和值类型的引用传参没有区别。
我们发现,值类型的直接赋值,使用的是值传参。引用类型的直接赋值,使用的是地址传参。而在值类型下的三种传参分析中,我们分析到地址传参就是特殊的值传参。
所以我们可以得出结论,值类型和引用类型的直接赋值,都是值传参的形式。而引用传参,需要语言级别的实现,目前 C++ 有实现,Java、Objective-C、Swift 等语言中皆没有实现。
花式传参总结
值传参、地址传参、引用传参,是数据赋值过程中的不同表现形式。而地址传参,本质还是值传参。所以我们可以说只有两种传参方式,即值传参和引用传参。
而值传参和引用传参,和值类型与引用类型不是一一对应的关系,具体不同是下文说到的语义的不同,即:
- 根据我们使用的场景,我们可以通过将值传参和引用传参作用于值类型对象上。
- 根据我们使用的场景,我们也可以通过将值传参和引用传参作用于引用类型对象上。
- 如果我们需要改变实参,则我们需要引用传参。(很多语言不支持)
- 如果我们不需要改变实参,则我们需要值传参。如果想进一步改变原对象的部分值,则需要地址传参通过指针来实现。
0X04 值语义和引用语义的联动性
直观来说,值类型语法上是静态的,变量直接包含并操作数据。引用类型语法上是动态的,通过对象的引用操作数据。从值类型和引用类型的内存结构图可以分析出来。
所以,我们引申出值语义,即数据是静态的,也就是值传参的逻辑,是数据拷贝,是一份全新的数据。
我们也引申出引用语义,即数据是动态的,也就是引用传参的逻辑,数据可以通过别名操作,数据本身没有进行任何复制。
所以我们可以这样理解,值类型默认应该是值语义的,引用类型默认应该是引用语义的。
如下所示:
1 | // 值变量v1与v2互相独立 |
上面 v1 和 v2 都是值类型 ValueType 的对象,其中 v1 和 v2 没有任何关联,默认的值传参。
上面 r1 和 r2 都是引用类型 ReferenceType 的对象,其中 r2 是 r1 的别名,操作 r2 和操作 r1 完全一样。
但是事与愿违,至少引用类型的默认引用传参,就是很多语言所不支持的。我们的 Swift 就没有办法实现引用类型的引用传参。即上面的 r1 和 r2 如果在 Swift 中定义,那么 r2 不是 r1 的别名,仅仅是 r1 存储的 someObject 地址的一份拷贝。
所以,严格按照引申出来的值语义和引用语义的定义,那么很多语言都没有引用语义了。这显然是片面的,因为我们的地址传参,也可以通过指针操作数据来实现动态性。
所以严格的定义如下:
值语义的对象是独立的,
引用语义的对象却是允许共享的。
理解下来,就是:
值传参具有值语义,因为值传参后行参实参两个对象完全独立。
地址传参和引用传参,具有引用语义,因为行参可以通过指针或者别名(实质还是指针,间接寻址方式)来操作实参对象。
我们在 “花式传参” 中说到有 6 种传参方式,因为值类型对应三种传参,引用类型也对应三种传参。
所以我们可以发现:
值类型通过地址传参和引用传参,可以实现引用语义。
引用类型通过值传参,可以实现值语义。
代码示例如下:
1 | // 值类型的 ValueType具有引用语义(C++) |
而相应的语言如 Objective-C 就有很多语义层级的类型处理,将值类型处理成引用语义,将引用类型处理成值语义。如下:
1 | // int值类型具有引用语义 |
所以,
语法上的值类型可能是语义上的引用类型,
语法上的引用类型可能是语义上的值类型。
0X05 值类型和引用类型的抽象层级差异
在文章开头提到的值类型和引用类型的内存模型中,已经明确值类型是直接包含数据,而引用类型是通过内存地址间接操作数据。
从内存分布上,我们可以模糊的发现:
- 值类型,重在数据,是静态的。如果一个数据是通过值类型来展示,那么这个数据重在数据的价值。这个数据一定非常重要,而我们可以通过值变量直接获取。
- 引用类型,重在如何使用,是动态的。如果一个数据是通过引用类型来展示,那么这个数据重在如何被使用。这个数据当然也重要,但是我们可以通过指针和引用 (别名 / 间接寻址) 变相获取,而指针可以赋值给其他变量,最后可以通过各个变量来获取。
我们可以创建各种面向对象的引用类型 (class),然后实现继承和多态,这是引用类型带来的益处。因为我们可以通过指针和引用轻松的实现多态特征。
而对于值类型 (struct),Swift 文档里直接说明,struct 不允许继承和重载。值类型在编译期间具体类型就已经确定,多态绑定也是不可能,因为其空间大小已经确定,没有空余空间容纳子类型。
所以从抽象层级上来观看,引用类型相比值类型,抽象层级更高。
因为值类型在编译期间空间大小和具体类型已经确定,所以值类型完全就是不依赖内存地址的,这也是为什么值变量直接包含值对象的原因,所以值类型是具有空间无关性的。而引用类型存储于堆中,必须通过指针进行访问,显然引用类型和空间是强关联的。
而且,值类型的数据在值对象生命周期内是固定的,体现了不可变性,具有时间无关性。即使通过地址传参和引用传参,我们可以改变值对象的数据,那也是在原来的存储空间中,用新数据覆盖旧数据,使用了旧数据的存储空间而已。引用类型的改变是一种自我更新,对象上发生状态迁移和属性改变。
因为值类型的时间无关性和空间无关性,所以值类型天然具有重数据,对象意识淡薄,更多的体现在属性而非实体。比如我们描述一个 Person 的 struct,更多的体现在用 age,sex 等抽象属性来描述 “20”“男” 这样的具体数据(“20”、“男” 本身是具体的,age、sex 属性则是面向对象层级的抽象描述)。
而引用类型与值类型相比是对立面的抽象表达,更多的体现一个实体对象。比如我们描述一个 Person 的 class,更多的体现在男人、女人、好人、坏人这样的实体对象。
总结来看,值类型是引用类型的基础,值类型在内存和速度的使用上,拥有更快的速度。引用类型在值类型之上进行了更多的抽象。
引用类型依靠间接性和抽象性,相比值类型拥有来更大的灵活性,小方面来说在赋值上通过地址传参和引用传参节省了时间损耗,大方面来说通过间接性和抽象性,直接成为实现多态的必要条件。
这也从侧面反映了 class 可以继承和多态,看起来繁荣昌盛,而 struct 则显得不起眼,为居一隅却撑起来整个面向对象大厦。
0X06 struct 和 class 联动内嵌下的认知
单个分析值类型和引用类型还比较容易理解,如果值类型和引用类型相互嵌套,虽然并不是复杂的逻辑,但如果不画图理解一下,很容易脑回路阻塞。
下面通过示例代码和内存图清晰了解一下:
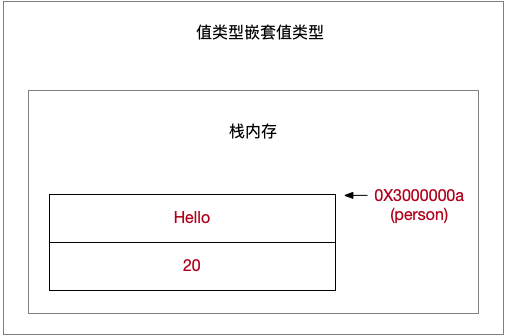
值类型嵌套值类型
1 | // Swift struct版本 |
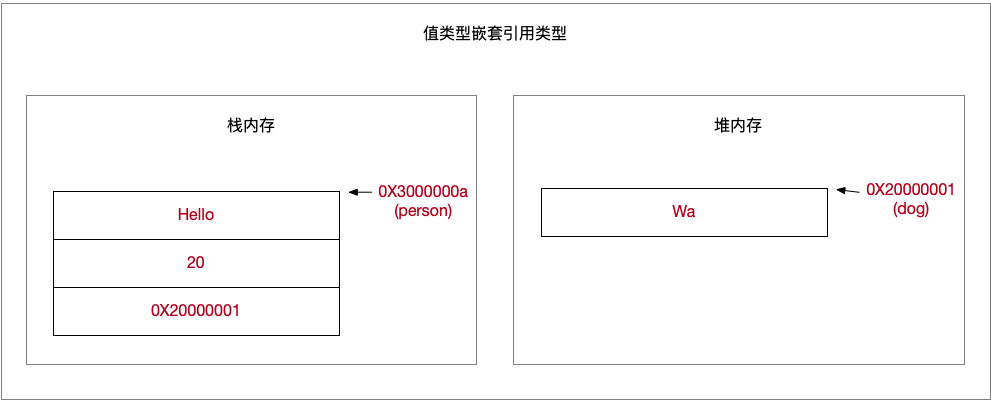
值类型嵌套引用类型
1 | // Swift class版本 |
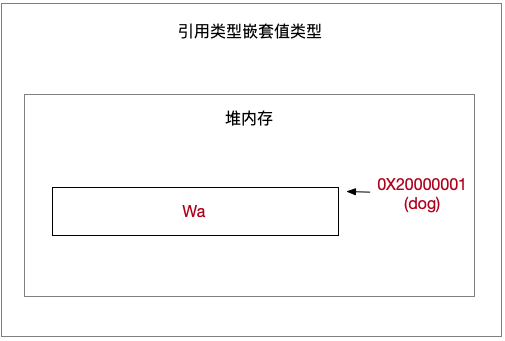
引用类型嵌套值类型
1 | // Swift class版本 |
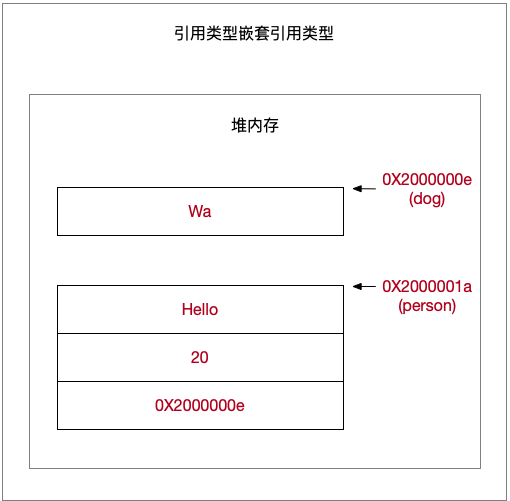
引用类型嵌套引用类型
1 | // Swift class版本 |
0X07 Swift 中的 struct 为什么很特别?struct 能给我们带来哪些认知?
本身 struct 不是很特别,但是在目前很流行的语言(Objective-C、Java)均不支持自定义 struct 的前提下,Swift 开始支持了。而且 Swift 本身如 String、Int、Bool 等均为 struct。Swift 把已经被很多开发人员忽视的值类型提到了非常高的高度,这就非常值的重视了。
- 值对象本身是比引用对象安全的。通过指针可以直接操作数据,如果代码逻辑比较复杂,那么在一个不起眼的位置,很可能修改了一个共享的重要参数,非常有利于 bug 的滋生和增加 bug 排查复杂度。相比来说,值对象具有空间无关性,代码层面上可以有效的抵制指针带来的负面影响。所以值对象是更安全的。
- struct 没有引用计数,本身是自动线程安全的。
- 在上面值类型和引用类型的内存差异中,我们说到,值类型相比引用类型,有速度上的天然优势。
- struct 没有继承,相对来说更安全,而且 struct 可以实现协议,可以很好的实现面向协议编程。Swift 是一门多范式编程的语言,其中对于面向协议编程尤其重视。
OX08 Swift 下 String 的搅局误区
在讨论 Swift 的值类型中,多次提到 String 类型是值类型的。我相信很多朋友都疑惑,String 作为值类型是如何实现的。
毕竟,下面的代码中:
1 | var str = "Hello" |
我们定义了一个可变变量 str 为值类型的字符串变量,按照内存图逻辑,在 str 拼接了 1000 个 Hello 后,再怎么说,str 的空间存储也不够了。
如果 str 的内存地址变化了,那么就说明 str 不是值类型了(上面我们说过值类型的内存变化)。
如果 str 的内存地址没有变,那 str 再怎么也存储不了无限多个字符啊!
我们拿 Int 来做对比:
1 | var i: Int8 = 10 |
这里如果对 Int8 值类型的变量赋值过大,首先编译就过不了了,超过 Int8 的存储空间了嘛。
值类型的空间大小,在编译时就已经确定,这是毋庸置疑的。
那 String 是如何做到的呢?
打印一下上面代码中的 str 大小,看看到底是多大:
1 | var str = "Hello" |
可以发现,str 的内存大小,没有变化过…
这也说明了,String 的确是值类型的,它真的可以存储非常非常多的字符。
我在查看了 “M 了个 J” 大神的博客后,依然无解,因为他把答案公布在了两小时的汇编视频中,而我没有去看。
这里把大神的博客放下,希望有心人能去窥探一下。
https://www.cnblogs.com/mjios/p/11799136.html
朋友对我说,抽象是一名程序员核心的能力。很多时候,我越发觉得这句话说的对!