锁 - 共享数据安全指↑
锁,是并发 & 并行编程下的万能钥匙,也是最容易产生性能瓶颈的源头。在锁的前面有软硬件在协同铺路,在锁的后面还有数据结构和算法在帮忙黄袍加身。
提前说明,本篇涵盖内容非常多,达到 4W 字。可分多餐多时间段食用,每个章节可独立阅读,问题不大。一定不要一口气阅读完,选章节阅读确认对自己有用,再细看不迟。
内存相关的知识非常重要,需要很大篇幅和示例图来阐述。另一篇文章内存分段与分页对 CPU 和内存的数据读取做了详细阐述。在内存分段与分页中文字数超过了 1W,本文的文字数也超过了 4W,均需要多张配图。重要性和难理解程度,都很高。
共享数据安全牵涉到的点很多,从硬件层面的多核心高速缓存、MESI 缓存一致性模型、CPU 乱序执行 & 中断、总线 & 缓存原子锁,到操作系统提供的锁和编译器优化 & 重排,以及高级语言为不同业务场景不断叠加的中间层锁优化,最后还有算法如何进一步保障锁的性能。
大家都知道并发并行场景下共享数据会不安全,本文不是阐述数据不安全会造成的严重影响,而是为什么共享数据会不安全。
数据安全产生的物理原因
单核 - 时间片轮转下的数据安全问题(并发 & 中断)
时间片轮转是针对分时系统来说的,即单个 CPU 对于每个任务的执行,都只执行一小段时间,不断的在多个任务之间快速的切换。初期是在多个进程之间不停的切,嫌弃进程切换代价太高,出现了多线程技术方案后,CPU 又在多个进程和线程之间不停的切换执行。多进程和多线程是一种提高 CPU 使用率的方案,即并发。
CPU 在任务执行过程中,本身是感知不到时间片存在。在晶振产生的时钟周期驱动下,CPU 会不间断的根据 PC 寄存器里的地址进行取址译码执行。晶振是一个中断,中断的频率越高,CPU 执行的速度也就越快。而时间片一切,PC 寄存器的地址改变,CPU 就被动的在多个任务之间切换执行。
时间片切换有两个来源,一个是操作系统控制的并发,一个是软硬件中断。并发本身也是通过晶振中断来实现的,因为由操作系统控制,额外增加了优先级队列等一系列控制,所以单独作为一个来源来分析比较清晰。
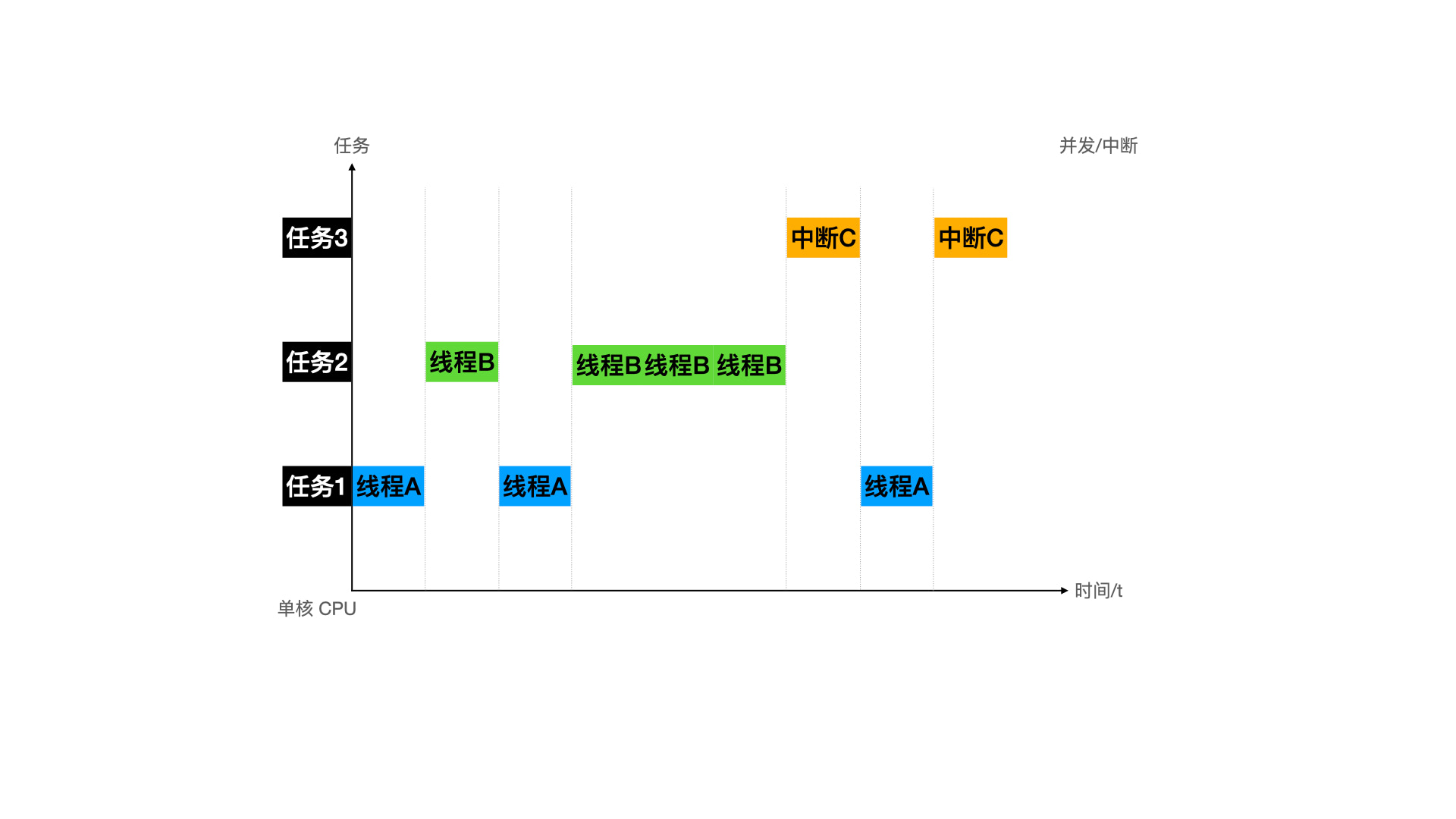
所以现在就通过并发和中断,来分析时间片切换可能会导致的共享数据安全问题。单核场景会遇到并发和中断,多核在单核的基础上又遇到了其他问题,这里就先说单核,下一趴说多核。
非原子操作 - 并发
就是大家都知道的,我们写的代码如果在多线程场景下,如果有共享数据,那么共享数据会不安全,会产生数据紊乱。
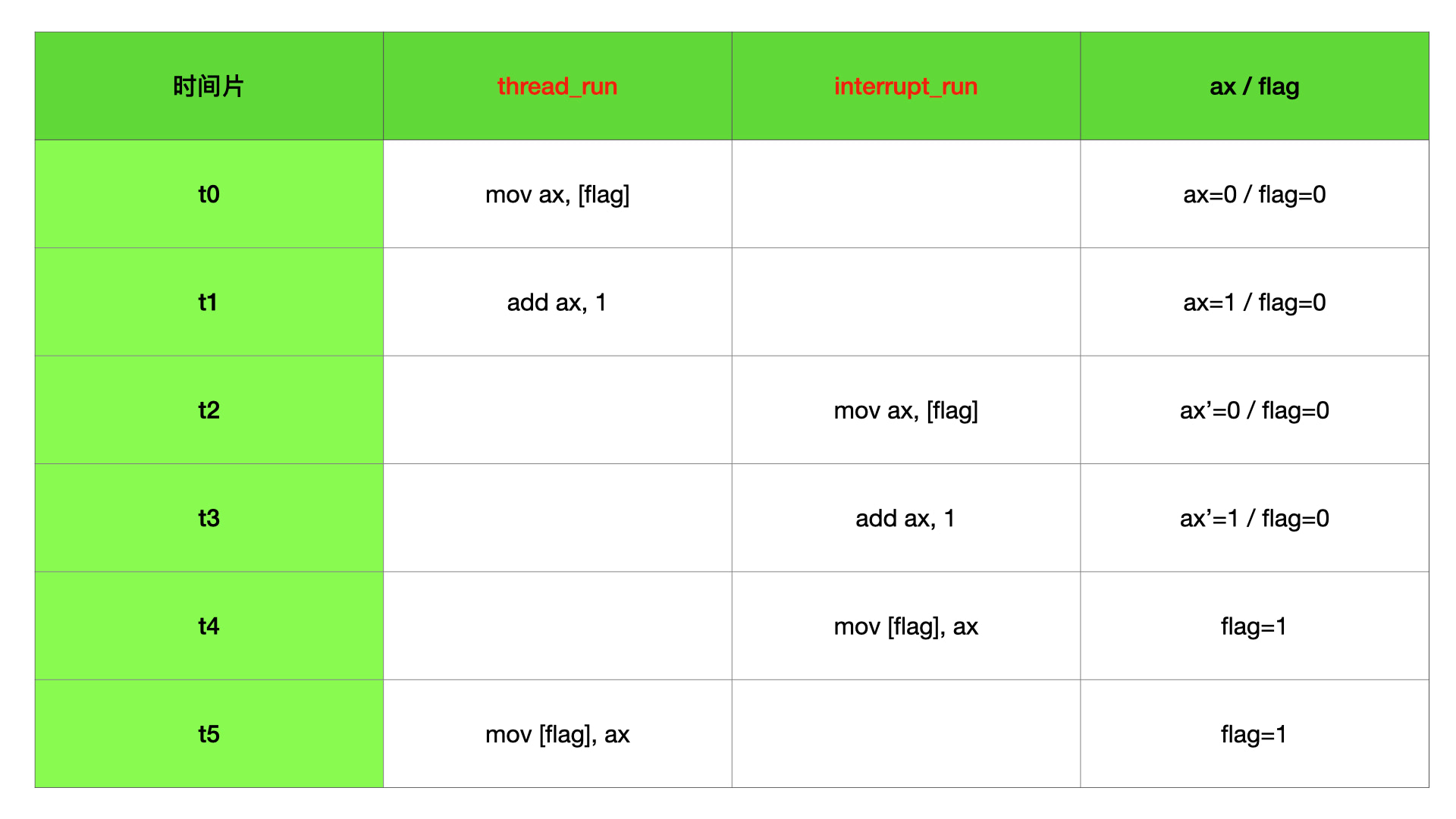
1 | int flag = 0; |
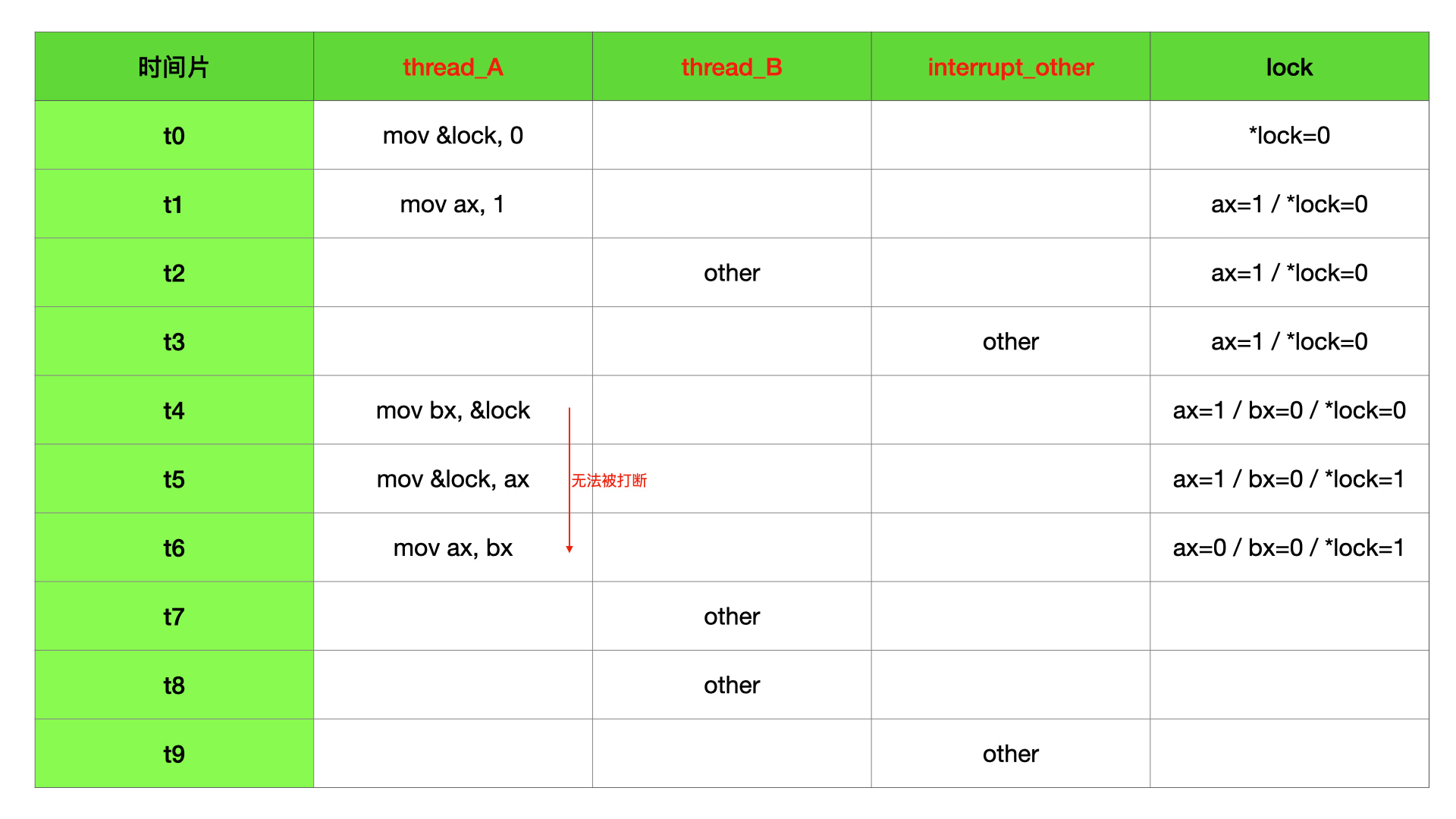
上面代码,flag 是共享数据,threads 被并发执行。当 threads 函数被 1000 个线程并发执行的时候,最后 flag 的值 < 1000,极小概率 = 1000。因为 flag++ 需要最少三条指令才能运行完毕,分别是读内存、寄存器赋值、写内存。这里就会出现 a 线程执行了读内存指令后,时间片切到了 b 线程,b 线程完成了读、赋值、写指令,又切回到 a 线程,a 继续完成赋值和写指令。因为 a、b 读到的内存值是一样的,最后写入的也就是一样的,所以 flag 相当于少了一次 + 1 操作。时间片轮转对于指令执行流程来说是随机的,所以 a 和 b 的三个指令完全有可能任意交叉执行。详见下表:
非原子操作 - 中断
上面也说到,并发是根据晶振中断实现的。除了晶振中断,还有其他的软硬件中断会改变 CPU 的执行流程。如果改写了中断向量表的中断指向或者我们在监控到中断到来时执行特定函数,一样会遇到和上面的并发一样的数据安全问题,代码如下:
1 | int flag = 0; |
我们假设 thread_run 函数是单线程执行的,因为中断时机是未知的,完全有可能 interrupt_run 和 thread_run 的执行时机会出现上面并发场景下的情况,这个时候 flag 也不再数据安全。和并发一样,详见下表:
非原子操作阐述
非原子操作,即任务执行过程中可能会因为时间片轮转发生执行中断情况的操作。如果非原子操作中出现共享数据,则共享数据不在安全,可能会产生紊乱。
这里有两个前提,即非原子操作和共享数据。如果没有共享数据,相当于 1 个 CPU 的两条任务线独立执行,是没有问题的。那如果是原子操作呢?
原子操作 - 并发 & 中断
对于原子操作,即执行周期内不会被打断的指令。该指令可能需要多个时钟周期才能运行完毕,因为有取址、译码、执行一套动作,最少也需要 1 个时钟周期,全过程称为执行周期。在执行周期内,该指令一定有头有尾的被执行完毕,即要么不执行,要么全执行。
所以可以猜想和非原子操作的不同,因为没有产生执行中断,那么共享数据或许是安全的。下面举几个特别的原子操作来说明共享数据的安全性。
内存原子操作
1 | // 内存原子操作指令。 |
上面代码中,lock 初始值为 0,完成了上面 flag++ 同样的工作。threads 不管在并发场景还是中断场景,lock 内存地址里面的值都是安全的。即 1000 个线程并发执行完成后,lock 值一定是 1000。
addl 内部是需要多个操作完成的,首先,需要取 lock 内存地址里面的值到中间寄存器 ax,然后,需要将 ax 寄存器中的值加 1,最后,再将 ax 寄存器中的值写入 lock 内存地址中,所以 addl 和上面高级语言中的 flag++ 是一样的内存操作流程。上面的 flag++ 大家已经知道不是数据安全的,因为他的执行流程会因为时间片轮转的原因被打断导致共享数据被其他任务修改,那么 addl 在时间片轮转下如何表现呢?
比如 addl 已经取了 lock 内存地址里面的值,还没进行 ax 寄存器加 1 操作,这个时候有没有可能因为时间片轮转导致 *lock = 100; 这个其他任务里面的命令被执行呢?不会的,因为 addl 是原子操作,addl 没有执行完,时间片轮转不会发生,这个时候共享数据不会被其他任务更改。
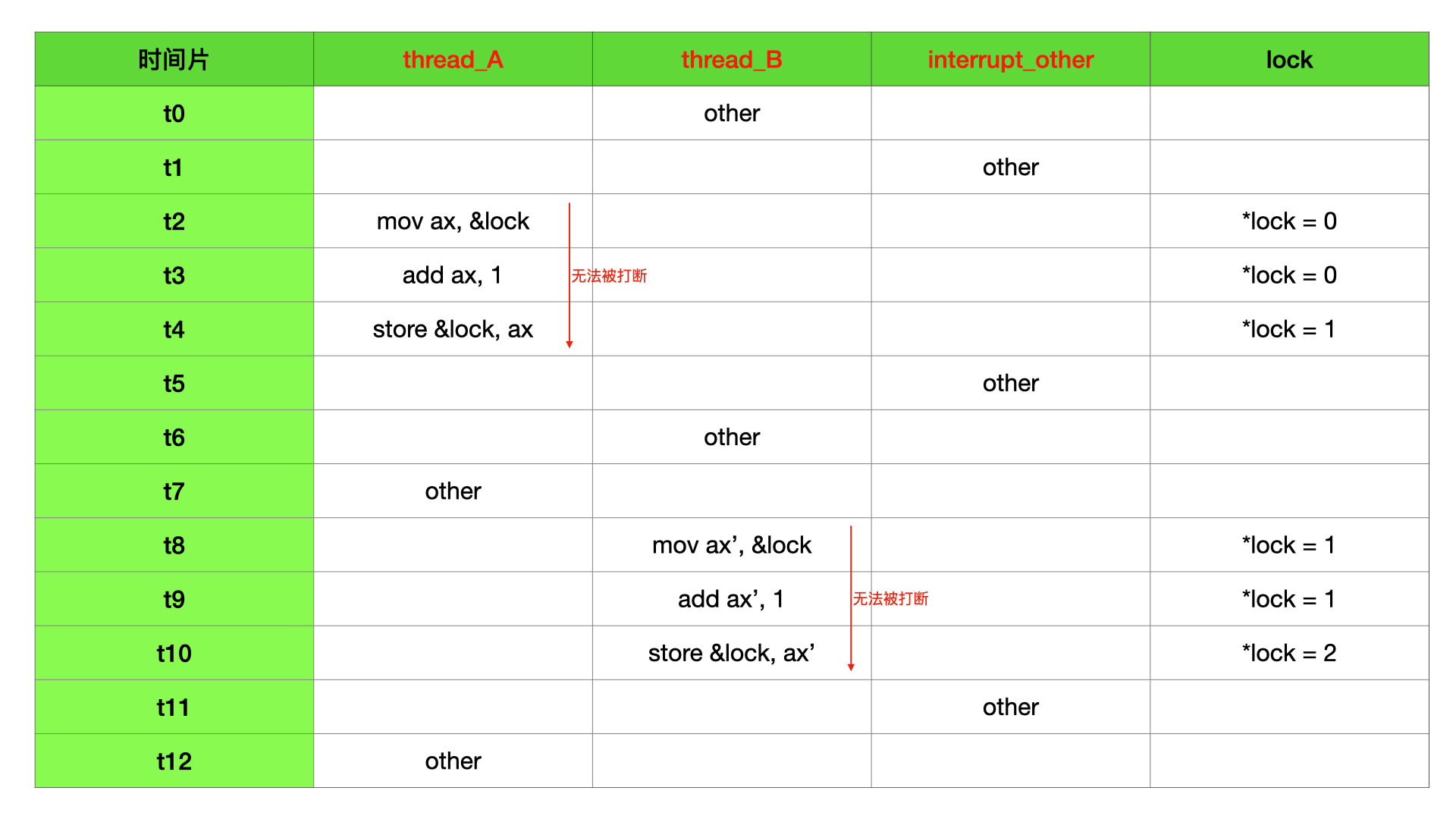
通过上面的分析,即使 addl 指令需要很多个时钟周期才能完成一次寄存器和内存数据的交换操作,和 flag++ 有一样的内存操作流程,但 lock 是共享数据安全的。即内存原子操作,在并发 / 中断场景下,共享数据是安全的。
寄存器原子操作
1 | // 寄存器原子操作指令。 |
因为我们这里讨论的是共享数据安全问题,这种问题一般都不出现在寄存器中,而是出现在高速缓存或者内存中。比如前面的 flag++ 和 addl &lock, 1 以及后面要说的 xchg 和 cmpxchg 这些,指令中都可以操作内存地址。但是这里还是提一下,对于示例中 ax 寄存器的原子操作,没法说安全不安全,因为寄存器不能当作一个共享变量来看待,即 add ax, 0; 这里的 ax,根本不可能是两个线程里面的共享寄存器。所以上面的示例代码其实是不存在的。并发场景下,从 a 线程切到 b 线程,会对 a 线程里面的 ax 寄存器值保存到内存,然后到 b 线程重新配置使用 ax 寄存器。后面回到 a 线程后,ax 寄存器会从 内存中重新拿到上一次保存到值。所以在并发场景下,ax 寄存器是独立存在的,不存在数据共享问题。
xchg 原子操作
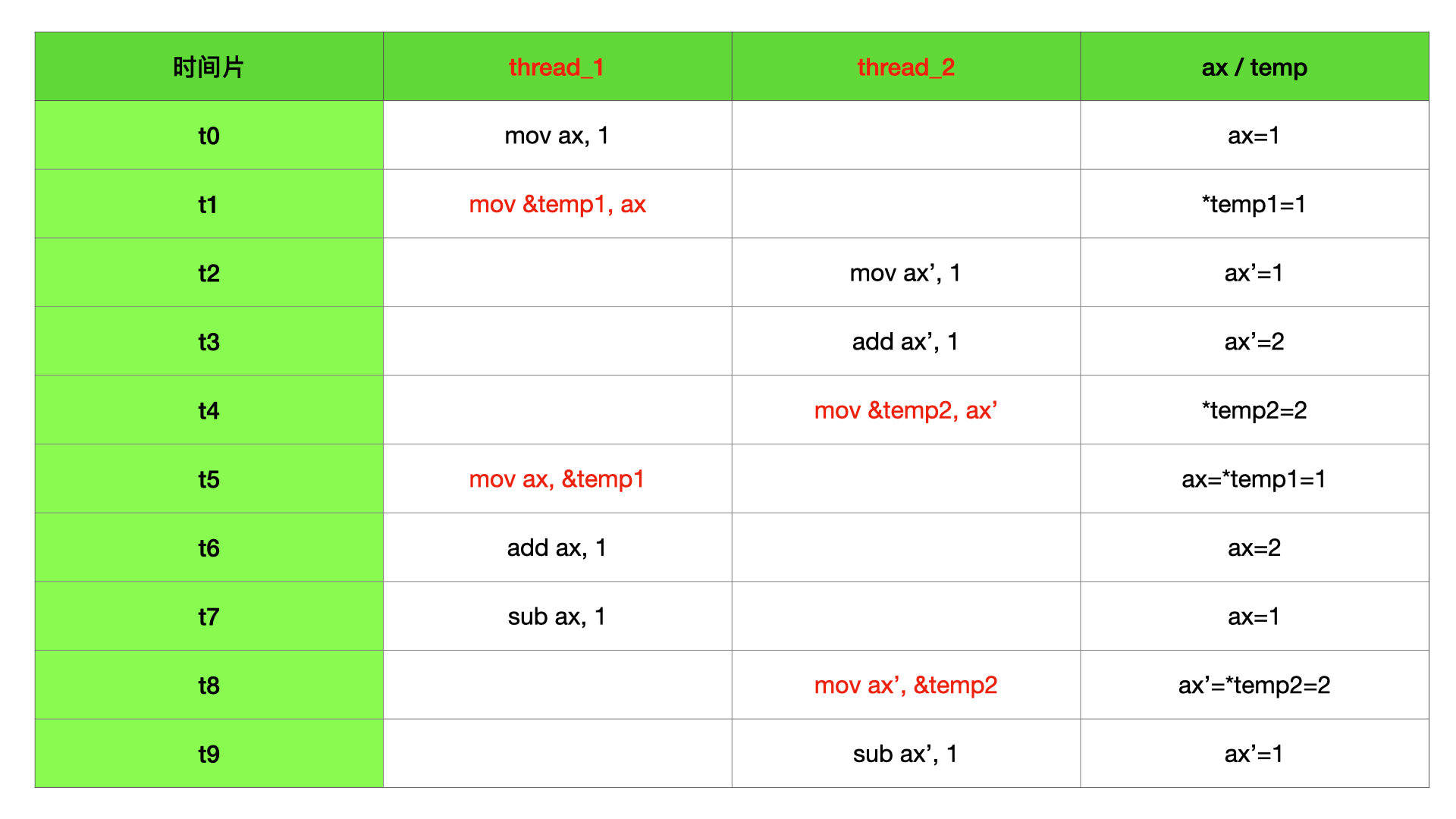
1 | // xchg 内存交换指令 |
上面代码中,xchg 是 x86 提供的内存交换指令,即将一个寄存器值和一个内存地址中的值进行原子操作交换。比如上面例子,lock 内存地址默认值为 0,ax 寄存器默认值为 1。在 threads 执行一次后,lock 内存地址中的值会变成 1,ax 寄存器中值会变成 0。再执行一次,则因为 ax 寄存器中值为 0,所以再次互换后,就回到了初始的默认状态,即 lock 为 0,ax 为 1。
可以得到一个规律,执行奇数次 “并发 / 中断” 操作,则 lock 内存地址值为 1,ax 寄存器值为 0。执行偶数次 “并发 / 中断” 操作,则 lock 内存地址值为 0,ax 寄存器值为 1。这个时候,不管我们怎么执行,只要控制住次数,那么结果就是确定的。我们可以以此理解 xchg 原子操作在并发 / 中断场景下是安全的,但不准确,xchg 原子操作的安全,就和上面的内存原子操作是安全的一样。
xchg 和上面的 addl &lock, 1; 指令相比,xchg 内部只是多了一个 ax 寄存器,其他都是一样的。首先,需要取 lock 内存地址里面的值到中间寄存器 bx,然后,需要将 ax 寄存器中的值写入 lock 内存地址,最后,再将 bx 寄存器中的值写入 ax 寄存器中。所以可以和内存原子操作一样理解。
xchg 原子操作很重要,是自旋锁的底层实现。下面锁的篇章会再次说到。
cmpxchg 原子操作
1 | // cmpxchg 比较交换指令 |
上面代码中,cmpxchg 是 x86 提供的比较交换指令,共需要 2 个寄存器和 1 个寄存器或者内存地址。
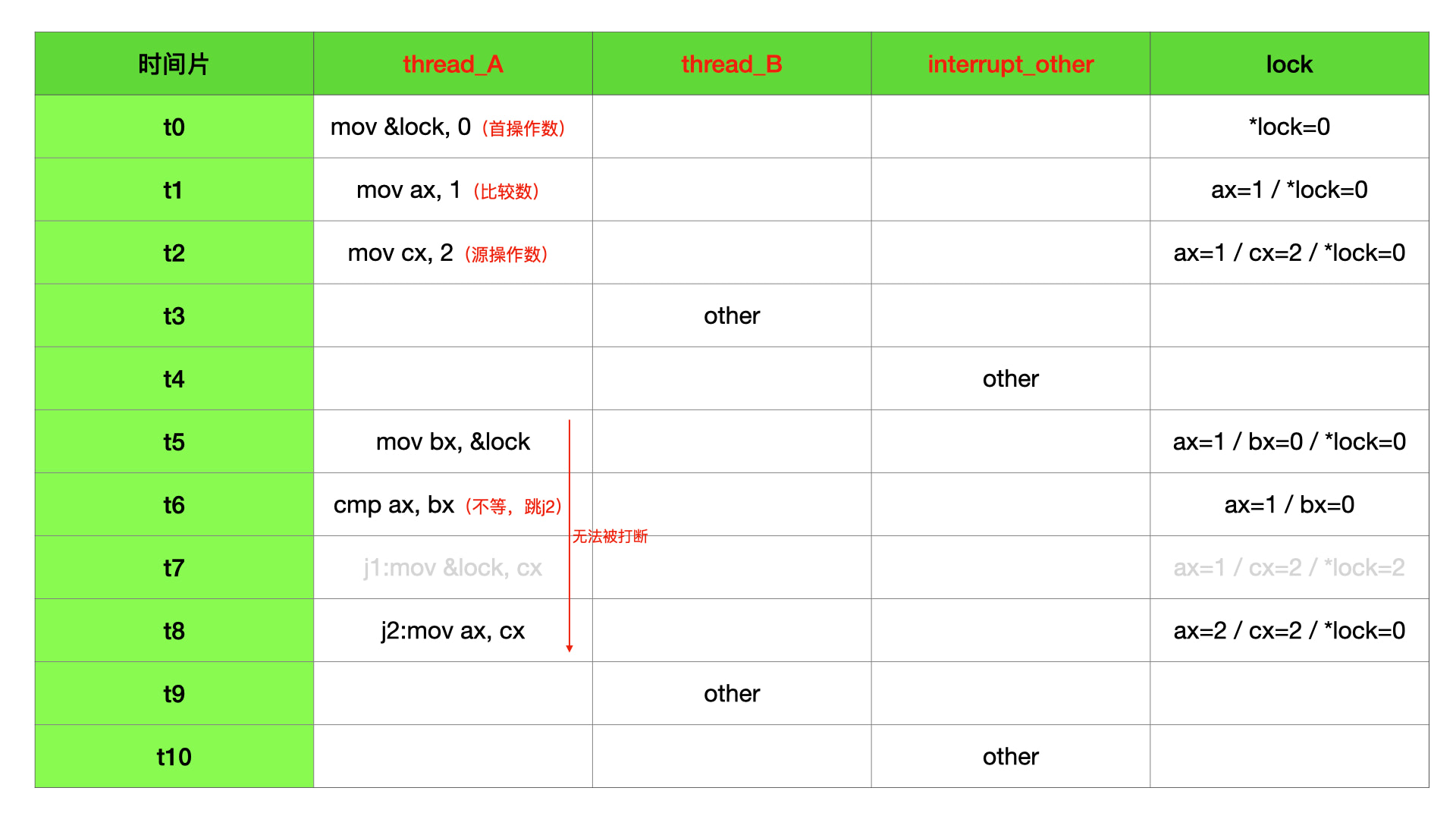
首先需要有一个用于比较的值,这个值需要在寄存器中,上面我们用 ax 存储。
还需要一个 “首操作数”,即 cmpxchg 指令后面的第一个操作数,这个操作数可以是寄存器或者内存地址,上面我们用 bx 或者 &lock 表示。
最后还需要 “源操作数”,即 cmpxchg 指令后面的第二个操作数,这个操作数需要在寄存器中,上面我们用 cx 存储。
cmpxchg 就是让比较值和首操作数比大小,如果相等,则首操作数赋值为源操作数。如果不想等,则比较值赋值为源操作数。
我们分析 cmpxchg &lock, cx; 这种场景,因为 ax 为 1,lock 内存地址值为 0,两者不想等,所以 cmpxchg 指令执行完成后,lock 没有变化,ax 寄存器变成了 2。如果按照上面注释里面 lock 初始化为 1,则 ax 和 lock 内存地址值都是 1,两者想等,这个时候 lock 内存地址值会变成 2。
cmpxchg 也是数据安全的,和上面 xchg 的分析一样,即使 cmpxchg 的执行需要很多个时钟周期,包含内存写、寄存器读等多个操作,但是 cmpxchg 的执行流程不会被时间片轮转所打算,从开头到结尾一鼓作气执行完毕,也是数据安全的原子操作。
cmpxchg 原子操作很重要,是 CAS 无锁的底层实现。下面锁的篇章会再次说到。
原子操作阐述
当一个任务不会被时间片轮转后中途暂停执行,那么这个任务在单核场景下就是安全的。
其实 CPU 提供的指令集基本都是原子操作的,比如读写内存的 “load xxx” 和 “store xxx”,这些指令在单核下都是安全的。如果我们都写汇编并且实际任务运算都可以通过原子操作完成,那么在单核分时机制下就不会有数据安全问题。但实际上,即使我们都写汇编,但我们真实执行的任务都不是原子操作可以完成的,即我们需要解决的任务需要 N 个原子操作配合才能够完成。只要 >= 2 个原子操作配合的任务流,都有可能在时间片轮转的情况下被中断执行,中断过程中共享数据就有可能被其他任务修改,不在数据安全。
多核 - 高速缓存场景数据安全问题(并行 & 时间片)
在单核心的时候,硬件产生的共享数据安全问题就上面提到的时间片问题,因为并发和中断都会产生时间片轮转,所以可以把单核问题归于并发和中断两个方面。
在多核的时候,问题就一下子变复杂了,不仅仅单核时候的问题一个没少,甚至单核原子操作也不在安全,而且更增加了非常多难以解决的其他问题。多核的硬件问题,就源于两个场景:并行 和 高速缓存。
并行
并发是针对单核 CPU 分时间片执行多个任务来说的,直观来说就是多进程 & 多线程。但是这时 CPU 还是只有一个,即同一时间,只有可能有一个任务在执行。N 核 CPU 就代表着不仅同一时间每一个 CPU 核心保持着时间片乱转 (并发 & 中断) 的操作,而且 N 个 CPU 核心保持着独立同时执行。这种 N 核同时运行即并行。
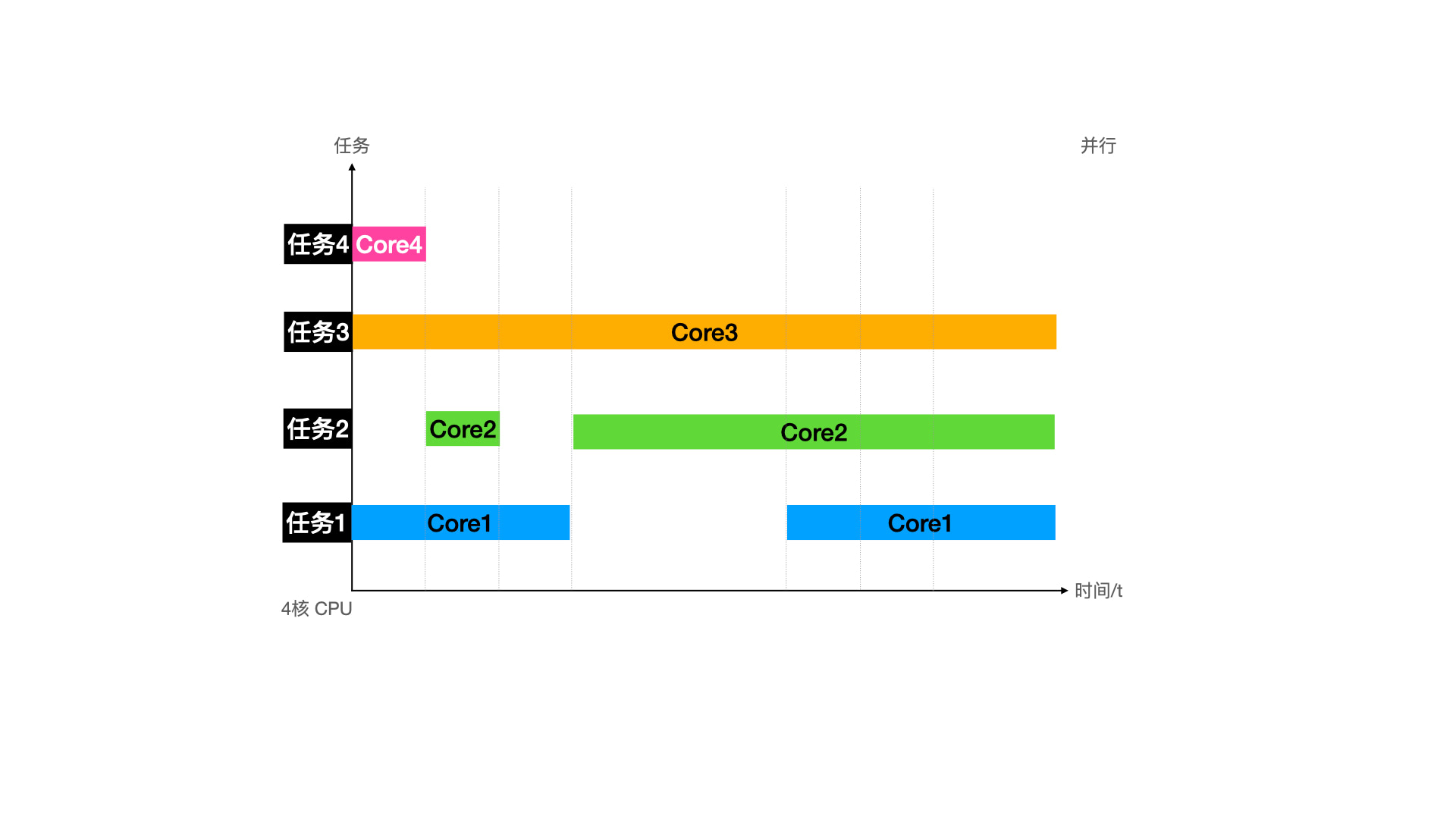
备注一下,并行和时间片乱转没有强相关,没有分时系统的时候,单任务系统依旧可以有多核。并行相比高速缓存来说,还没那么卷,可以先来分析。还是从单核时期的原子操作和非原子操作来说。
非原子操作
1 | int flag = 0; |
非原子操作在单核下因为执行过程被打断,会出现数据紊乱。在并行也是下一样的,只是执行过程被打断的原因不是因为时间片轮转,而是同时操作。
core1 拿到 flag 为 0,core2 拿到 flag 也为 0。两个核心执行完毕后,flag 没有变成 2,而是 1。
和并发 & 中断相比,现象是一样的,原因的本质也是一样的,只是原因的表现有些不同。所以非原子操作在多核下,并发 & 中断 & 并行 一起导致了数据不安全。
原子操作
原子操作在单核下是安全的,但是在多核下原子操作就不在安全了。拿 cmpxchg 举例子来说
1 | // cmpxchg 比较交换指令 |
前面说到 cmpxchg 的执行需要很多个时钟周期,包含内存写、寄存器读等多个操作,但是 cmpxchg 的执行流程不会被时间片轮转所打算,从开头到结尾一鼓作气执行完毕,所以在单核场景下是数据安全的原子操作。
但是在多核场景下,有可能会出现一个 CPU 核心把 “首操作数” 取值完毕,另一个 CPU 核心同时把 lock 内存地址的值给改了。因为 cmpxchg 需要好几个任务流程,需要很多时钟周期,很难说执行过程中会不会有另一个 CPU 也对共享内存值做了其他的操作。这时候就有可能出现 ax 寄存器值和 “首操作数” 开始的时候不一样,cx 被赋值到 ax 寄存器。可是指令执行结束后,发现 lock 内存地址的值和当时 cx 寄存器值却是一样的,这就产生了问题。所以 cmpxchg 没有死于 时间片轮转,却死在了并行上。
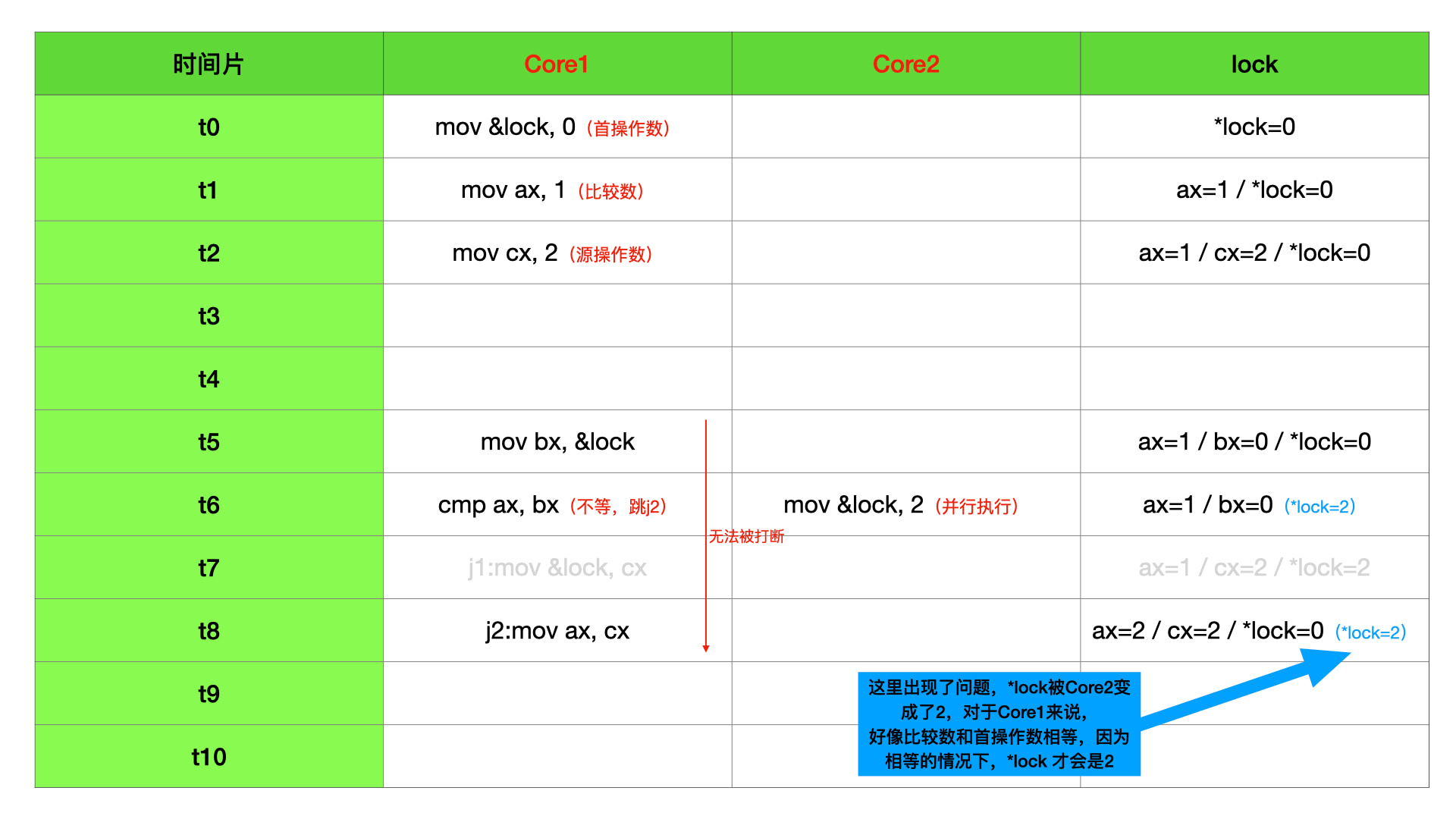
这种打时间差插边球的操作会使得最终的数据不符合任务流程的预期,所以上面提到的 addl、xchg、cmpxchg 在多核下都不是数据安全的。
高速缓存
高速缓存对数据完整性简直就是摧枯拉朽的摧残。为了应对各个信息存储器件之间的速度不一致,高速缓存的存在是必要的。在 CPU 和内存之间加入高速缓存,通过对程序局部性原理的评估,可以有效增加缓存命中率,即 CPU 绝大部分时间都不用和内存打招呼,只要从高速缓存里面读取和写入相关数据即可。这可以极大的提高 CPU 的生产力。下面先分析一下单核时期的高速缓存以及它的重要意义。
高速缓存存在的意义是为了弥补各类存储器件之间速度的巨大差异性。如下图所示,容量越大,造价越低,速度越慢。
我们最常见的是网络资源,浏览器无时无刻不在使用网络资源,存储大小接近无限。其次常见的是本地磁盘,一般 250G-2T 的都有。常见的内存一般只有 1G-16G,容量远远小于本地磁盘。而容量更小的寄存器和 L1/L2/L3 高速缓存基本就见不到了,他们被封装在了芯片中。L3 能达到 32M,L2 能达到 256kb,L1 能达到 16kb,寄存器甚至只能有 1-8 个字节大小。
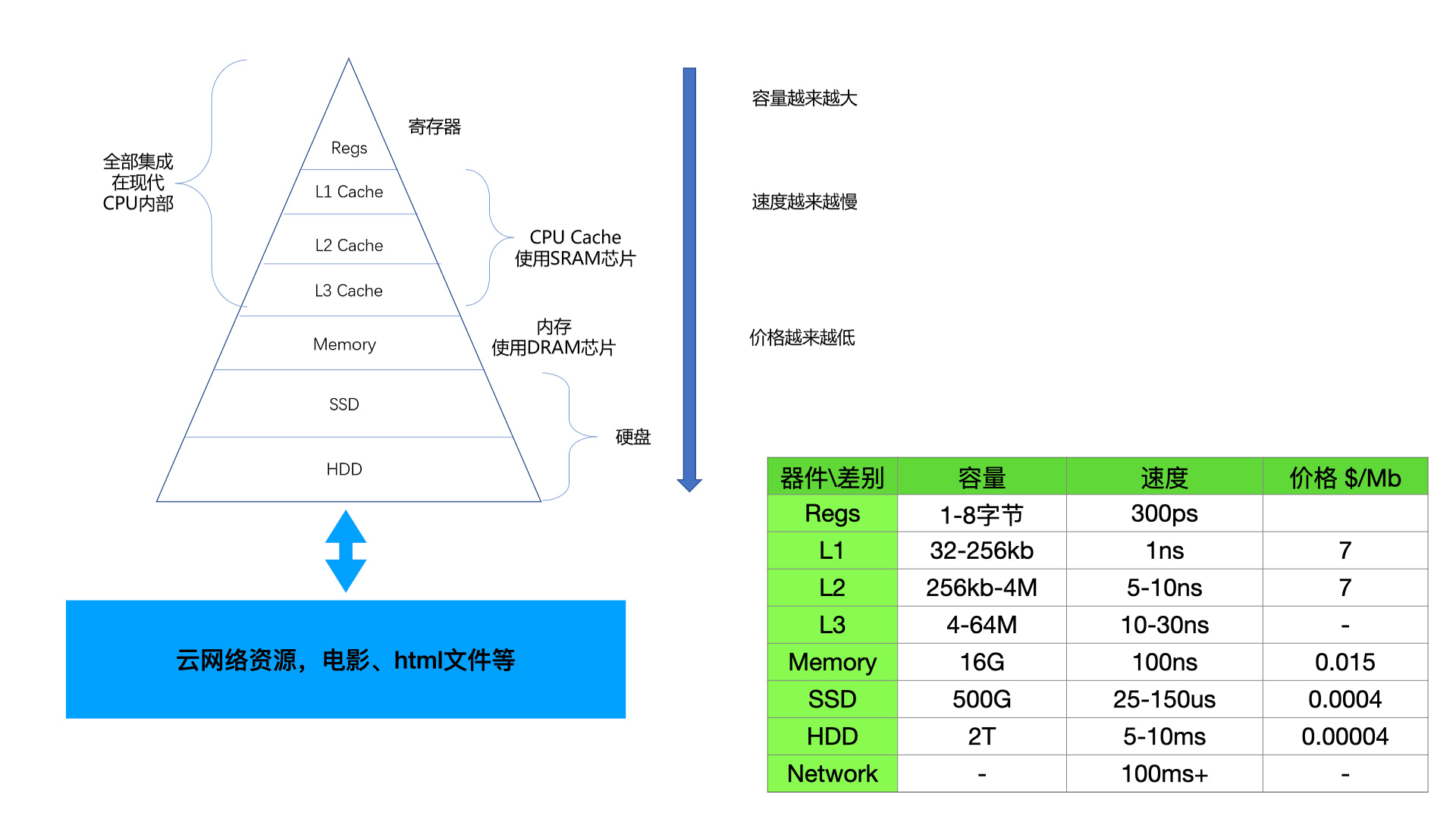
CPU 由晶振驱动,晶振的周期越快,CPU 跑的也就越快。虽然因为散热问题,CPU 的速度近十年没有提升了,但依旧达到了 4GHZ,大约每秒可以跑 40 亿次时钟周期,如果是简单指令,每秒可以执行 40 亿次。但是内存的速度在 50-100ns 之间,即每秒最多只有 2 千万次读取,这之间的速度鸿沟就使得 CPU 一直处于空等状态。所以银弹就是高速缓存,没有中间层解决不了的事情,基于时间和空间局部性原理,只要缓存的命中率达到预期,那么 CPU 就可以不和内存打交道,转而和高速缓存进行通信。目前高速缓存的命中率能达到 90%,可以说极大的提高了生产力。
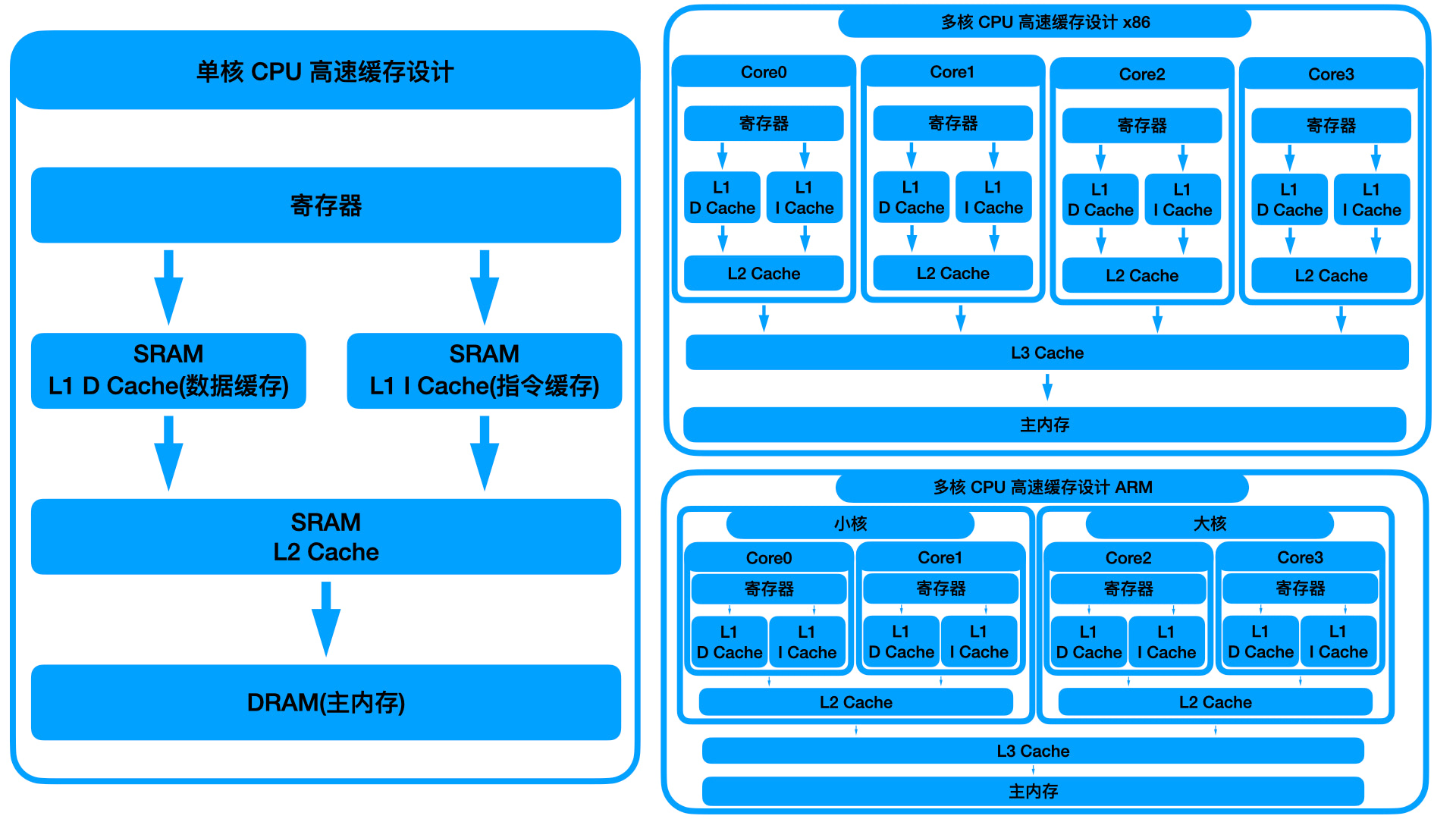
对于 PC 机系列,一般是每个 CPU 核心有自己的 L1 和 L2 高速缓存,多核心共用 L3 高速缓存。对于手机系列,一般 CPU 核心分大小核簇,每个核心有自己的 L1 高速缓存,每个核簇有自己的 L 2 高速缓存,所有核心共有 L 3 高速缓存。对于手机系列,这样设计可以使的大小核簇之间更好的切换,能够更省电,在待机等状态下,可以仅运行小核心,大核心完全处于空转睡眠状态。
补刀 - 高速缓存为什么高效
下面举两个例子来说有了高速缓存后在单核场景下数据操作流程以及它们是如何使用 “时间局部性” 和 “空间局部性” 的:
1 | // 例子 1 |
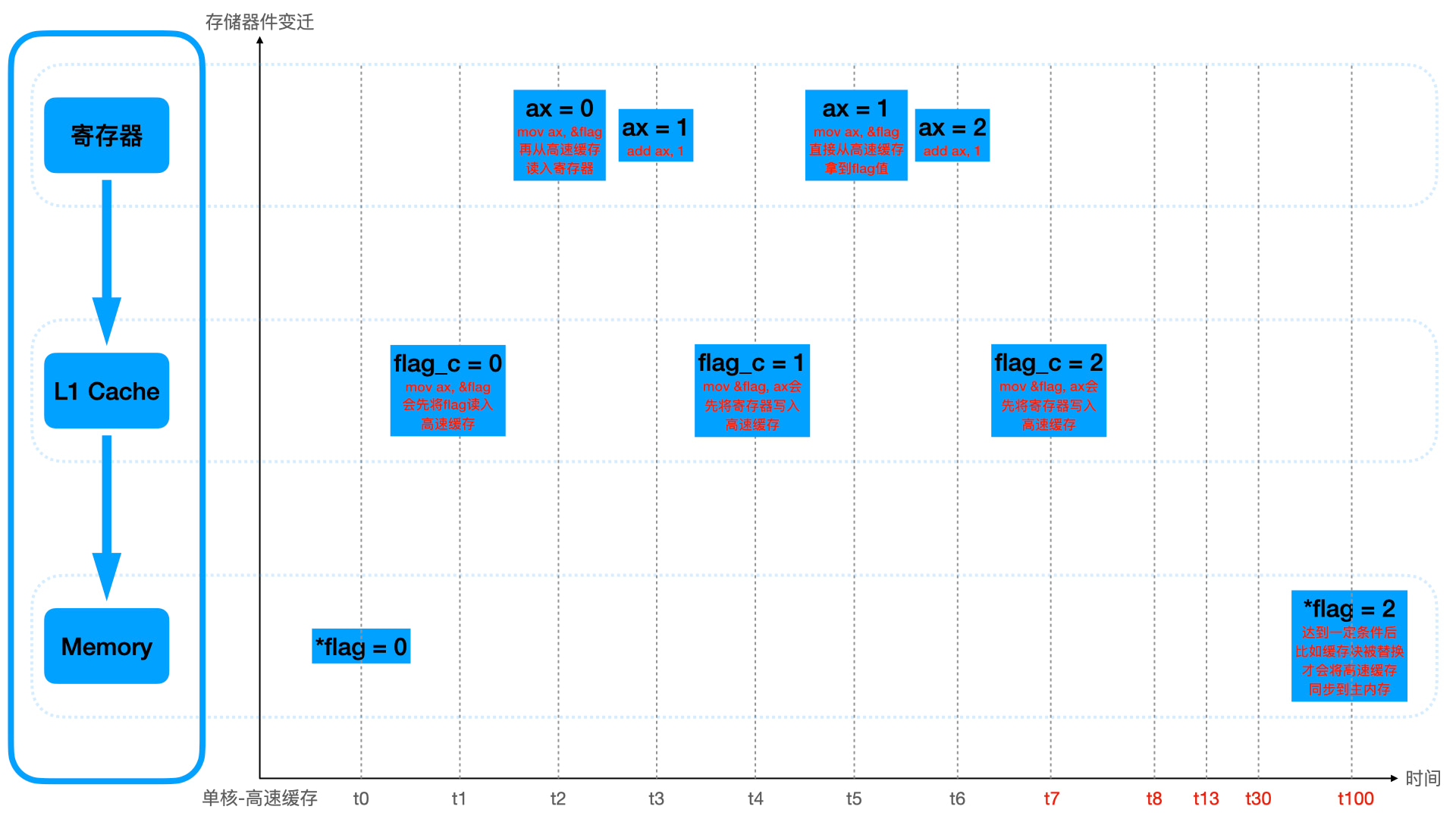
上面采用的是 “写回” 的工作方式,即高速缓存的数据变化后,不会立即同步到主内存中。只有在一定时机触发了,比如缓存块需要被替换的时候,才会将缓存写入主内存。
除了 “写回” 的方式,还有一种是 “写直达”。即高速缓存中的数据变化后,会理解写入主内存。但这种效率很低,一般都不用。
上面的例子是 “时间局部性” 的体现,因为 flag 会被短期内多次使用运算,所以寄存器会从高速缓存多次取值。
1 | // 例子 2 |
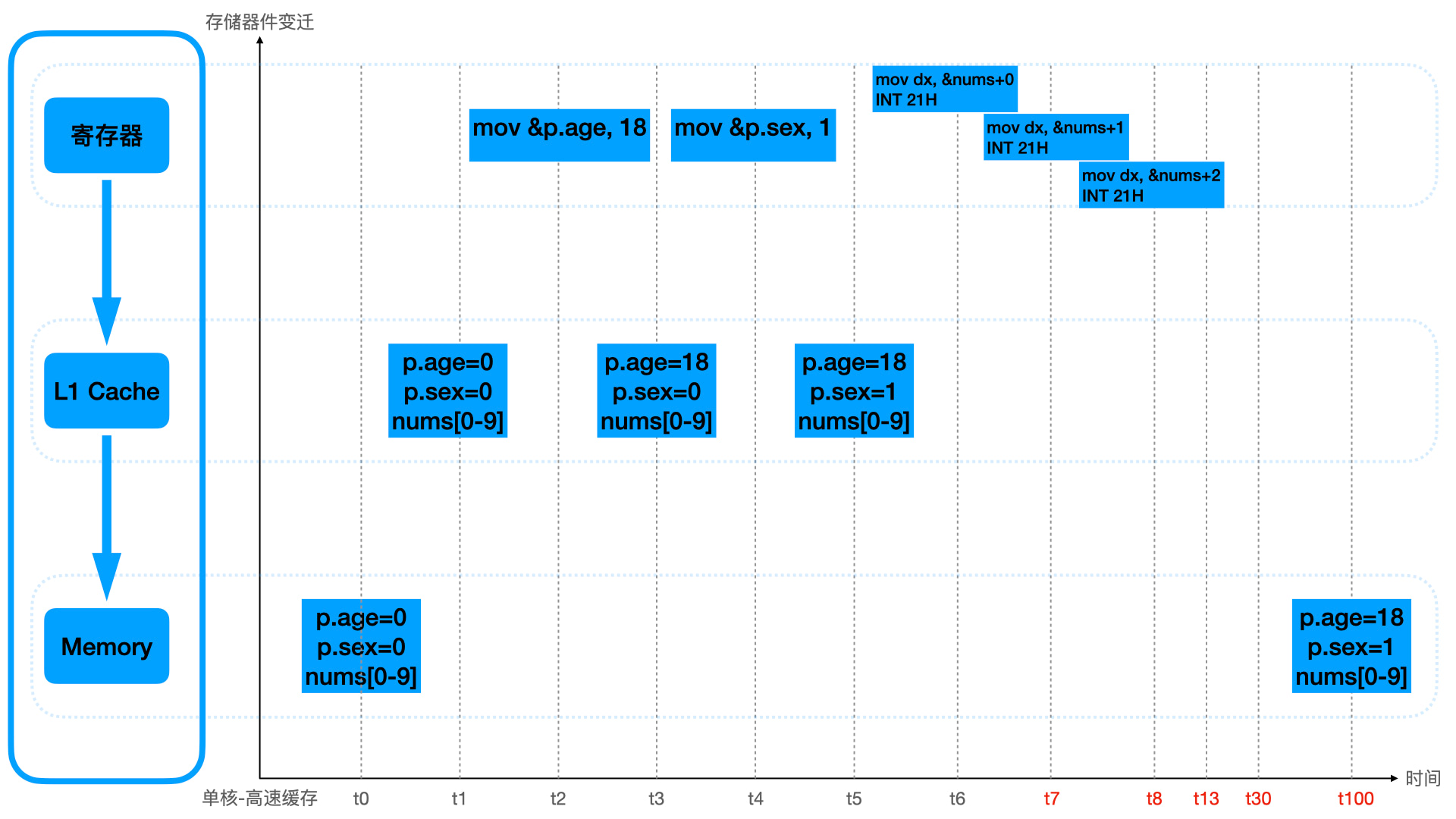
上面的例子是 “空间局部性” 的体现,因为 Person 结构体和 nums 数组的内存是连续的,CPU 在取值的时候,并不会一次只取需要的大小到高速缓存,而是一次取批量数据。上面的 Person 的 age 和 sex 就会一次性读入高速缓存,而 nums 里面的 10 个数字也会一并读入。这样在读取 age 完毕后,就不需要重新将 sex 从内存读入高速缓存之后再读取,而是可以从高速缓存直接读,nums 的第 0 位使用完毕后,可以直接使用第 1-9 位,也不需要再次从内存读。
所以高速缓存是从硬件层面极大的提高了程序的运行速度,甚至软件上为了适应高速缓存,还会做内存对齐为了能够一并读入高速缓存。
可见性
上面介绍了高速缓存的作用,下面分析高速缓存下共享数据安全性问题。上一趴说单核的时候,都没有说高速缓存。是因为单核下高速缓存对数据安全是没有影响的,这时候高速缓存有效的提高了生产力,但是到了多核后,高速缓存会产生严重的缓存一致性问题,也就是可见性。
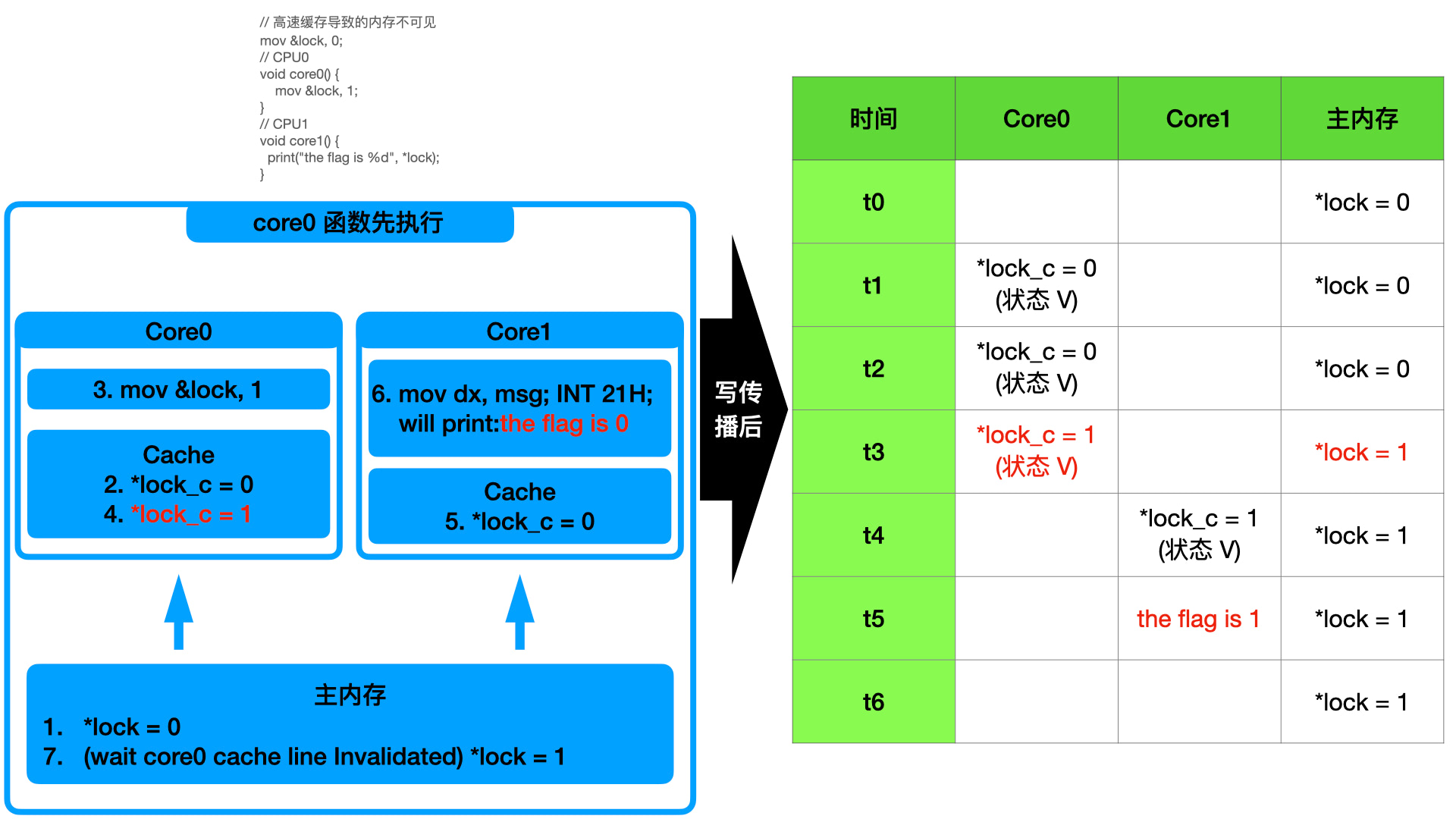
1 | // 高速缓存导致的内存不可见 |
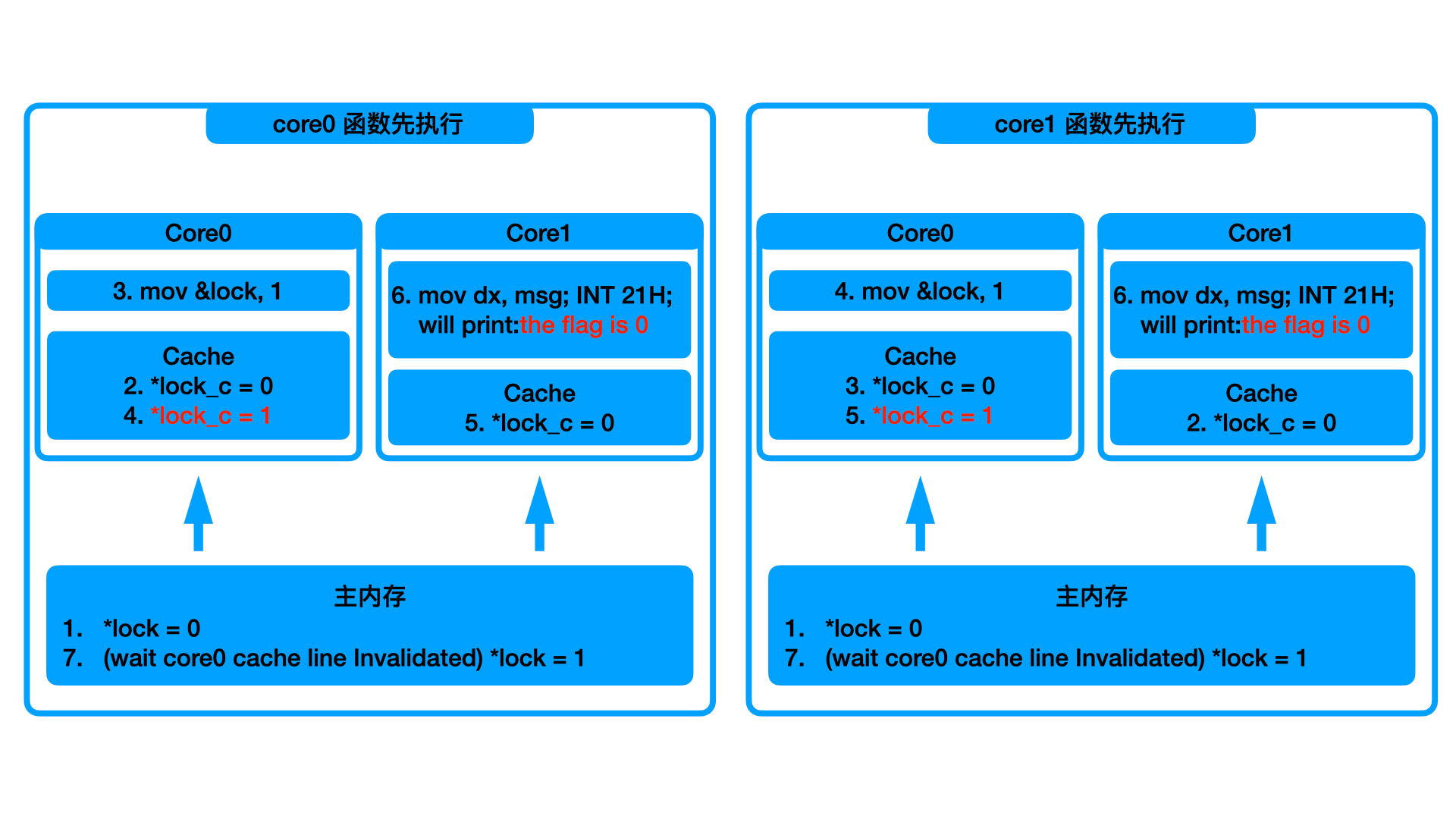
如上图分析的流程,当 CPU0 将 lock 读取到高速缓存并且将值由 0 置为 1 后,CPU1 打印 lock 的值,依旧为 0。这就是可见性导致的共享数据不安全,即一个核心的缓存数据对另一个核心不可见。
上面只是非常常见的一个例子,我们一直都在使用多核 CPU,在写多线程代码的时候上面的共享数据的场景会经常出现。因为多个线程中,很可能是由多个核心分别执行的。由此可见,在高速缓存的情况下,数据也不再安全。
上面例子非常简单常见,很容器会出现问题。因为容易发生,所以灾难非常大。实际上为了解决这个问题,可是耗费了太多太多的精力,下文可见性解决方案中会讨论。
但是这里要特别说明一点,即上一趴说单核的时候没有说高速缓存的影响,实际上高速缓存只会产生多核场景下的缓存不可见。在单核情况下,因为只有一个核心,所有任务都只使用同样的 L1 和 L2 缓存,不会出现可见性问题。即上面的例子如何在单核下执行,最终打印的 flag 值是多少,完全取决于两个函数哪个先执行。
CPU 乱序场景数据安全问题
也许可以用 “智商不够,努力来凑” 吧,当初冯诺依曼和图灵搞出来的计算机原型,就一直在修修补补的路上,一修补就是几十年。也许这就是计算机的最优解,也许并不是。那个时候啥都是起步,如果从这一刻起有机会翻头重来,我认为科学家们是能够弄出更高效的计算机原型的。但是随着商业化的车轮滚滚向前,就连 x86 指令集都只能不断的兼容无法完全翻身,所以这样的机会肯定是没有的。
CPU 的摩尔定律十几年前就已经失效。虽然这些年还是在不断进步,但都是另辟蹊径。晶振的频率完全可以提高,但目前的 CPU 撑不住更高的频率了。奔腾 4 当年朝着 10GHZ 进军,随着过深的流水线设计,不仅没能提升指令吞吐率,更导致了过大的散热问题,最终退出 10GHZ 的研发赛道,后面各类 CPU 主频只能在 4GHZ 停滞不前。摩尔定律之所以还在正常跑,就是因为从 CPU 硬件层面修修补补了一大堆不可思议的骚操作。
CPU 乱序这一趴,我主要参考了徐文浩老师的《深入浅出计算机组成原理》,因为他写的是在太好了,配图也浅显易懂,我就直接拿图,大家也能看的明白。
这里呢,郑重的提前说明一下,CPU 乱序,不会产生有序性问题。不管你相不相信,但就是不会产生。
如果你明了,这一趴可以不用看。如果你不明了,这一趴一定要看看。因为我查阅资料的过程中,太多太多的同学把 CPU 乱序做为 “有序性” 不能保障,从而做为共享数据不安全的依据。我们不求知识多,但一定要求知识准确。
单指令周期处理器 => 流水线设计
CPU 乱序产生的原因就是 CPU 为了不断的提高运行效率,好追上摩尔定律的速度,在流水线设计基础上不断加骚操作导致的。这里先说明一下什么是流水线设计。
在开荒初期,对于每个指令的执行是串行的。每个指令需要的时钟周期数量不等,最少也是一个时钟周期用于取指。而时钟周期可以由晶振控制,即时钟周期可长可短。
如果有 100 个指令需要执行,所以我们就希望这 100 个指令的总时钟周期和每个时钟周期耗时足够小,这样就可以提高程序的执行效率。
前面说了每个指令最少需要一个时钟周期用于取值,如果没有更多运算,那么这个指令最少需要一个时钟周期。所以如果我们能控制 100 个指令的总时钟周期为 100,即最少时钟周期数,那么每个时钟周期越小,执行效率也就越高。
但是现在就遇到一个问题,发现这个时钟周期可以小,但是小的度量却没法确定,即如何才算小。如下图:
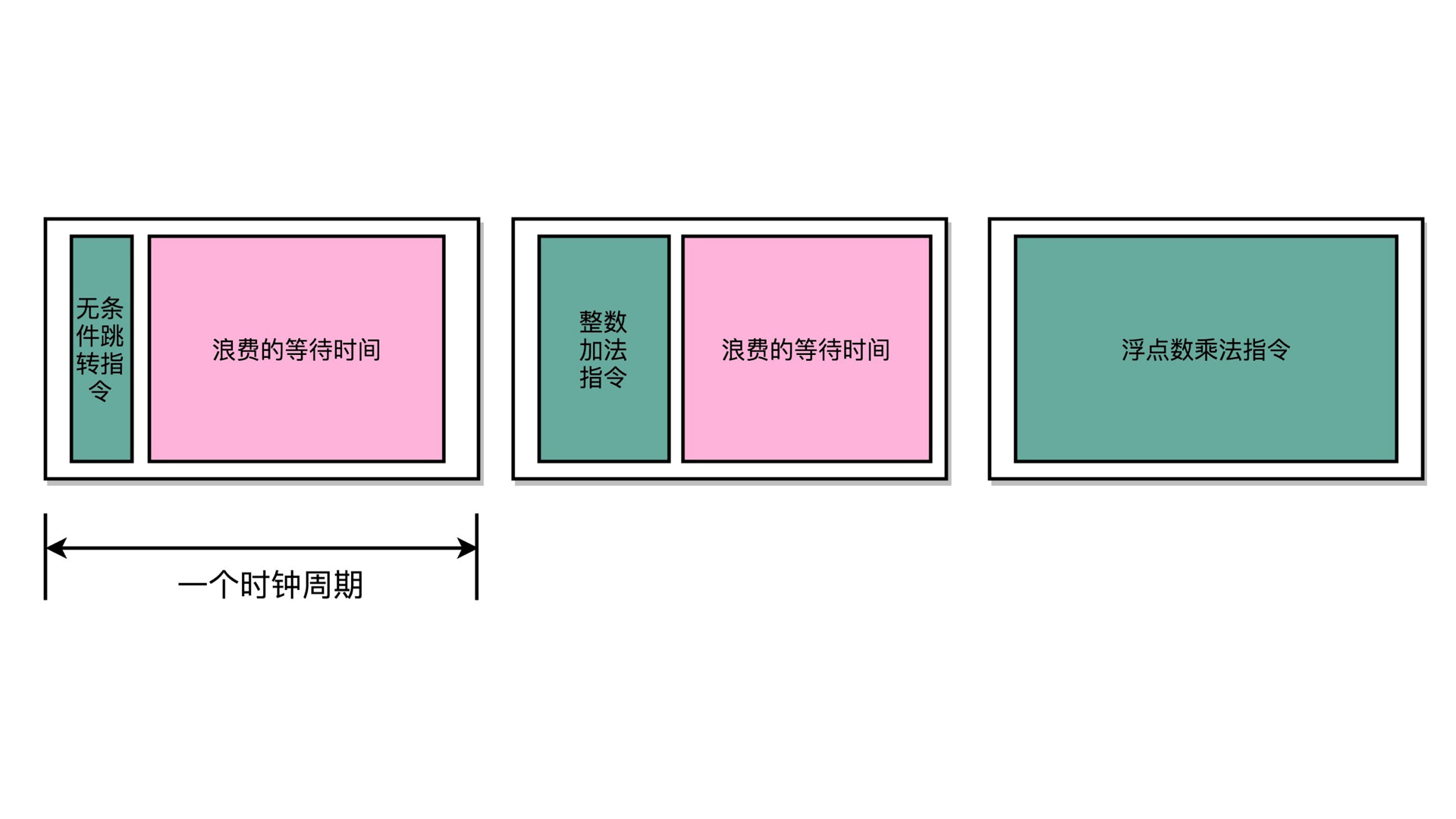
有些指令非常简单,很快就可以完全。有些指令则比较复杂,需要更长的时间才能执行完成。这里我们就只能根据木桶理论,使用那个更长的时间做为时钟周期。如下图所示,但凡时间短一些,就会导致某个执行没有执行完成,会导致异常。而使用更长的时间做为时钟周期,一来短时间能够执行完毕的指令则 CPU 需要空等,再者多长的时间才够长呢?这好像不是一个好的解决方案。
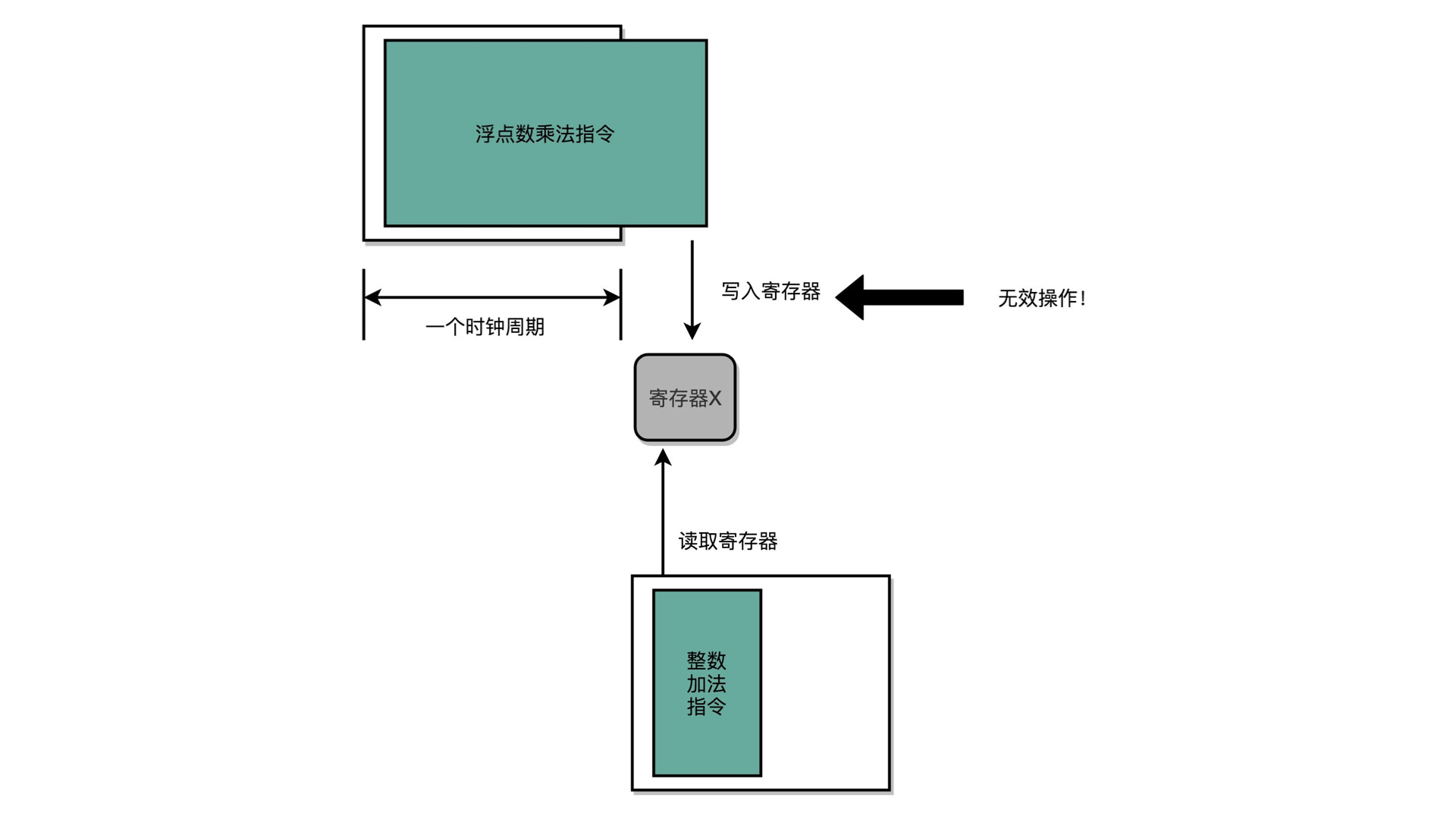
上面说的就是单指令周期处理器,在开荒初期,可以这么用。那时候指令还非常少,业务的复杂性也不是很高。后期就全部推向流水线的设计了。
因为每个指令最少需要一个取指的时钟周期,那么复杂指令也就需要更多的时钟周期。上面说的 100 个指令的执行效率上,就不在考虑总时钟周期数,而是考虑每个时钟周期耗时如何足够小。
一个指令的执行周期,可以分为取指、译码、执行三个阶段。这样我们就可以用三个阶段里面的最大耗时做为时钟周期,这个时钟周期肯定比上面 “但指令周期处理器” 时候要小得多。这里执行阶段最为耗时,因为有 ALU 运算、数据写回等操作,那么把执行阶段进一步细分为指令执行、内存访问、数据写回,就把一个指令的执行周期分为了 5 个阶段,这 5 个阶段里面的最大耗时肯定比刚才 3 个阶段的最大耗时低,相应的时钟周期又会低很多。
我们这里先分成 5 个阶段来考虑。虽然分成 5 个阶段,时钟周期比 “单指令周期处理器” 耗时低了很多,但 “总时钟周期” 也变多了,所以整个程序的执行效率或许并没有优化多少。或许参考了福特汽车的流水线工艺,发现可以用在 CPU 指令执行设计上,科学家们就又弄出了 “流水线” 设计来分摊 “总时钟周期” 的增多量。如下图所示:
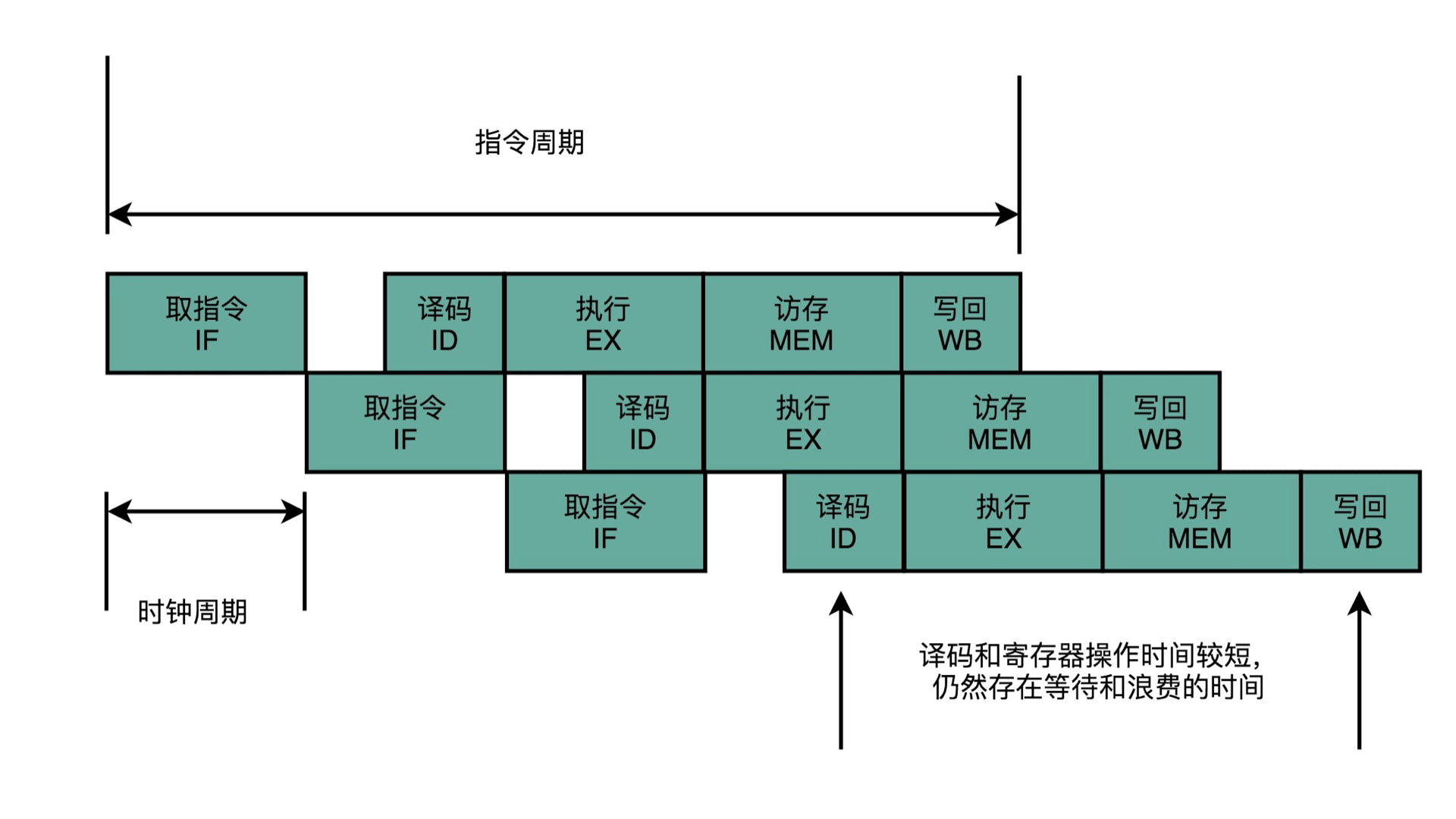
因为同一时间只能进行一次取指,也只能进行一次译码,也只能进行一次地址总线的访问进行内存读取。所以科学家们设计了上图的指令执行流程,即取指电路把上一个指令的取指操作完成后,立刻进行下一个指令的取指,因为有时钟周期做为每个执行阶段的校准,所以下一条指令的每个执行阶段相比上一个指令都延后一个时钟周期。那么,在指令的最终执行过程中,就会出现 5 条流水线一同执行的场景,如下图所示:
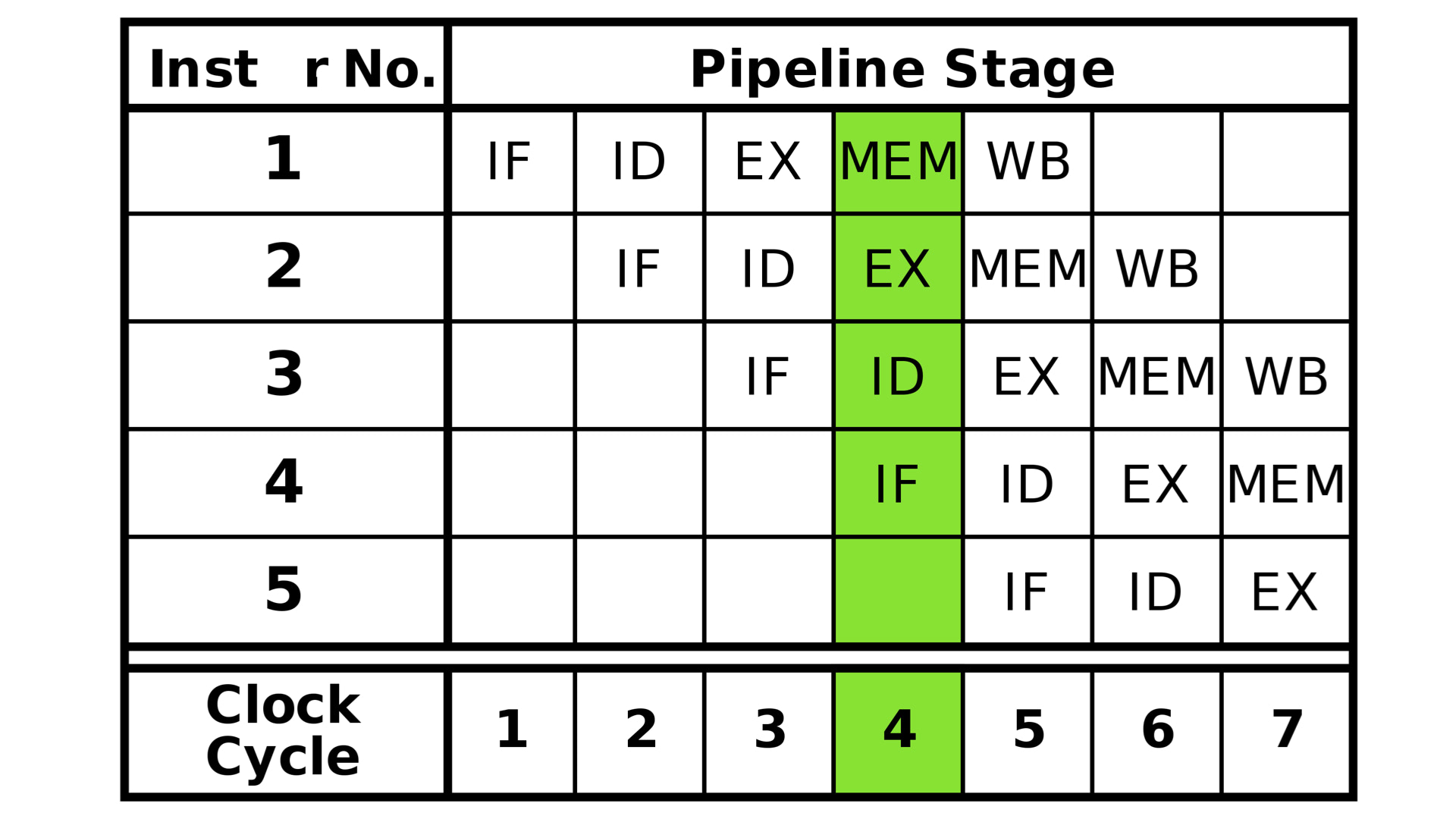
即在第 5 个时钟周期之后,同一时间实际上有 5 个指令在并发执行。这样通过并发的方式的确可以有效的平摊 “总时钟周期” 的增量。而且,如果觉得 5 个阶段还是分的太少,那么可以将一个指令分成 10 个阶段,这样每个时钟周期的耗时会进一步降低,而且会产生 10 个指令的并发执行。
这里将每个指令分成 5 个阶段或者 10 个阶段,其实就是 5 级流水线和 10 级流水线。现在一般能做到 14 级流水线深度。但也不是越深越好,奔腾 4 曾经希望做到 31 级,但是因为流水线本身需要处理很多复杂性,导致 CPU 的设计越发复杂,而且复杂过后发现效率并没有提升,反而增加了十分严重的耗电。
这里的复杂性就是下面要说到的冒险和预测。其实单纯的流水线并不会乱序执行,因为每条指令的执行阶段,都比上一个阶段晚一个时钟周期,这样步步紧逼的扣环操作,使的上一个执行的执行结果对于下一个指令的执行过程完全可见,所以就和串行执行是一样的。
但是为了更快更强,冒险和预测就登上了历史舞台,使的不同指令的每个阶段的执行过程完全是乱序的,即 A 指令的内存写回或许还没执行,下一条 B 指令就已经拿到 A 指令的执行结果开始参与 ALU 运算了。
乱序也有一个乱的保障,即保障单线程场景下的数据准确性。
冒险 - 结构
冒险总共有结构冒险、数据冒险和控制冒险。这里先说结构冒险,如下图所示:
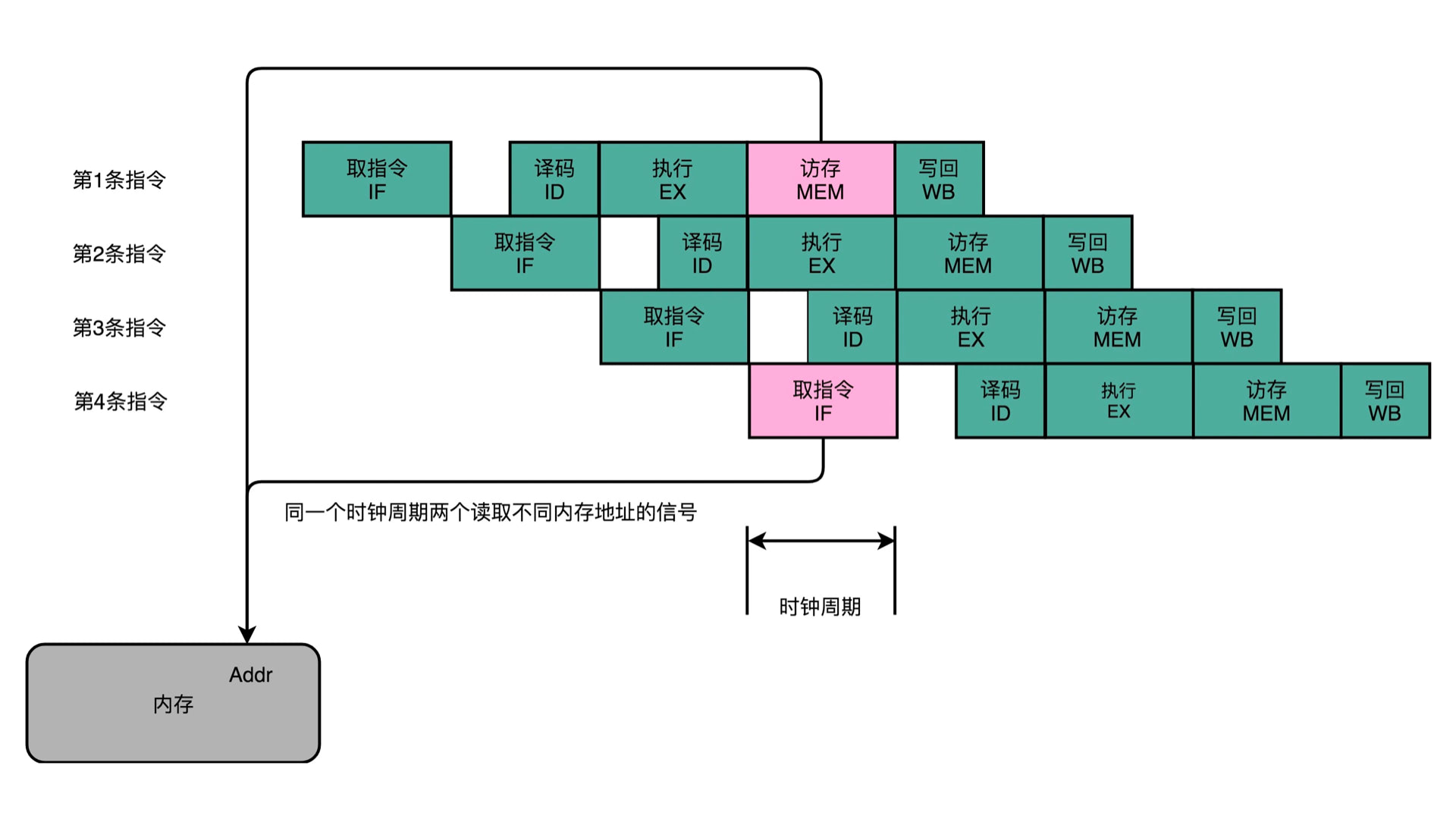
同一时间,CPU 无法同时操作地址总线对内存做读取两个操作,这里会有冲突,一个是读之令,一个是写数据。
当初设计计算机原型的时候,对于内存里面指令和数据的存放,有两个意见。一个是哈弗架构,即数据和指令分别存放在两个内存里面,这样就会有两条内存总线,可以同时支持读取。但是冯诺依曼架构没有采取这种方案,使的数据和指令是一起存放到同一块内存里面,这就使的上面的结构冒险不可避免。
不过呢,不过。上面在写高速缓存的时候,大家有没发现对于 L1 Cache,有两个,一个是 L1 D Cache,一个是 L1 I Cache。其实 L1 Cache 是使用了哈弗架构,即数据和指令分别存放。而因为 CPU 和内存之间难以逾越的速度鸿沟,使的目前 CPU 都是直接操作 L1 缓存的,所以这就使的指令和数据是可以同时读取的。虽然这样婉转的解决了上面的结构冒险问题,但也实属瞎猫碰到死耗子,赚了。
冒险 - 数据
数据冒险就是数据依赖问题,如下:
1 | // 场景1 |
前面我们说了,乱序也有一个乱的保障,即保障单线程场景下的数据准确性。
所以场景 1 中,指令 3/4 必须等待指令 1 写入完成。场景 2 中,指令 2 必须等待指令 1 写入完成。场景 3 中,指令 3 依赖指令 2,指令 2 又依赖 指令 1。
前面说了多级流水线,上一个指令取指完毕,下一个指令就开始取值了。很有可能会出现有一个指令的 ALU 执行完毕,还没有写入高速缓存或者内存,下一个指令的 ALU 就已经开始执行了。这个时候就会出现上面的依赖问题,比如场景 1,如果指令 1 的高速缓存操作还没有完成,即高速缓存里面 a 还是 0,还不是 1,这个时候指令 3 开始进行 ALU 运算了,那么拿到的 a 就是 0,计算结果就是 a = 2。这显然不符合单线程场景下的数据准确性了。
为了解决这个问题,就提出了插入无效指令即 NOP 停顿的解决方案,如下图所示:
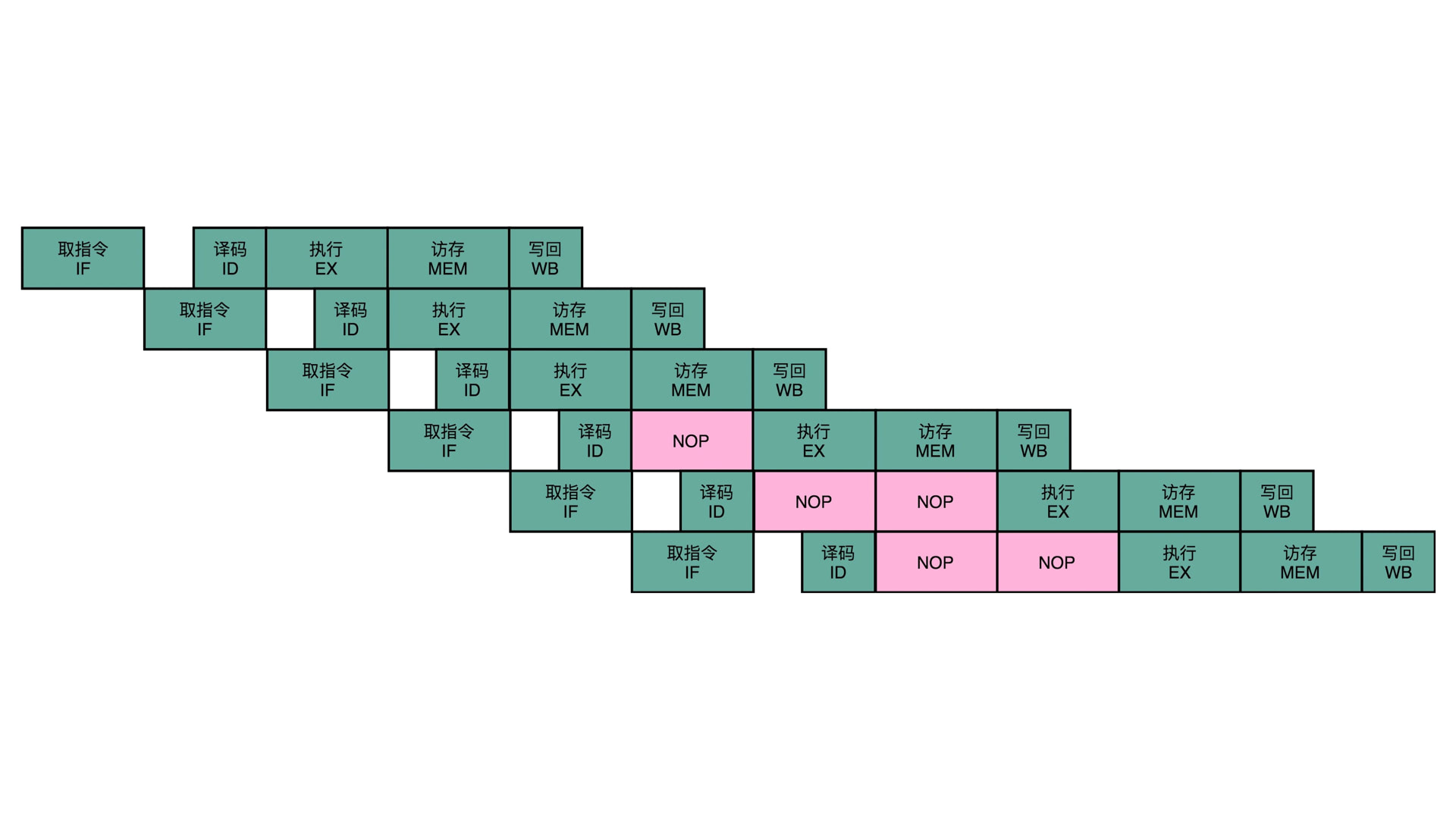
可以看到,就是单纯的让该指令的某个阶段无操作,空等。等上一个指令的某个操作必须完成,才开始继续执行。比如刚才说的场景 1,指令 3 就是要等到指令 1 的写高速缓存执行完成后,才能继续执行,否则就会出错。
其实上面说到的结构冒险,虽然 L1 高速缓存解决了内存同时读取的问题,但是如果同时写回到主内存,也一样会冲突。在上面高速缓存的图解里,大家可以看到 L3 高速缓存的数据可以写入主内存。如果两个指令要同时执行这个操作,还是会冲突。解决方案也和这里一样,把某个指令加入一个 NOP 停顿,空等上一个指令写入完毕,下一个指令再写入。
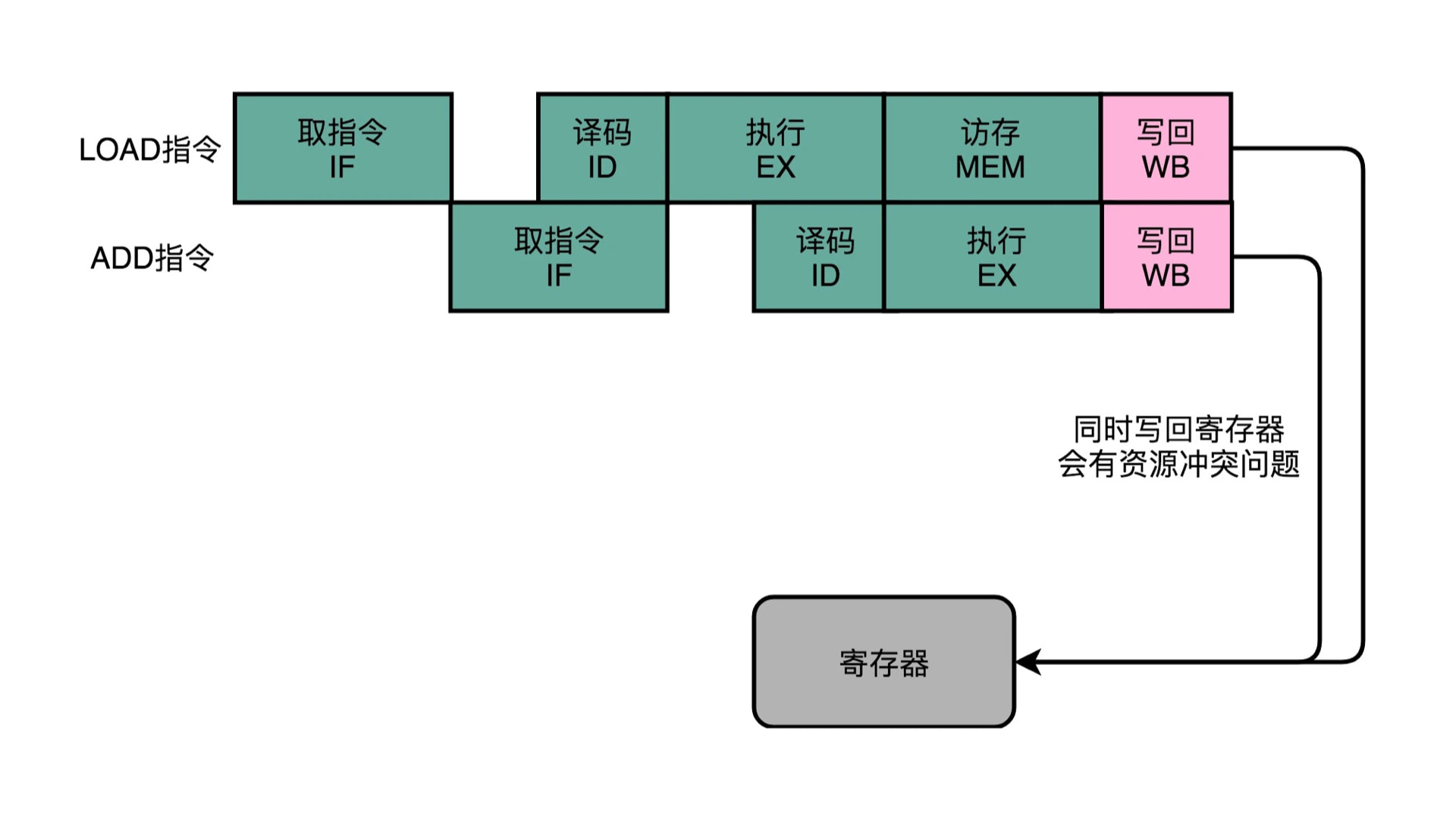
但是增加 NOP 停顿的方案,其实就是最省事和低效的方案,不仅没有提效,还让 CPU 空转降低了性能。所以呢,就出现了乱七八糟的其他解决方案,如操作数前推:
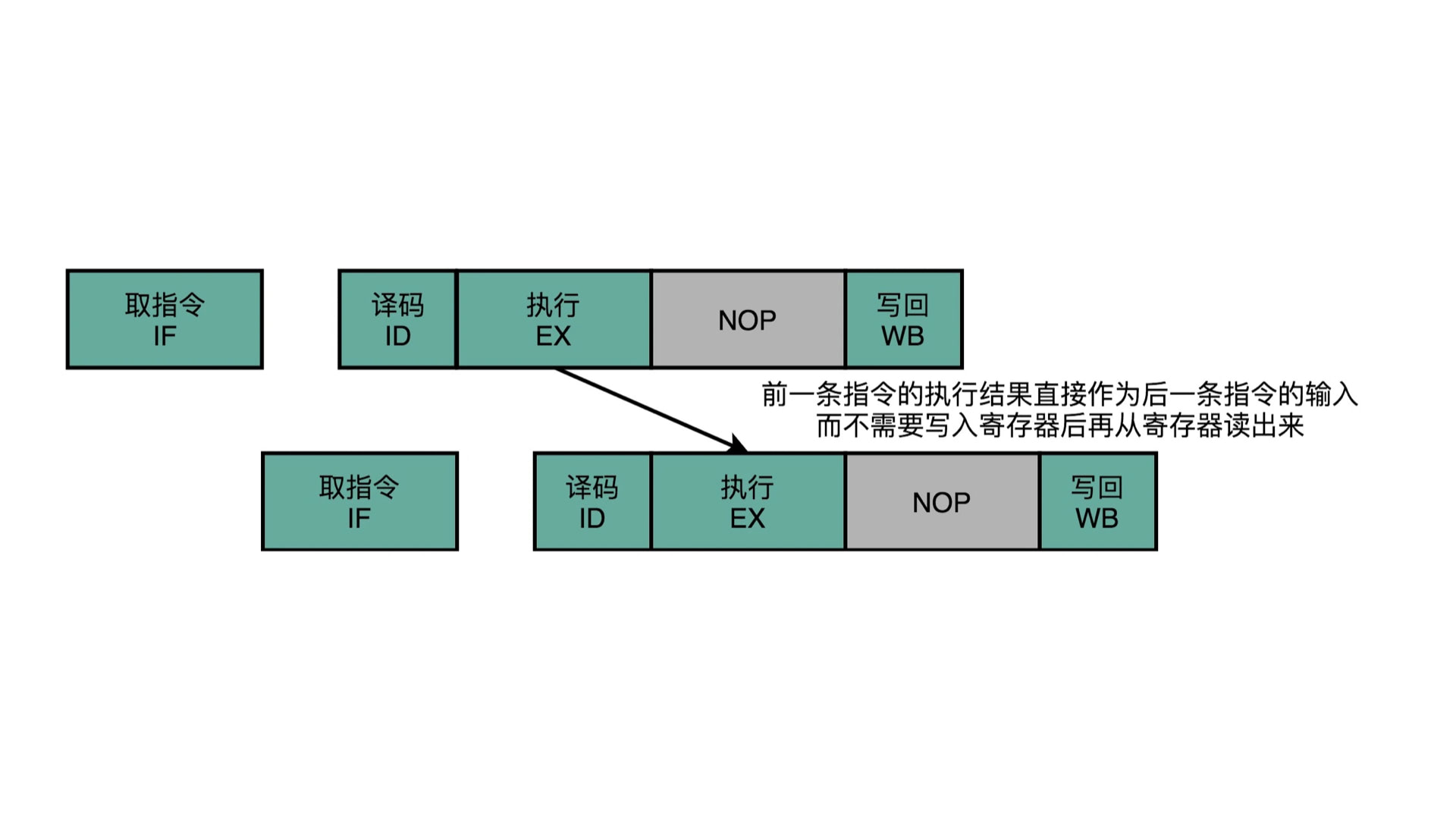
在代码的场景 1 中,指令 3 依赖 指令 1 将 a 的值写入高速缓存才能读取并执行。那么就不等指令 1 的写入了,直接把指令 1 产生的值,通过流水线寄存器直接给到指令 3,指令 3 拿到了同样的数据,直接开干(真 TM 是鬼才)。这种方案叫 “操作数前推”,字面意思,也好理解。
但是 “操作数前推” 也不是都能解决问题,比如下面这个:
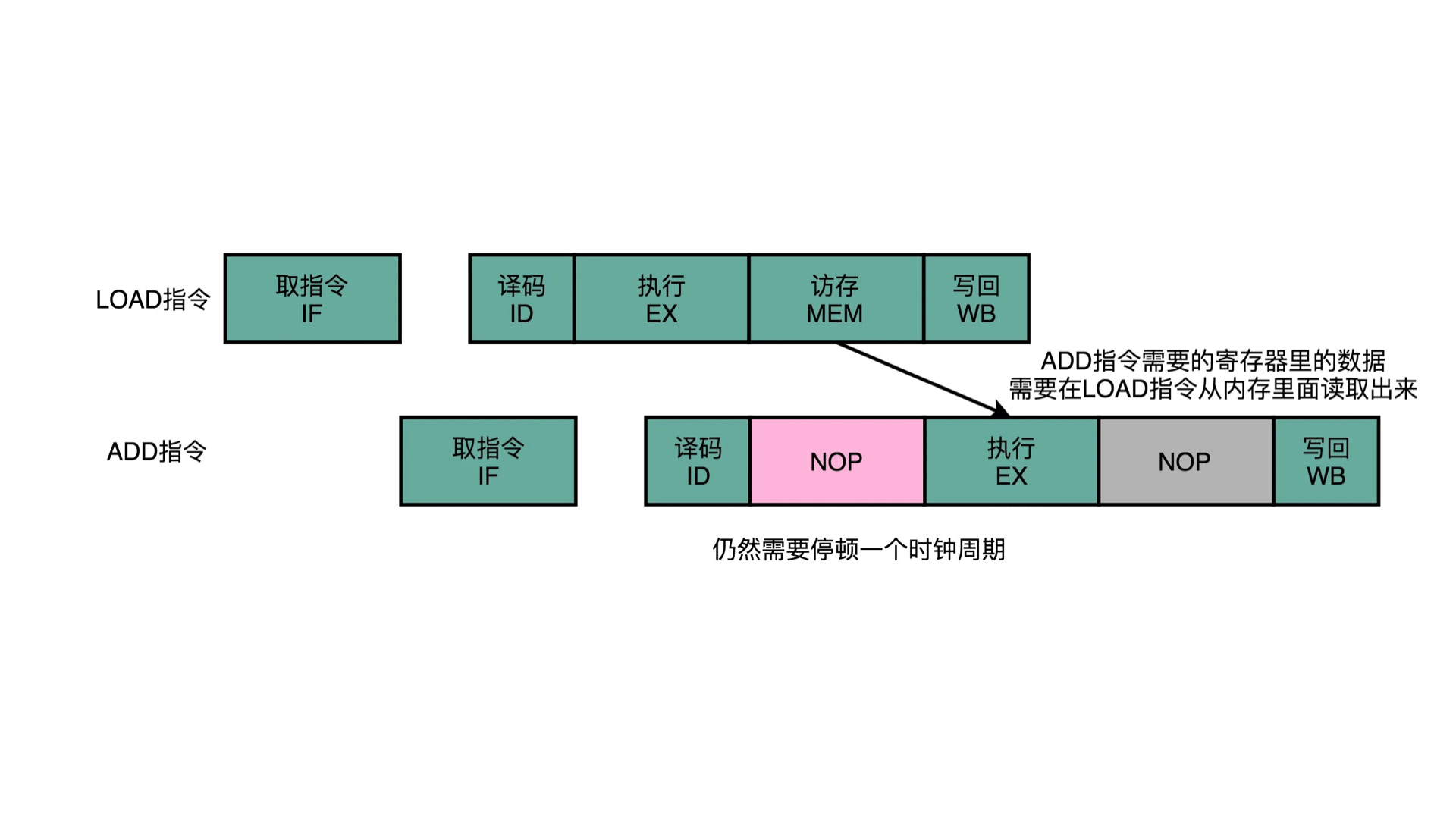
代码是这样的:
1 | load ax, &flag; |
这里 add 指令的 ALU 执行阶段,必须要 ax 寄存器里面的值。但是 load 指令必须要执行读取高速缓存的操作后,才能拿到 ax 的值。这里,操作数无法前推了,只能再次加入 NOP 停顿来解决。
科学家们总是不愿意停止脚步,想要榨干 CPU 最后一丝气息。科学家们怎么也想不到,他们耗费那么多的精力让 CPU 越发高效的结果,就是使得许多人只是用了 CPU 0.1% 的能力不断的刷抖音。
1 |
|
科学家们发现 NOP 停顿有时候也在所难免,还能不能更高效?上面场景 4 的代码,就发现虽然有依赖,但是指令 1、3、7 是可以提前执行的。其他的指令对 1、3、7 有依赖的,那么能前推就前推,要加 NOP 的就加 NOP。所以呢,丧心病狂啊:
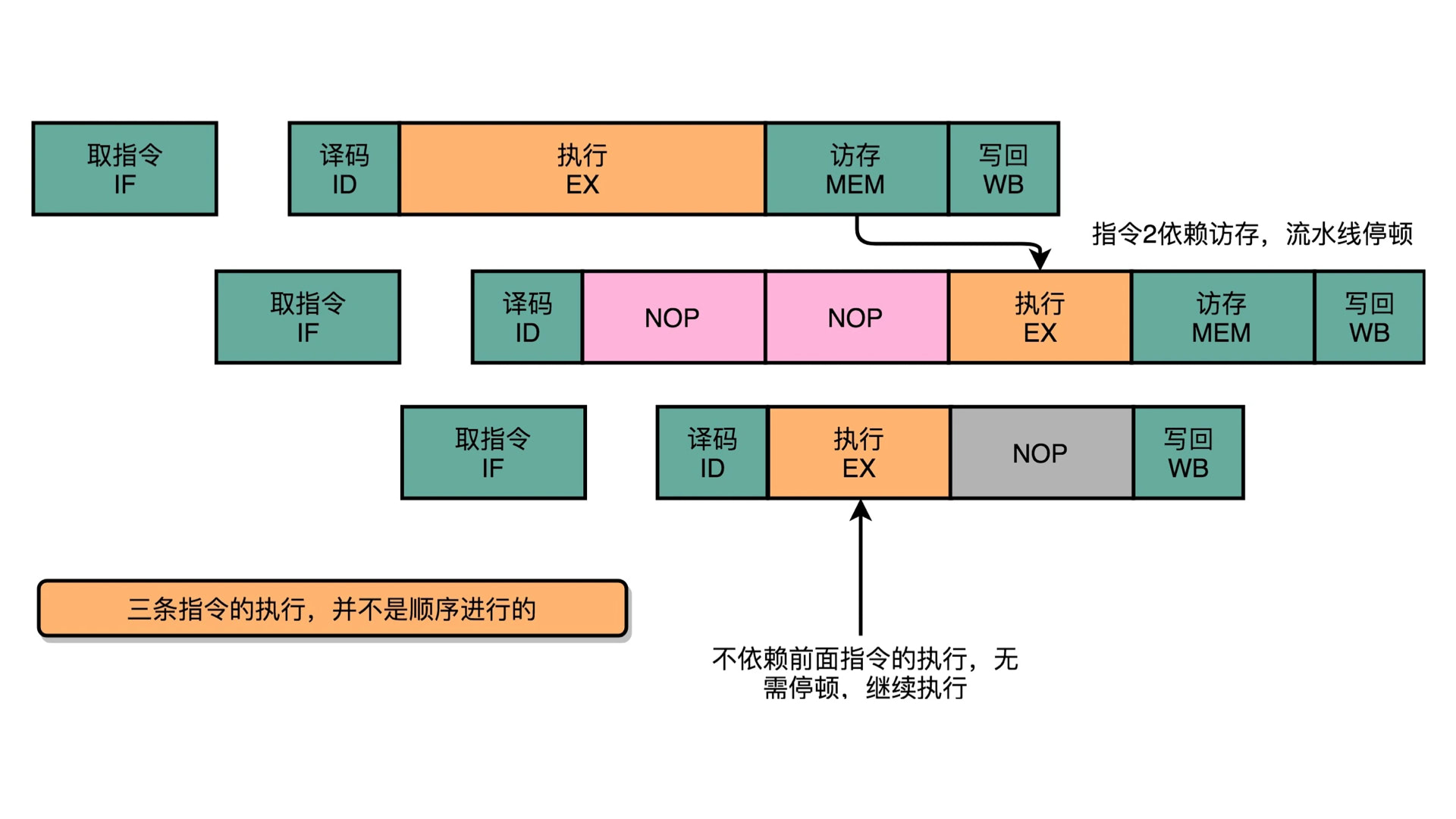
我们写好的手动排序的代码,直接给乱序执行了。即指令 2、3、5、6、8、9 还没有执行完,指令 1、3、7 就已经执行完了。所以我们可能会发现,在多核场景下,尤其高速缓存那一趴说到的,这时候肯定共享数据不安全了。比如场景 4 如果在 Core0 里面执行,那么 Core1 看到的 b 还没有计算出来,x 和 o 就已经能够取值了。这显然会导致共享数据不一致。真实情况真的是这样吗?
CPU 乱序不会导致共享数据不一致!
上面的数据冒险,即 CPU 乱序。其实这里 CPU 做了一个保障,如下图所示:
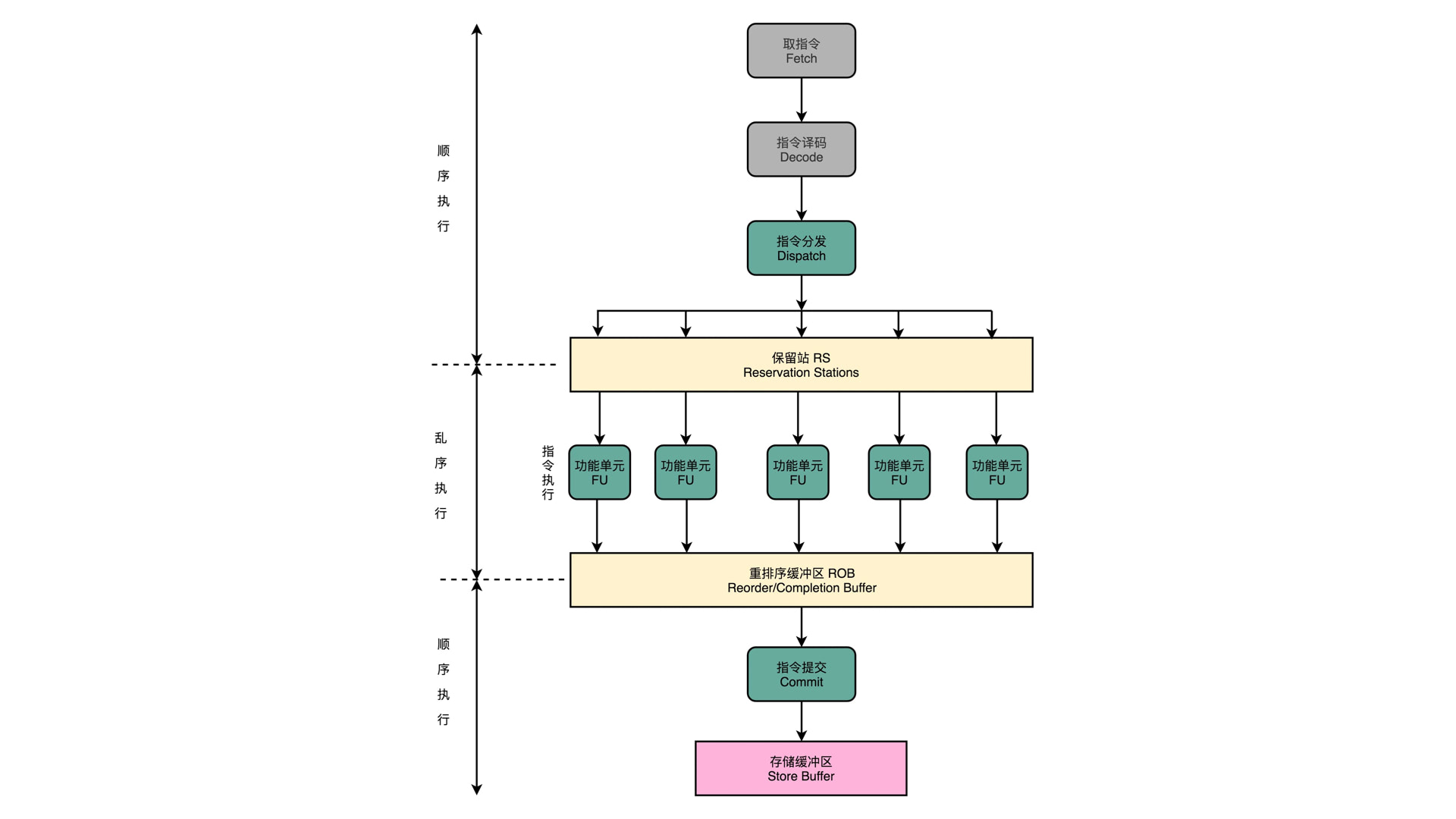
CPU 的乱序只出现在指令执行阶段,即取指、译码、访存、写回这些,都是顺序执行的。
上面的场景 4 里面,虽然指令 1、3、7 被提起执行了,但是 CPU 有一个重排序缓冲区,这个缓冲区会对场景 4 里面的 9 条指令按照真实顺序排好序输出,即最后输出的顺序依旧是:a,b,c,x,y,z,o,p,q。
CPU 乱序,是为了指令执行阶段的高效,但并没有使指令的最终顺序变紊乱。这个和 TCP 协议的分包传输就 100% 相似,TCP 协议里,虽然 Msg 被分成很多个包独立传输,但是最后还是要排序才能确定是否接受消息成功。如果有一个包没有收到,那么还会有多次协商等待。和刚才的 1、3、7 号指令就是一个模子出来的。
CPU 乱序不会导致有序性,真正的 “有序性” 是下文中要说的编译器和解释器导致的。
冒险 - 控制
和本文主题无关,不说了。
预测 - 静态分支预测 & 动态分支预测
和本文主题无关,不说了。
数据安全产生的编译器 & 解释器原因
有序性指的是程序按照代码的先后顺序执行。编译器为了优化性能,有时候会改变程序中语句的先后顺序,例如程序中:“a=1;b=2;” 编译器优化后可能变成 “b=2;a=1;”,在这个例子中,编译器调整了语句的顺序,但是不影响单线程程序的最终结果。但是在多线程情况下,就会有问题了。
1 | // 文本代码 |
上面代码如果在单核多线程中,按照预期,thread2 的 asset 一定能够通过。但是偏偏编译器或者解释器在处理的时候,因为种种原因将 thread1 修改成了下面这样:
1 | void thread1() { |
这就出问题了。当 thread1 执行完 b = 2 这个指令后,thread2 的 while 循环被打破,但是执行 asset 的时候却不通过,因为 thread1 的 a = 1 还没有被执行。
编译性语言先编译在执行,像上面的示例。解释性语言是即时翻译执行,但也会出现上面的翻译优化。而且现在很多语言在编译性和解释性上已经不分家了,比如 Java,所以编译性解释性语言都会有上面的问题。
这个就是因为编译器或者解释器产生的有序性问题,也会导致共享数据不安全。
共享数据不一致原因总结
上面分别通过单核讨论了原子性、多核讨论了可见性、编译器 / 解释器优化讨论了有序性三个重要的问题,其实这就是共享数据安全的三大核心。
这三个原因都会导致共享数据不再安全,使得我们写的代码稍不注意就会有错误风险。
如果要解决共享数据安全问题,就可以从这三个方面找切入点。而且这三个核心因素之间还有一层间接的联系,即三大核心的包含关系。
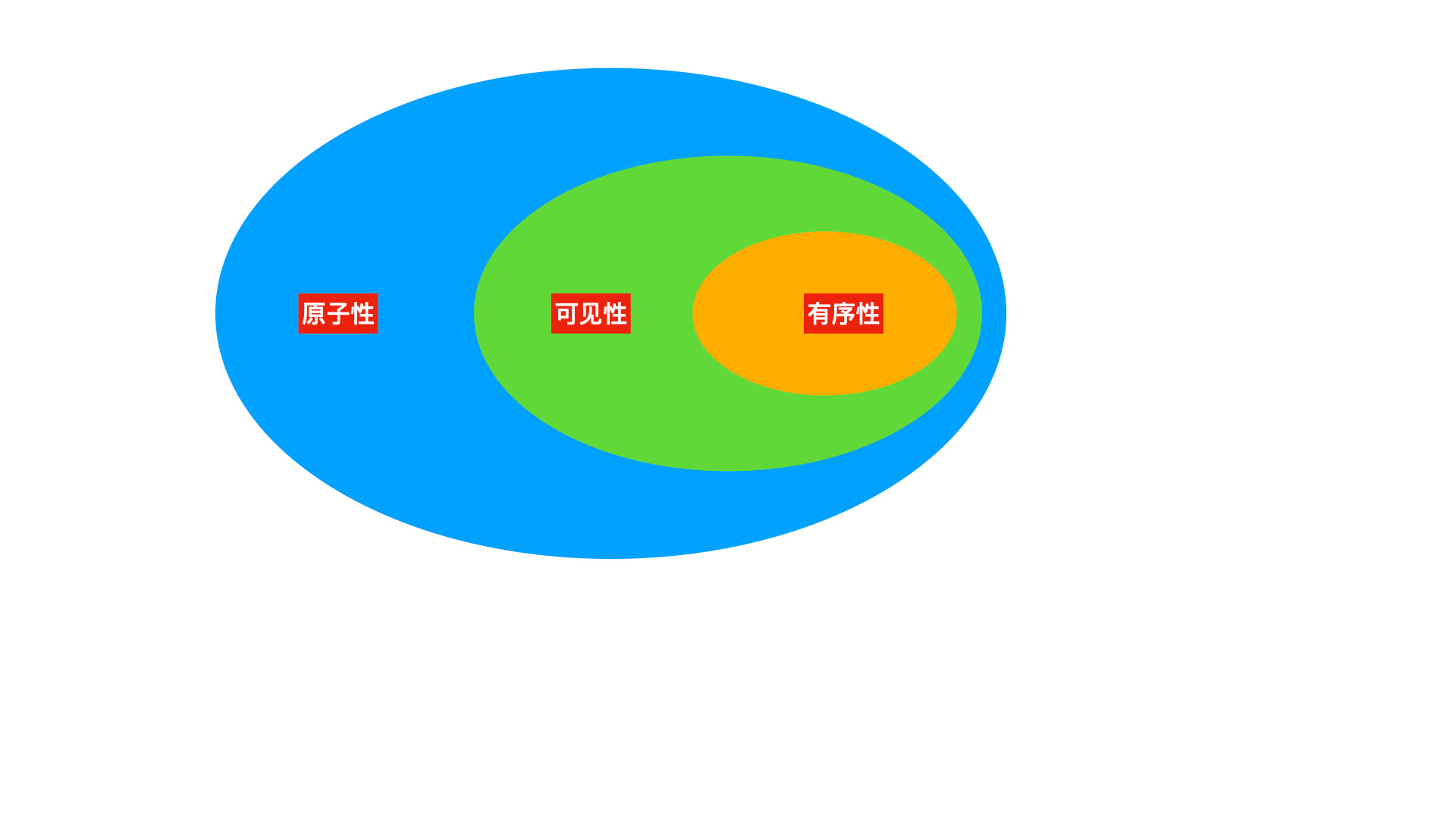
为什么有包含关系,后面会再说。数据安全的处理方式随着范围的增加,效率也递减。所以数据安全处理第一步,就是不要跨范围处理,即能通过有序性解决,则不要通过可见性 / 原子性解决。能通过可见性解决,也不要通过原子性解决。
但是一般事与愿违,基本开发人员都是锁走天下,通过汇编或者不常用的描述符解决可见性、原子性等情况,还不利于团队协同。
但有些语言对这些汇编做了一层高级语言对封装,如 volatile,C/CPP 和 Java 都有不同程度的包装,如果遇到了非原子性问题,那么我们可以通过 volatile 来方便的解决可见性或者有序性问题。在下面的解决方案一趴也会说到。
数据安全阶梯式解决方案
为什么是阶梯式解决方案呢,也就是上图中的包含关系。但是这个包含关系并不是它们之间真的有包含,而是他们的解决方案有包含。即如果要解决可见性问题,那么有序性问题就一定要先解决。如果要解决原子性问题,那么可见性也要先解决。所以就从最小范围的解决方案开始说起。
有序性解决方案
也没啥特效药。编译器或者解释器,都会提供一些前缀给开发人员。开发人员只要觉得一个问题能够单纯通过有序性来解决,那就可以这么做。
比如 C/CPP 中,可以通过下面禁用:
1 |
|
C/CPP 中还提供了 volatile 描述符,该描述符可以停止编译器优化,也可以直接用。Java 中也提供了 volatile,比 C 的 volatile 含义要丰富很多,也可以停止编译器优化。
可见性解决方案
这一趴真是一个大工程。共享数据安全性很难弄清楚,就是因为前置知识细节太多了,而且很多细节还是硬件基础性的。
在多核那一趴,说到了可见性,也没过多描述,当时看图解的执行流程,就能知道数据不安全了。
1 | // 高速缓存导致的内存不可见 |
描述不多,实则问题就越大。为了解决可见性问题,硬件和高级语言都引出了各自的内存模型,这可真是一个大工程。
可见性 - 高速缓存内存一致性 (MESI)
因为可见性是多核 + 高速缓存引起的,是硬件原因导致的,所以硬件工程师们想了一些办法,来处理多核场景下高速缓存数据一致性问题。
首先想到的是 “写传播” 方案。即然多个高速缓存的数据不一致,那么就再数据有变动的时候立刻让他们一致。即一个核心高速缓存改变了缓存块的数据,立刻同步传播到其他核心的高速缓存。
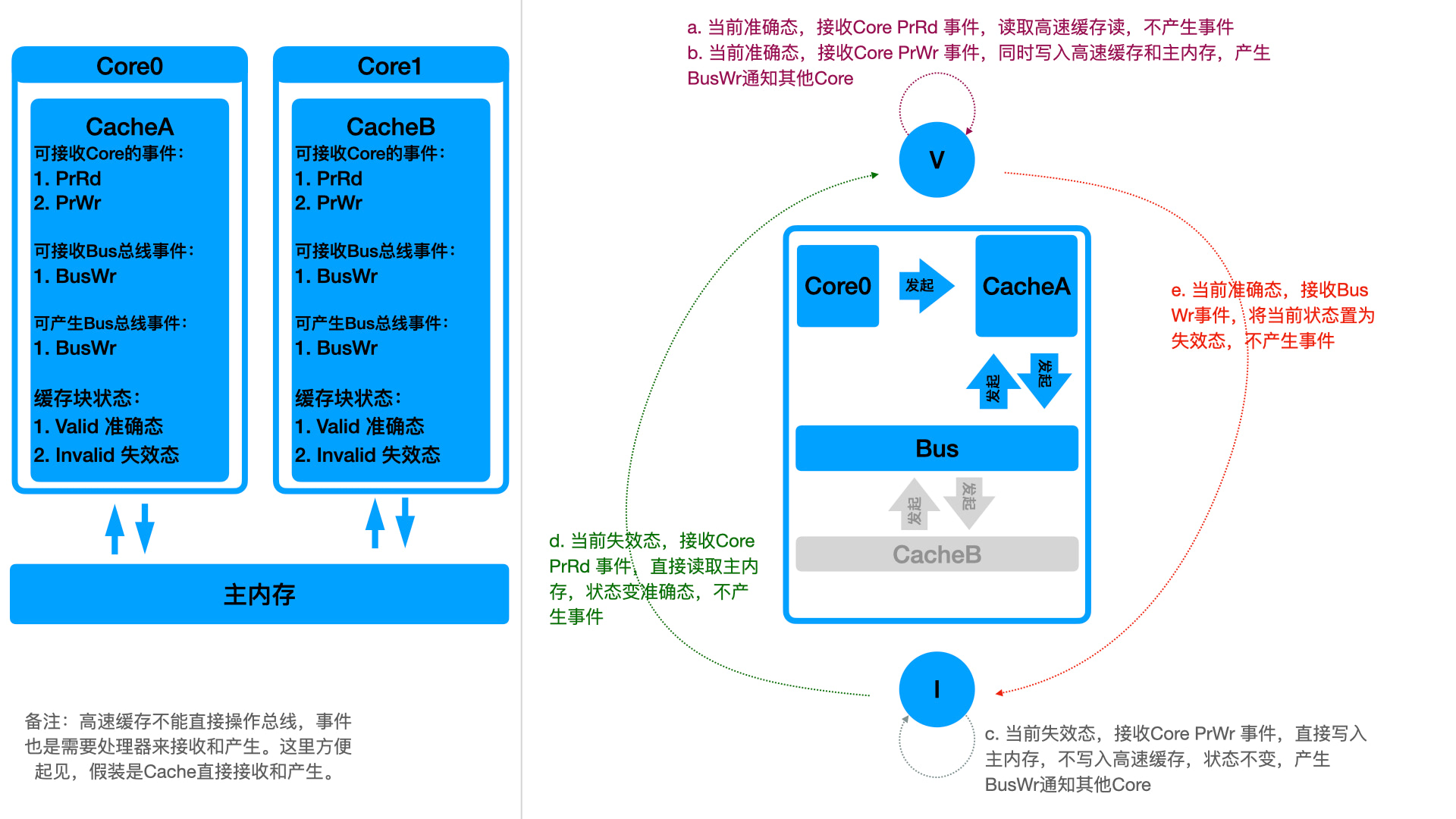
如上图所示,这就是 “写传播” 方案。方案名词如下:
- PrRd:Processor request read action,处理器发起读请求,向高速缓存读数据
- PrWr:Processor request write action,处理器发起写请求,向高速缓存写数据
- BusWr:总线的写通知。如果一个高速缓存有写操作,可以产生 BusWr 事件,其他核心会收到 BusWr 事件并作相应处理
- Valid:状态机里面的准确态。即一个高速缓存的缓存块数据,是和主内存一致的。这个时候读高速缓存的数据,等同于读主内存。
- Invalid:状态机里面的实效态。即一个高速缓存的缓存块数据,是和主内存不一致的。这个时候不能读高速缓存数据,因为不准确。
这个方案有下面几个约束条件: - 所有缓存写操作直接 写到 主内存,即 “写直达” 策略
- 缓存操作是否 读 主内存根据当前状态是否失效判断
上面图示中的 a、b、c、d、e 5 个状态就是缓存块的所有生命周期。状态有 2 个,外部事件有 3 个,本来应该有 6 种情况。上图中少的一种就是 I 状态下收到 BusWr 事件。这个状态下无需处理,因为当前状态是失效状态,需要 PrRd 的时候会触发 d 生命周期,直接读取主内存,所以这个时候完全不需要触发啥动作,前 5 个状态已经能够保障数据安全了。对应上面代码的流程描述如图:
But,“写传播” 的性能消耗非常大,在实际运作过程中,Bus 总线时时刻刻都在做时间的广播。而且写高速缓存的操作必须立刻同步到主内存,这会有很大的性能开销。所以后面就又弄出了伟大的 MESI 缓存一致性协议。
MESI 和 “写传播” 的不同点如下:
- 所有缓存写操作,仅仅写入高速缓存,不在写入主内存。采用 “写回” 策略
- 总线事件有了很大的增强,如下:
- BusRd:总线侦听到一个来自另一个处理器的读出缓存请求;
- BusRdX:总线侦听到来自另一个尚未取得该缓存块所有权的处理器读独占(或者写)缓存的请求;
- BusUpgr:侦听到一个其他处理器要写入本地缓存块上的数据的请求;
- Flush:总线侦听到一个缓存块被另一个处理器写回到主存的请求;
- FlushOpt:侦听到一个缓存块被放置在总线以提供给另一个处理器的请求,和 Flush 类似,但只不过是从缓存到缓存的传输请求。
- 状态机增加了两个状态,现在有 4 个状态:
- Modified(M):缓存块有效,但是是 “脏” 的,其数据与主存中的原始数据不同,同时还表示处理器对于该缓存块的唯一所有权,表示数据只在这个处理器的缓存上是有效的;
- Exclusive(E):缓存块是干净有效且唯一的;
- Shared(S):缓存块是有效且干净的,有多个处理器持有相同的缓存副本;
- Invalid(I):缓存块无效。
MESI 协议那可以说是相当复杂了,很容易绕晕。
首先需要明确 M、E、S、I 四种状态,分别阶梯式说明:
- E (Exclusive) 状态:当前共享数据只被一个核心的高速缓存拥有。这个时候是独占的,等同于单核场景。
- S (Shared) 状态:当前共享数据被多个核心的高速缓存同时拥有。这个时候多个高速缓存里的数据和主内存是一样的,相当于多个核心都做了读请求,主内存数据加载到了多个核心中。如果有 4 个核心,那么现在 4 个高速缓存里的数据都一样,并且和主内存一样。
- M (Modified) 状态:这个时候,当前缓存的数据是最新的,也就是最准确的。在 E 状态如果核心做了写操作,那么会把数据写入高速缓存,但不是写入主内存。这个时候缓存和主内存不一致,就是 “脏” 的修改状态,会从 E 状态迁移到 M 状态。同时,如果之前处于上面的 S 状态,这个时候一个核心做了写操作,也会把当前核心的状态从 S 变为 M,当前核心的数据就是最新的,同时把其他三个核心的状态全部标记为 I 状态,因为其他三个核心的数据都不在准确了。
- I (Invalid) 状态:就是失效状态。上面 M 状态里面有一个说明,三个核心的高速缓存从 S 迁移到 I 以标记当前数据不是最新的了。如果读取 I 状态的数据,要看当前数据有没有被其他核心拥有。如果没有,那么当前核心就是独占,就会迁移到 E 状态。如果已经有其他核心拥有,那么就是共享状态被多个核心持有,就会迁移到 S 状态。
MESI 的状态迁移有一个特点,就是 Core 处理器对当前高速缓存发起的 read 和 write 请求,总会将 E、S、I 三个状态往 M 状态迁移,而 Bus 总线发起的通知事件,总会将 E、S、M 三个状态往 I 状态迁移。
状态迁移流程如下图所示。为了方便理解,我把上面代码的迁移过程也标注在图上:
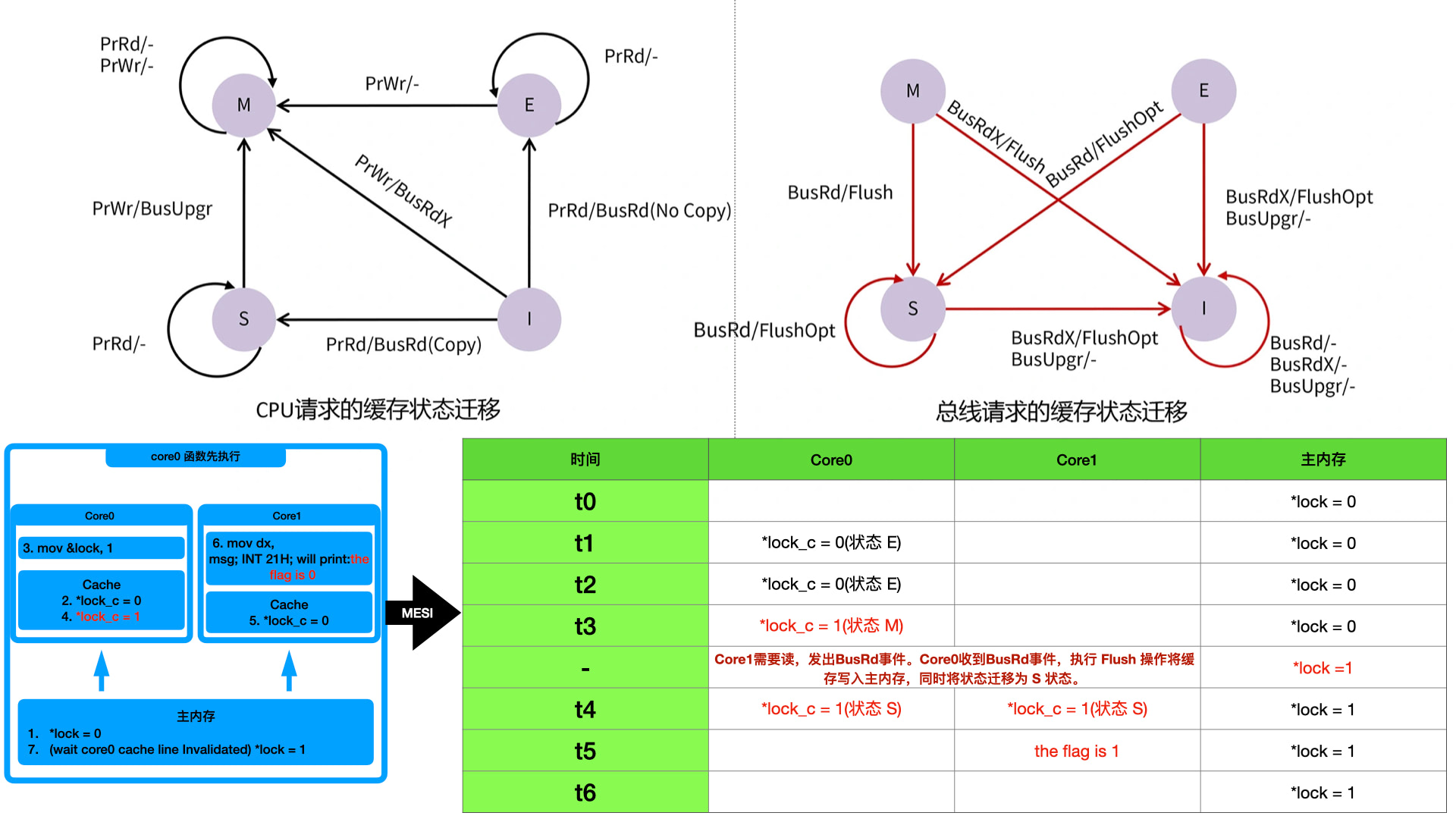
至此,MESI 通过不立刻写入主内存的方式,有效的提高了 “写传播” 带来的损耗。也通过硬件层面解决了共享数据不安全的问题。
But,MESI 的总线事件比 “写传播” 方式更多更复杂了,这也一样有很大的性能消耗。
可见性 - 内存一致性优化 (Store buffer / Store forward / Invalid queue)
丧心病狂!
从上图中,可以看到当处于 S 和 I 状态的时候,如果产生了写操作,会迁移到 M 状态,而且产生 BusUpgr 事件。在其他状态下,都基本不产生啥事件。所以如果不是多核共享数据的场景下,MESI 的确非常有效的提高了效率,寄存器只要和高速缓存之间交互就好了。
但是上面 S 和 I 状态迁移 M 状态这种场景,科学家们无法忍受,要再做优化。原因是这个状态迁移,实打实的阻碍了 CPU 的执行:
- 当 A 核心从 S 迁移 M 的时候,首先需要发起 BusUpgr,并等待其他核心的回复。这里有一段漫长的等待耗时,CPU 是卡顿的。
- 其他 B/C/D 核心收到 BusUpgr 事件,需要将状态置为 I 状态。这个置为 I 的操作也是耗时的,虽然 CPU 没有卡顿,但需要时间。
- 其他 B/C/D 核心将状态置为 I 状态后,会向总线回复一个 ack 事件,分别告知 A 核心它这边处理完了。
- A 核心收到 3 个 ack 事件后,才能将新的值写入高速缓存。写入高速缓存后,才能继续往下执行。
于是呢,比 L1 高速缓存速度更快的 buffer 出现了,如下图所示:
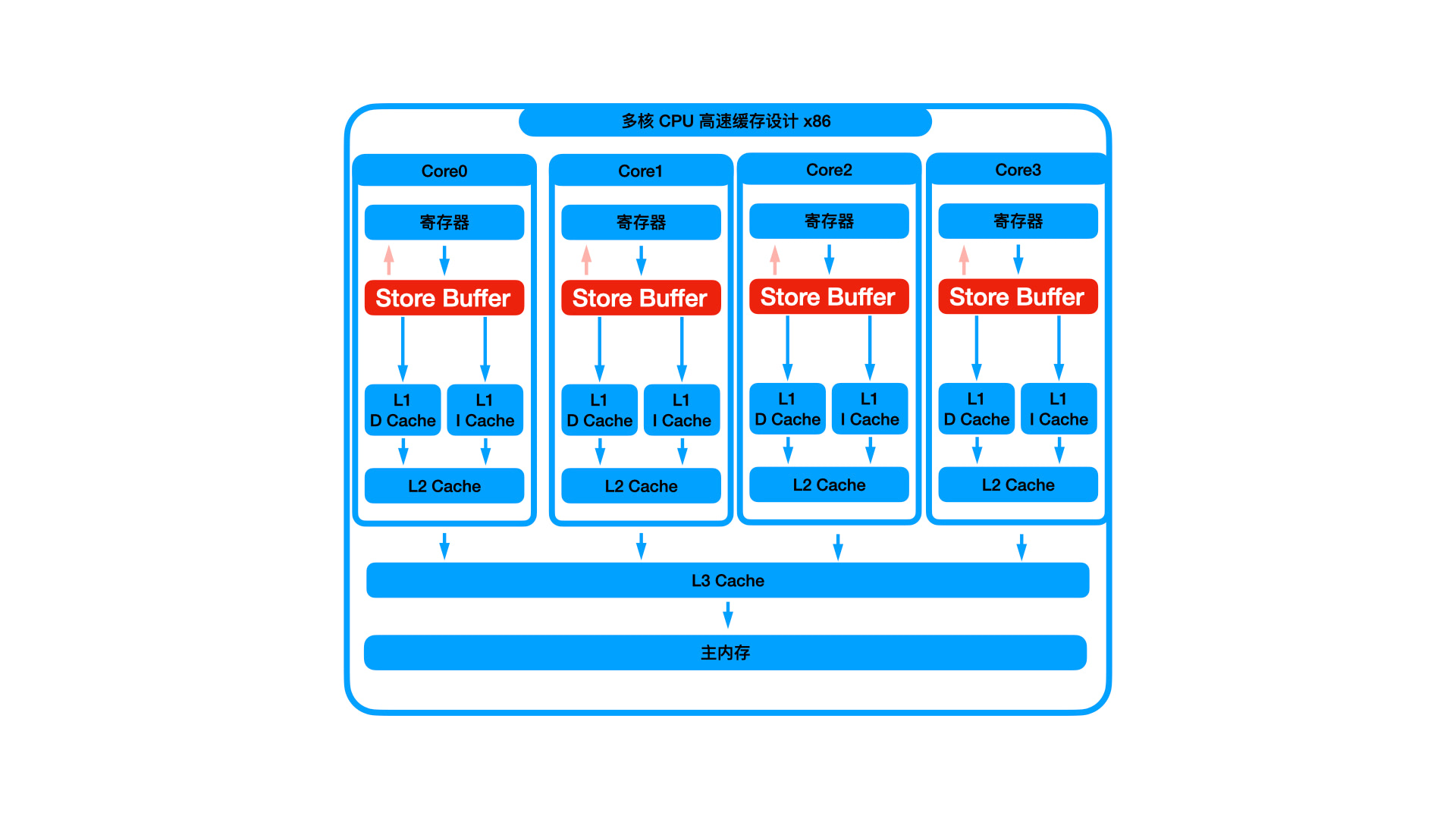
Store Buffer 处于 L1 的更上一层,所以价格比 L1 更贵,容量比 L1 更小, 速度比 L1 更快。
所有对 L1 的写操作,都会先写入到 Store Buffer 中。CPU 写入 Store Buffer 后,就不管了,相当于是一个异步执行,直接开始执行后面的指令了。这样,就把上面的那 4 个步骤里面的步骤 1、4,原来通过 CPU 来完成,现在让 Store Buffer 去完成,CPU 不管了。
那如果 CPU 对 L1 写操作之后立刻执行读操作呢?上面 Store Buffer 是异步延后执行读,如果 CPU 立刻对 L1 进行读操作,肯定读不到数据。上图中 Store Buffer 上面还有一个指向寄存器的箭头,即 Store Buffer 可以直接返回数据到寄存器中。这个叫 Store Forward。即如果判断当前数据在 Store Buffer 中,那么当前 CPU 不会读 L1,而是直接读 Store Buffer。
增加了 Store Buffer 后,上面步骤 1、4 被 Store Buffer 接管。但是步骤 2、3 还是被其他 CPU 执行的,依旧会卡顿。这个时候就很容易出现 Store Buffer 不断塞入数据,而其他 CPU 还处理不完导致 Store Buffer 无法出数据。Store Buffer 很快就被延迟数据塞满了,毕竟容量比 L1 还要小。这个时候呢,丧心病狂啊,Invalid queue 来了。
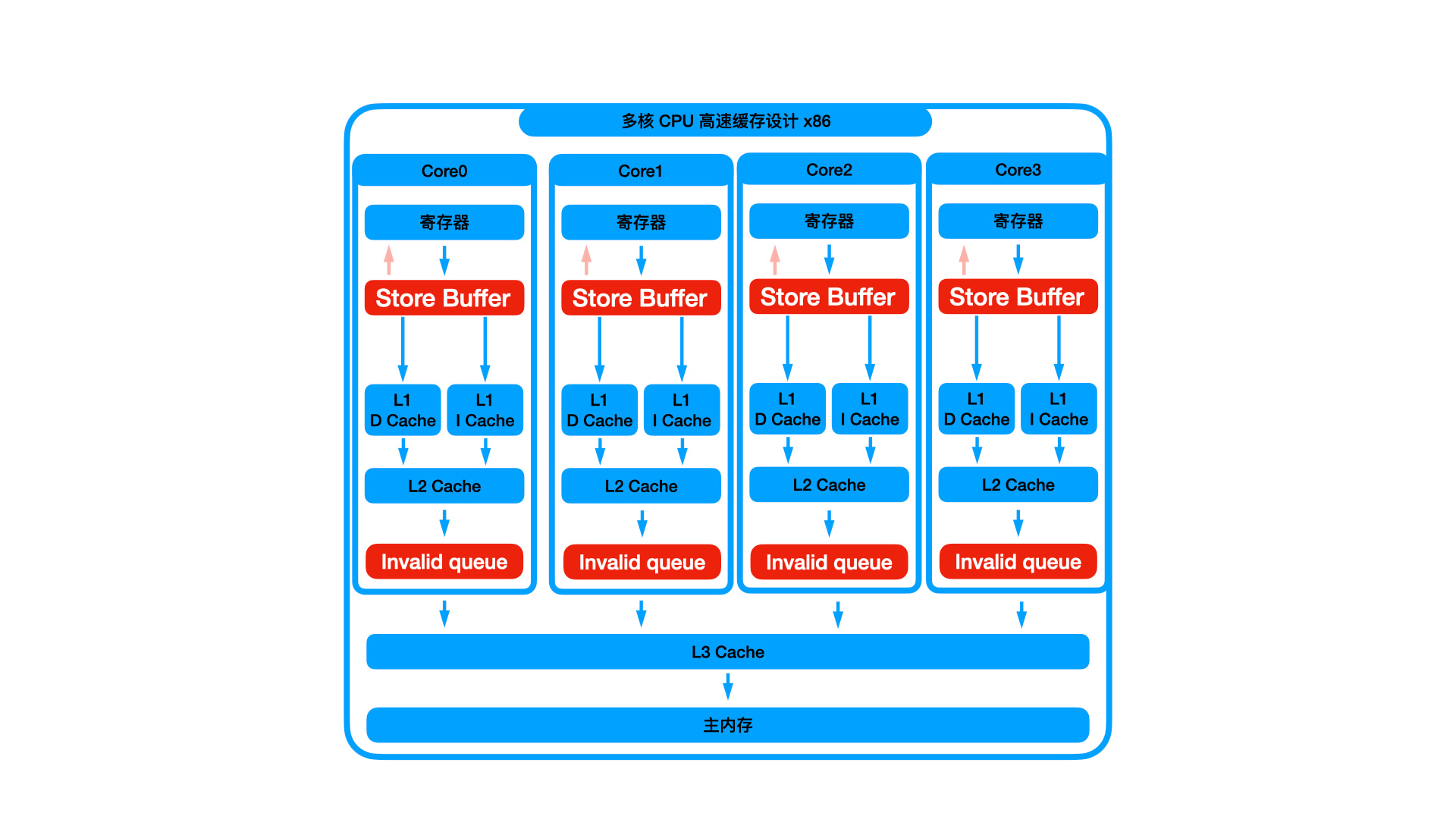
如上图所示,增加了 Invalid queue 后,步骤 2、3 也不再由 CPU 处理了,而是直接将收到的 BusUpgr 事件存储到 Invalid 队列中,并立刻返回 ack,在后面 CPU 空下来后再执行 Invalid 队列里面的消息。所以这个时候高速缓存的状态并没有改变,只有等 Invalid 队列的消息被处理完成后,高速缓存的状态才会改变。
这样步骤 1、2、3、4 都被异步了,极大的提高了生产效率。。。。。。。。。百因必有果,程序员的报应就是这群丧心病狂的科学家,因为 Store Buffer 和 Invalid queue,又有新的恶魔。
可见性 - 高速缓存顺序一致性 (内存屏障)
上面还没说 MESI 的 Store Buffer 和 Invalid queue 优化之前,MESI 协议是共享数据安全的,我们也画图说明了。但是有了优化之后,共享数据再一次变得不安全了,如下图:
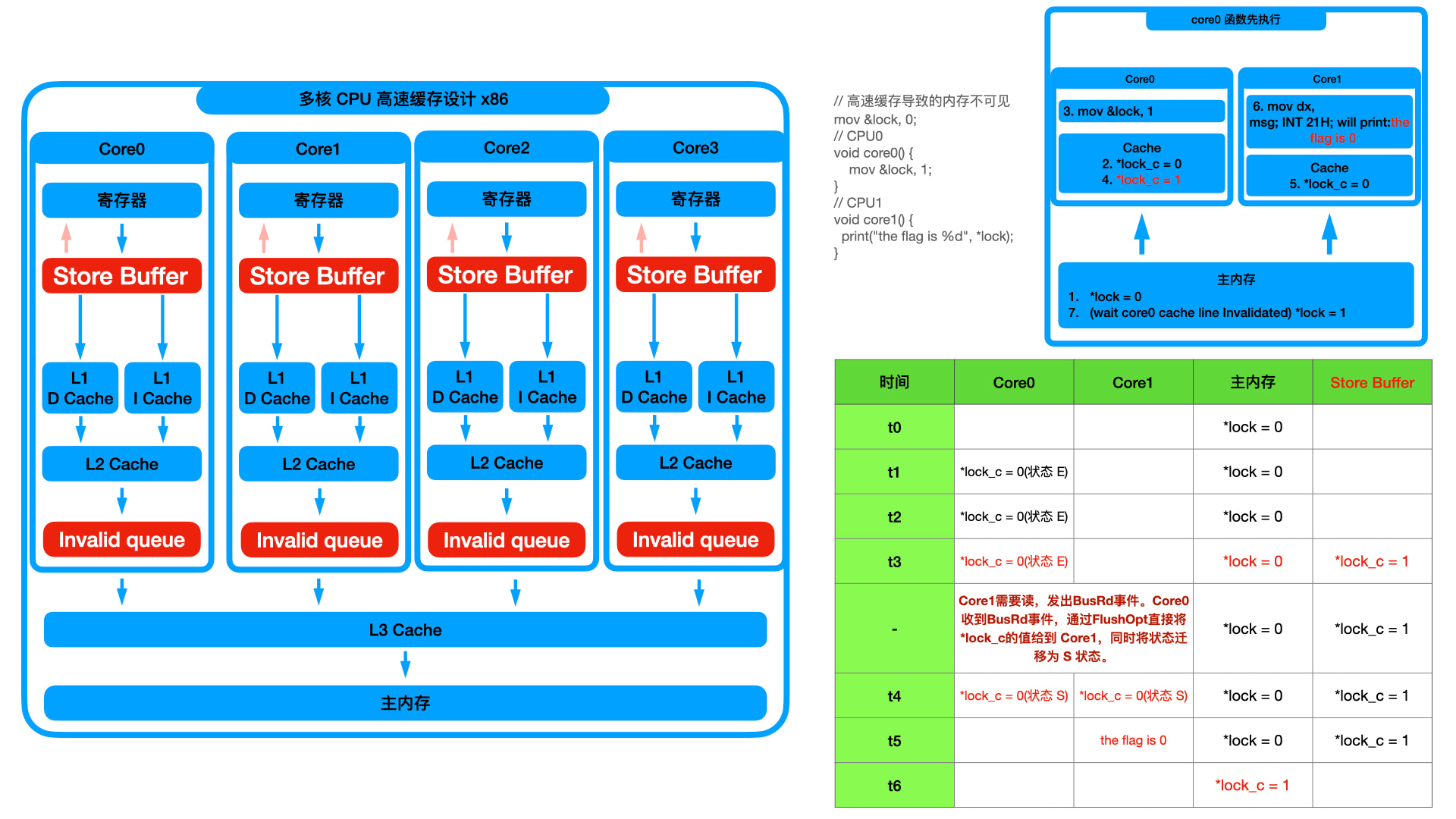
Core0 把数据存入了 Store Buffer,这个时候其他 Core 要读取数据的时候,Core0 的高速缓存还不知道数据将要做修改,保持修改前的逻辑和其他 Core 通信。这个时候高速缓存的可见性其实还有,只是不准确了。过一段时间 Store Buffer 处理完成后,其他核又能看到数据了。那其实再并行编程中,哪个核先执行本身就是未知的,我们的程序一定要做一些依赖处理,比如循环等待某个变量达到预期,这个时候就知道其他核处理完了数据,就可以继续后续的任务了。所以上面的可见性问题,并没有达到无法接受的程度,鉴于程序本身的并行考虑,我们的程序也会做这层处理,只要等到可见性重新恢复即可。
偏偏 Store Buffer 和 Invalid queue 不仅仅导致短时间的不可见性,还引来了更大的问题,即内存顺序一执行。
比如下面示例:
1 |
|
这个示例会因为 Store Buffer 和 Invalid queue 分别导致 assert 断言失败。
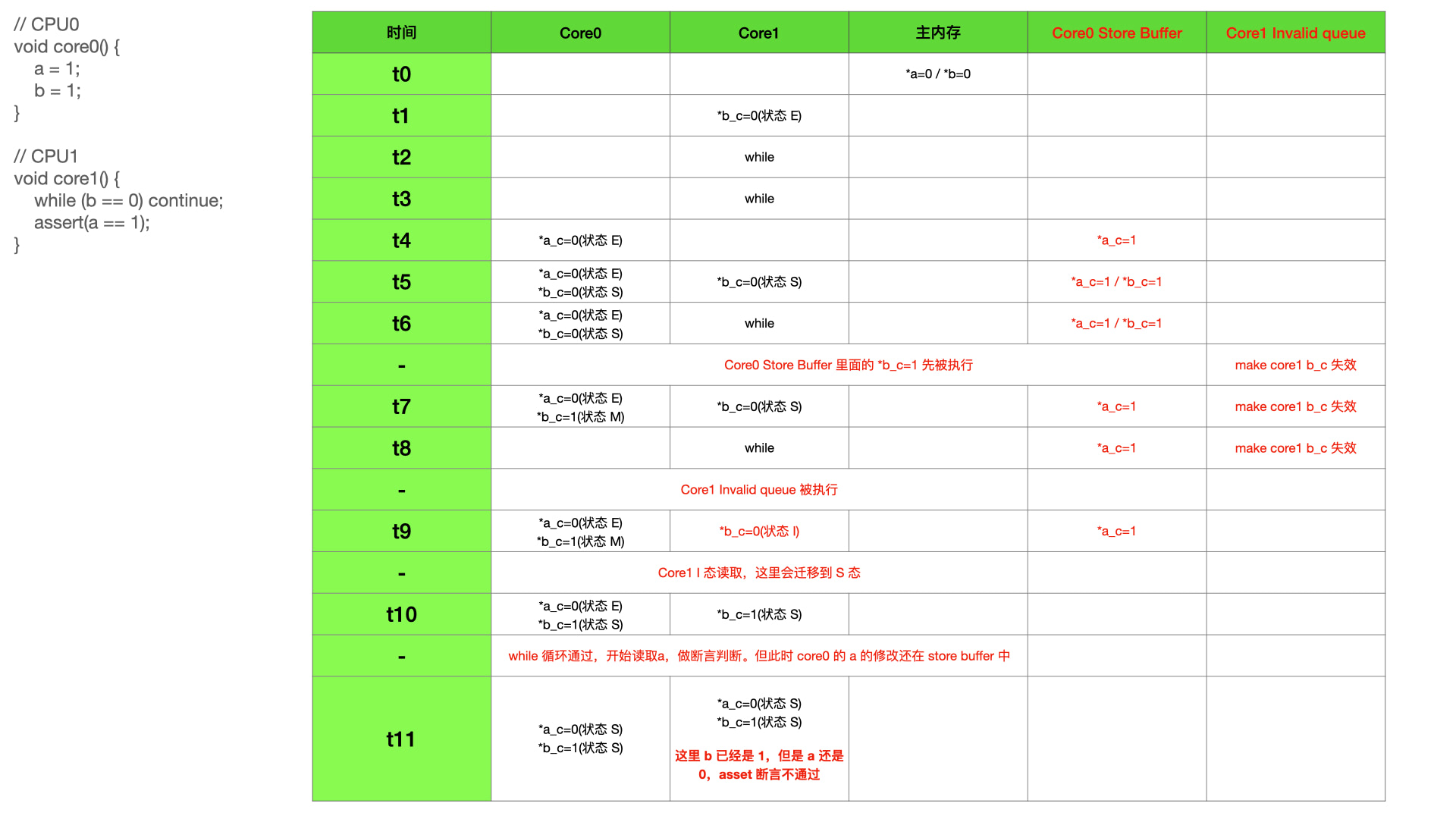
上图中把 Store Buffer 和 Invalid queue 一起操作,使得最后 assert 断言不通过。其实单独分析 Store Buffer 或者 Invalid queue,也一样会断言不通过。
这个就是 MESI 优化导致的顺序不一致问题。即一个核心对共享数据的修改顺序,对另一个核心不可见。上图中对于 core0 来说,应该是 a 比 b 先执行写入操作,但是在 core1 看来,b 先写入了,经过一段时间之后,a 也会被写入。这样的顺序正好和 core0 的执行流程是相反的。
为了解决顺序不一致问题,就引入了内存屏障。内存屏障直观来说就是操作 Store Buffer 和 Invalid queue。对于操作 Store Buffer 的,我们叫做读屏障,对于操作 Invalid queue 的,我们叫做写屏障。如果两个一起操作,那么就是全屏障。
所以上面代码加入读写屏障后,即:
1 | // CPU0 |
上面示例中,write_barrier 读屏障就是将 store buffer 立刻全部写入,写完成后才能继续后面的操作。而 read_barrier 写屏障就是将 Invalid queue 全部执行,执行完成后才能继续后面的操作。full_barrier 就是全屏障了。
有了上面的屏障,大家就可以发现,屏障就是使得 MESI 的优化失效,达到 MESI 未优化的状态。这个未优化状态我们前面说过,是共享数据安全的。但是会牺牲性能
这个内存读写屏障呢,就是硬件工程师手把手教会软件工程师的,然后往后的岁月里,软件工程师都得不断的注意要不要写屏障,哪里写屏障,写什么类型的屏障。硬件工程师教会了后,就不管了。。。
大家不要觉得夸张,现在所有的语言中,都离不开内存屏障。因为这是硬件层面的共享数据不安全,而语言需要适应多核处理器以需求更快的性能,所以没有一个能避开内存屏障。
但是我们其实很少写内存屏障的。就是上面说的,MESI 已经非常复杂了,如果还要让所有开发人员理解这套硬件知识来写屏障,那门槛太高了。屏障一般都通过语义化的形式在高级语言中实现了,比如 C/CPP/Java 里面的 volatile。我们只要理解并使用 volatile 的内存语义,即使不理解上面的 MESI 模型,也能写出具有可见性和有序性的代码。
大家注意上一句的结尾,只要使用 volatile,就可以解决可见性和有序性。前一趴在说有序性解决方案的时候,也提到了 volatile。其实这就是高级语言的好处,全包了。
高级语言递出的可见性解决方案
volatile 在 C/Cpp 和 Java 中分别代表那些含义
loadLoad /loadStore/storeStore /storeLoad 并不真实存在,只是 JVM 的一个概念。针对不同硬件架构,会有不同的指令集实现。
在物理原因那一趴,我们说明了高速缓存的不可或缺的重要性。在可见性这一趴,我们尝试通过 MESI 解决高速缓存带来的可见性问题。MESI 虽然能解决,但是性能遇到威胁,硬件上只能开启 MESI 的 Store Buffer 和 Invalid queue 优化。优化过后呢,可见性被延迟了,而且带来了严重的顺序一致性问题。引入内存屏障之后呢,将部分代码强制关闭优化,使的 MESI 仍旧可以解决可见性问题。
但是显而易见,内存屏障是关闭 MESI 优化,即内存屏障是有损耗的。我们只应该在需要的地方加,即共享数据不安全的地方加,如果哪里都加,那么就使得 MESI 性能遇到威胁。
这一大趴是数据安全的阶梯式解决方案,前面也说过,有序性、可见性、原子性是递进的包含关系。其实这里引入内存屏障后,编译器或者解释器就会默认关闭优化,即不会出现有序性问题了。比如上面的例子,可见性上我们用内存屏障做了那么多努力,结果编译器就是把 b=1 编译到了 a=1 的前面,那么我们用内存屏障解决什么问题呢?什么都解决不了了。
所以可见性的解决方案 - 内存屏障,默认已经解决了有序性问题,编译器或者解释器帮我们做了这一步。
volatile 可以解决有序性问题,即告知编译器不要优化,同时也会加读写屏障,保障可见性问题。
volatile 在 C/CPP 和 Java 中语义不同。因为两门语言对于各自的内存模型有不同的定义。
在 C/CPP 中,volatile 就是刚才说的,比较直接,就是告知编译器不要优化,同时对修饰的变量或者函数增加读写屏障。如下,注释做了说明:
1 | typedef struct s_ATOMIC { |
Java 中 volatile 更加复杂,JMM 的内存语义增加了 LoadLoad、LoadStore、StoreStore、StoreLoad 四种内存屏障。一开始我不理解,现在我也不完全理解,就把我理解的先阐释出来,希望八九不离十。
JMM 是定义了一套内存语义,但不是实现。即 JMM 是一套标准,但具体怎么实现,得看实现方。
JMM 中定义了一套 Happens-before 语义,该语义定义了一套准则,使得要想保证操作 B 可以看到操作 A 的结果,A 和 B 就必须满足 Happens-Before 关系。
那么现在的问题就是 JMM 的这套 Happens-before 语义如何在 JVM 中实现,JMM 是理念,JVM 才是落地的产品。
在 JVM 的实现手册中,链接,明确说明了刚才说到的四种 load 和 store 的组合关系,如下:

即被 volatile 修饰的变量或者函数,在它的前面的指令和后面的指令之间,需要插入对应的 load x store 组合的屏障,以保障 Happens-before 语义。那 load x store 组合的屏障该如何实现呢?
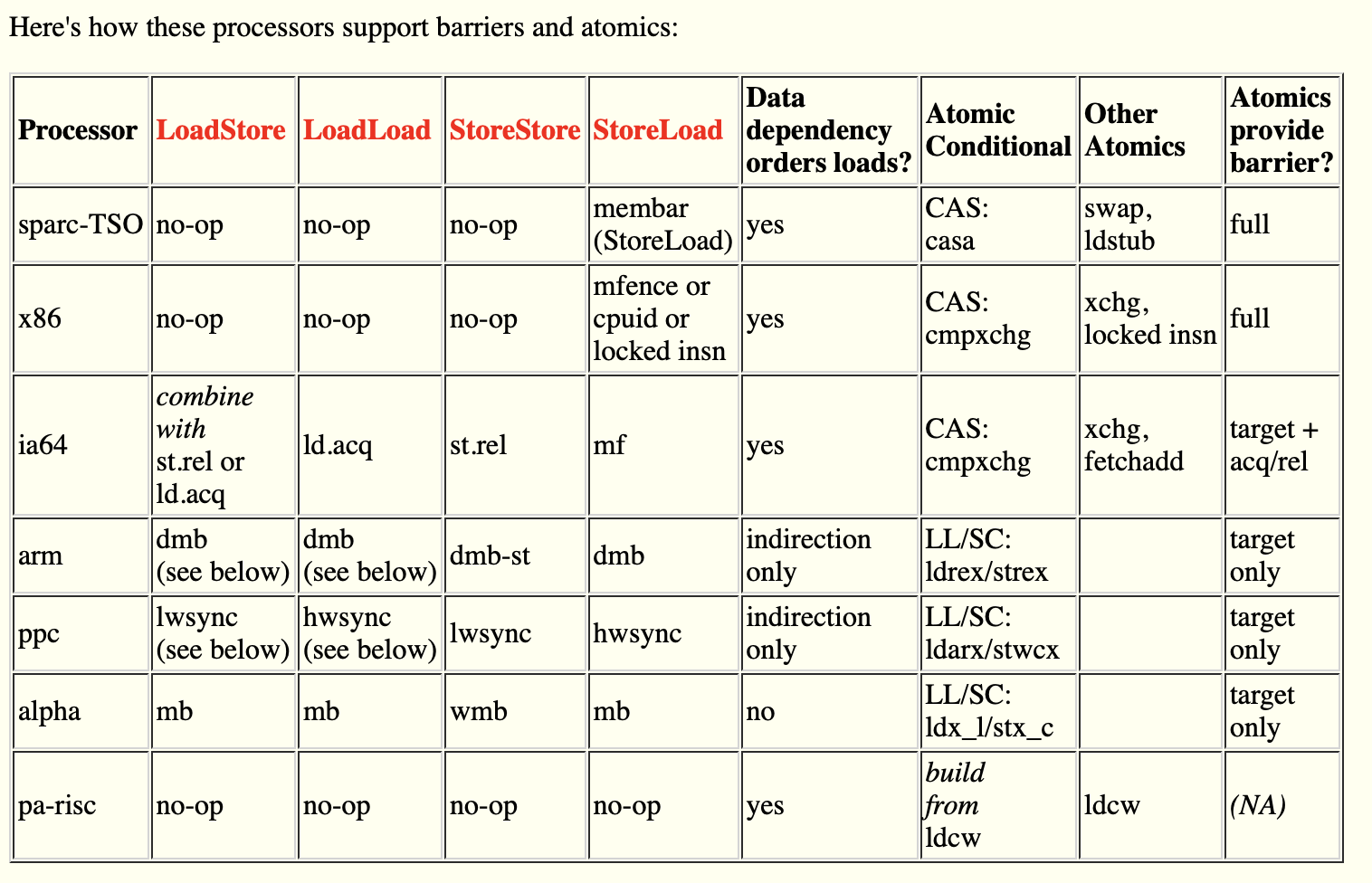
在 JVM 实现手册的底部,给出了实现方案。原来 JVM 并没有抛弃前面说到的硬件层屏障,JVM 在 Happens-before 语义的实现上,为了兼容多个处理器架构,使用了各自架构对应的内存屏障。
上图中,我们上面说的 read_barrier 和 write_barrier 以及 full_barrier 就是 alpha 架构的。在表中,StoreStore 使用的就是 wmb,即 write_barrier。但是不明白为什么 LoadLoad 没有使用 rmb,而是使用了 mb。mb 即 full_barrier,LoadStore 和 StoreLoad 都是用 mb 实现的。
不同架构对于内存屏障的实现是不一样的,这里着重说一下 x86 和 ARM。
x86 的内存屏障只有 StoreLoad。x86 架构比较特别,它采用的是 TSO 模型,没有设计 Invalid queue,所以没有读屏障。Store buffer 设计成队列,即先进先出,所以缓存的写入是顺序的,不会产生顺序一致性。直观来说,x86 就没有可见性问题。但是 x86 提供了 StoreLoad 屏障,也并不是为了解决缓存一致性问题而存在,但这个屏障也是要被使用。我没有深究,我理解就是如果不加 StoreLoad 屏障,那么不会导致缓存一致性问题,但是会导致其他问题。所以上面的表中,JVM 在 loadload/loadstore/storestore 都加入了 NOP 无效指令停顿。NOP 在前面说流水线的时候说过,单纯的使得 CPU 空转一个时钟周期。在 storeload 处增加了 mfence 屏障。
ARM 的架构 和 Alpha 不同。ARM 没有使用 读写屏障,而是使用了单向屏障。分别是 stlr (store release register) 和 ldar (load acquire register),相当于 Alpha 的读写屏障吧,但是比读写屏障的范围大,功能也更大一些,但也代表着额外做的开销也大一些。ARM 还有 一个 dmb (data memory barrier) 指令,就是全屏障了。stlr 是 release 语义,有 storestore 和 loadstore 的语义,ldar 是 acquire 语义,有 loadload 和 storeload 语义。所以上表中,JVM 的四种屏障类型,应该通过 stlr 和 ldar 就能实现,而不需要使用 dmb。我理解上表中只是说对应屏障语义在各自架构上面的屏障类型,而没有细化到具体的实现。
有一点说明,在四种组合屏障里面,storeload 是最大的屏障,即 storeload 可以完成其他三个屏障的功能。所以一般 storeload 也都是用 full_barrier 实现,是代价最高的屏障。至于为什么 storeload 是最大的屏障,我初步理解就是先写后读的场景对数据的要求更严格这样子。
这里对高级语言的 volatile 做了详细的说明,但是 volatile 主要解决可见性,顺带解决有序性,至于原子性问题,volatile 是解决不了的。
原子性解决方案
终于要说到锁了,这里是分界岭。前面那么多内容都不是说锁,后面所有的内容基本都围绕锁转了。
本来这篇文章就是说锁的,为什么前面要说那么多铺垫?就是因为需要锁的物理因素太多了。如果物理因素不明了,那么业务中的那么多锁,该怎么用?哪个锁性能更高或者更贴合业务?
而且,如果我们的多线程代码本身没有原子性问题,但数据就是产生了紊乱,这个原因也不好分析。只好在注释里面加一句:
1 | // 下面的代码会多线程访问。我分析过,没有原子性问题。不知道怎么回事线上就数据紊乱了。 |
硬件层面支持指令原子性安全
在单核的时候,我们提到的原子性指令都是安全的,但是在多核并行的时候,就不再安全了。在并行 - 原子操作那节,我们用 cmpxchg 做为示例说明了原子指令的不安全。
所以原子性解决方案里面,第一步就是如何把那些 CPU 的原子性指令变得安全。因为这些指令不安全,那到底是用不是不用呢?不用感觉可惜,他们是很强大的指令,用吧就不安全。所以这个问题必须要解决。
解决原子性问题的方案有两种,一种是 Bus 总线锁,一种是高速缓存行锁。但具体使用那个锁,是由硬件决定的,我们要做的仅仅是加锁:
1 | // xchg 内存交换指令 |
上面的 volatile 是为了防止编译器优化,为了防止有序性和可见性问题。lock 则是 xchg 的锁。
如果是总线锁,则 core0 开始执行 xchg 的时候,会将整个 bus 总线锁住,其他的任何总线操作都不允许执行。这样的性能开销非常大,所以出现了缓存锁。
缓存锁即对于 &lock 的缓存行加锁。如果 core0 加了缓存锁,那么其他核在访问 &lock 的时候,因为不同的高速缓存的 &lock 缓存行均被锁住,所以其他核心无法执行。只有当 core0 的 xchg 指令执行完毕,解开了缓存锁,其他指令才会继续执行下去。
所以通过总线锁或者缓存锁,就可以使得 xchg 和 cmpxchg 这些原子指令在多核并行场景下也能够正常执行。
其实还有一个中断问题,我们只要在 xchg 执行前关闭中断,在 xchg 执行完毕后打开中断,就可以解决。这个比较好解决,不在说明。
1 | // 关闭中断 |
操作系统 & 高级语言支持任务原子性安全
在说到 xchg 的时候,我们说到它是自旋锁的实现,而 cmpxchg 则是 CAS 无锁的实现。其实在硬件的上一层,根本无法解决原子性安全问题。因为问题出在硬件,软件再怎么解决,也解决不了。
上面说的指令原子性安全,是硬件提供了 lock 指令实现了多核并行安全。而文章开头写到的 flag++ 任务是由多个指令组合而成,单纯从软件层面是无法使得这多个指令完成原子性操作的,因为硬件都无法保障。目前看,其实硬件层面实现的原子性安全操作也寥寥无几,就那么一些,比如原子增、原子减等。但就是这些个少有的原子性安全指令,被操作系统和高级语言玩出了花。
自旋锁
自旋锁是其他锁的基石,基于内存交换指令的 CPU 原子性安全指令 lock; xchg 实现。xchg 和 lock 已经在 “单核 - xchg 原子操作” 和 “原子性解决方案 - 硬件支持” 两趴说明过了。下面看看自旋锁如何实现。
自旋锁的原理是首先读取锁变量,判断其值是否已经加锁,如果未加锁则执行加锁,然后返回,表示加锁成功;如果已经加锁了,就要返回第一步继续判断其值是否已经加锁不断循环,因而得名自旋锁。
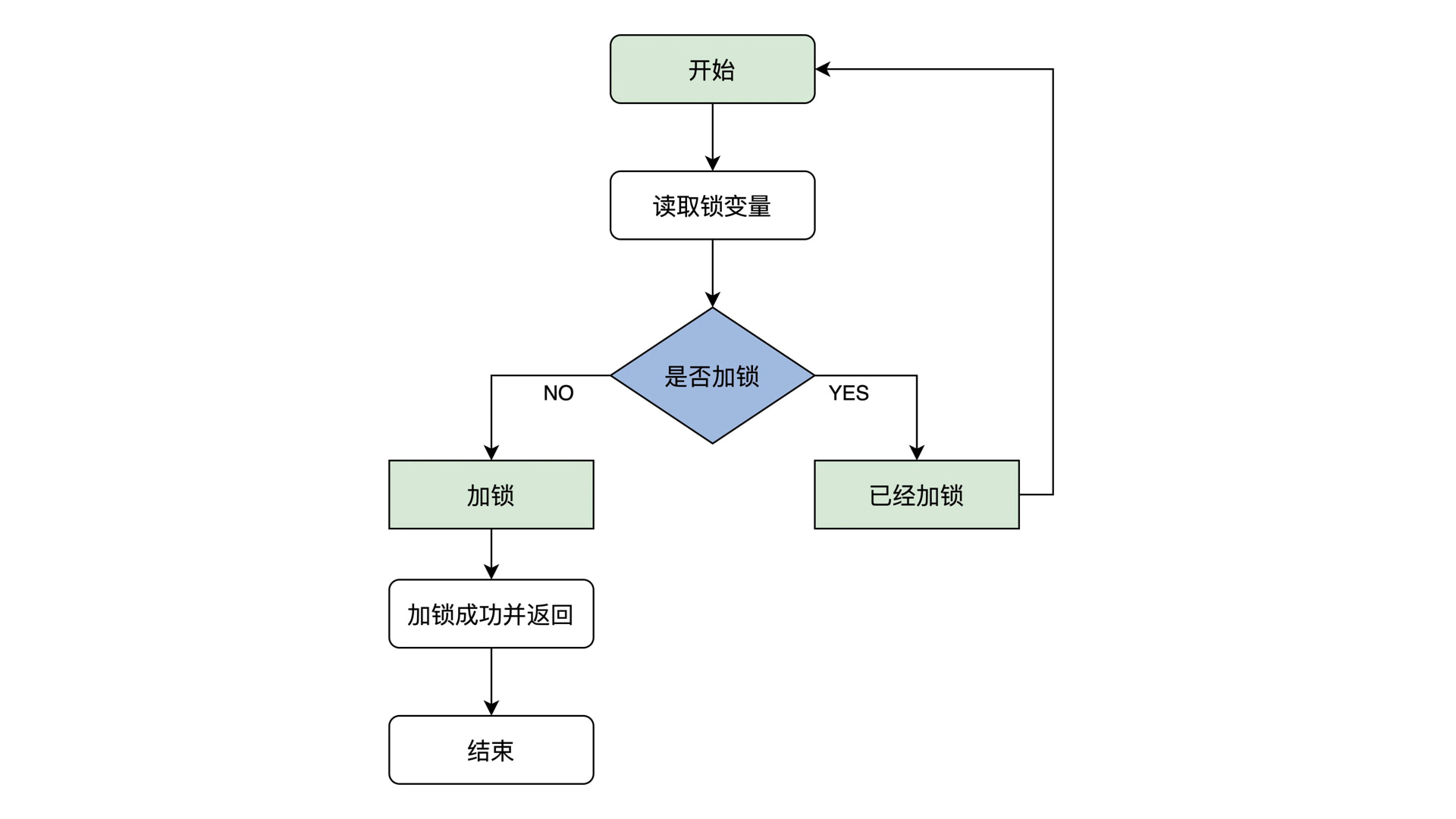
想要自旋锁正确运行,就必须保证读取锁变量、判断是否加锁、加锁这三个操作是原子操作执行的。因为一旦执行过程中锁变量被修改,就不能达到获取锁的正确性。而 lock + xchg 就可以做到这个。
1 | //自旋锁结构 |
使用自旋锁,会产生非常大的性能消耗。因为在没有拿到锁的时候,会一直循环尝试获取锁,会使得 CPU 的使用率飙升,但只要上一把锁还没有释放,飙升的 CPU 使用率都是徒劳的。
但是自旋锁却又是最高效的,因为下一把等待锁的线程一直在尝试加锁,所以只要上一把锁被释放,下一把锁就会立刻响应。
毫不夸张的说,除了硬件层面的 lock 锁,自旋锁的所有锁中效率最高的。因为其他锁都是依靠自旋锁不断加临界区的判断条件,不可能效率上比得过自旋锁。
所以,目前对于自旋锁的使用都很谨慎,主要是担心过大的性能消耗。比较好的办法呢,是即使用自旋锁的高效率,又让自旋锁仅仅执行非常少的时间,这样就可以低消耗、高性能的使用自旋锁。所以操作系统和高级语言就依靠以自旋锁为底层实现,依靠银弹 “中间层” 这个神器,群魔乱舞了。介绍其他妖魔之前,再说一下自旋锁的优先级反转问题。
优先级反转字面意思,高优先级线程晚于低优先级线程执行。
普遍的理解是当遇到有资源依赖的时候,有依赖的线程会因为资源正在被使用而无法被相应,即使有依赖的线程优先级很高,但资源正在被使用,也没办法,这就使得其他无依赖的优先级低的线程早于高优先级线程执行完毕。这种资源依赖场景尤其为锁比较常见。我倒不是很理解,那你优先级再高,有资源依赖那也没有办法啊,谁让你有依赖呢。
再有其他的理解,就是高优先级依赖资源,该资源正在被低优先级持有。此时高优先级处于等待状态。但是因为高优先级能够获得更多的时间片,导致高优先级不断的抢占时间片做无作用的执行,此时低优先级无法获得更多的时间片导致任务一直完不成,加剧了高优先级被阻碍的时间。尤其是自旋锁场景,因为高优先级没有睡眠,一直在自旋,就导致低优先级迟迟获取不到时间片,卡死了。
基于上面的两种理解,最常见的做法就是提高正在持有资源的线程的优先级,使得持有资源阻碍后面高优先级线程的那个线程能够获得更多的时间片,从而尽快执行完毕,让出资源。
上面的解决方案也挺好的,但是这个优先级反转问题,却最终使得 iOS 上面的 OSSpinLock 自旋锁不建议被使用了。
我不是很理解,我觉得是苹果的工程师想摸鱼。有消息说 iOS 的 OSSpinLock 自旋锁,没有记录线程信息,所以不知道优先级高低,,,啊这,,,这不是虾扯蛋么。
所以 iOS 上面的 OSSpinLock 自旋锁不建议被使用,以至于现在各大开源项目都抛弃了 OSSpinLock 的原因,我认为,我个人认为,就是因为自旋锁本身的巨大性能消耗导致的。虽然优先级反转问题可以通过提升持有锁的线程的优先级来解决,但苹果工程师不建议开发人员使用,苹果工程师不想把这个具有非常大的性能消耗的地雷提供给开发人员。因为即使解决了优先级反转问题,自旋锁消耗的代价依旧是巨大的。开发人员们动不动的用 OSSpinLock,复杂场景下卡出翔了也不好。
除非,自旋锁里的任务能够被快速执行完毕,这就是前面说的,即使用了自旋锁的高效,也降低了 CPU 消耗。苹果提供的互斥锁、信号量也都是基于自旋锁做的,肯定是苹果工程师们相信,对于这些锁的内部,自旋锁的效率非常高,所以让开发人员都使用这些锁,就不会懵逼情况下使用 OSSpinLock 卡出翔了。(以上纯属我个人认为,也是一派胡言,因为我没查到相关原因,但总比网上的解释靠谱些)
信号量
信号量应该是对所有高级语言影响最大的锁,其他的锁都是单进单出,信号量可以做多进多出,这就可以控制并发流量了。
1 | // 信号量实现,spinlock_t 即使用上面的自旋锁,spin_lock 和 spin_unlock 分别用于加锁核解锁 |
信号量就是上面代码实现里面说到的,是依靠自旋锁实现的。信号量很重要,它的流量控制能力,是其他锁没有的。已经足够高效,也没啥替代者。
互斥锁
“同一时刻只有一个线程执行” 这个条件非常重要,称为互斥。其实我理解,除了信号量语义上具有流量控制以外,其他的锁都可以称为互斥锁。因为信号量也有单个流量的控制,也可以说信号量也是互斥锁的一种。
这样看来,只要是锁,就应该互斥,就都属于互斥锁。因为锁的目标就是为了保障资源的安全,控制同一时间的线程访问数量为 1。
意义上,互斥锁实现的技术方案,就是内存中有一个地址,这个地址里面只有可能是 0 或者 1。如果是 1,就表示访问资源被加锁了,应该暂停访问。如果是 0,就表示资源无锁,可以正常访问。
所以上面的自旋锁就是完成这个技术方案的中流砥柱。
如果给自旋锁增加一些睡眠时间,就是 sleeplock。
如果给自旋锁增加等待队列,就是 mutex。
加锁的任务可能是线程,也可能是进程。那么操作系统就可以根据同一个进程加解锁设定临界区,同一个线程加解锁设定互斥量,这样就可以防止 A 加的锁被 B 给解了,增加并发并行安全性。
操作系统可以降低同一个线程获取锁的难度,即 A 线程获得了锁,在还没有解锁的时候,依旧可以再次获得锁,就生成了递归锁 。
操作系统可以将 mutex 的等待队列设置成串行,这样就是公平锁。还可以根据线程或者进程的优先级,设置成可调度锁。
以上的锁,都还只有一个获取锁的要素,即内存地址的值是 0 还是 1。高级语言在此基础上又增加一个对象的概念,即锁还需要和资源进行绑定,就变成了 synchronized 锁。
对读和写的多线程分别存储到两个队列中,就可以控制生成读写锁。
… 等等。从上面可以看出,只要在自旋锁的基础上,增加更进一步的约束限制,就多了一种锁出来。而业务需要多样性的锁,高级语言就可劲的造吧。
synchronized
synchronized 锁在 iOS 里面是性能最低的锁,不知道在 Java 里面是不是。但是 synchronized 又是最简单实用的锁。
前面说到,高级语言可以将锁和特定的资源进行绑定,这样可以进一步增强锁的实用性。一个锁可以绑定 N 个资源,代码如下:
1 |
|
上面总共定义了三把锁,分别保护三个资源。 1、2、3 是同一把锁,保护当前 Person 的每一个实例对象。 4 是一把锁,保护当前 Person.class 类。5 也是一把锁,保护 obj 局部对象。
synchronized 底层肯定还是要使用到自旋锁这些,但是保护对象存储在哪里?
只能存在内存里!而且对这块内存的操作,还得加锁,以防止这块内存区域被破坏。这块内存可能会通过 hashMap 实现。
一般是先获取受保护对象的内存地址,以该内存地址做为唯一值做 hash,将该 hash 放入一个数据结构中。
此数据结构一般肯定包含一个自旋锁,还有一个等待列表做睡眠唤醒用,再标记当前正在使用锁的线程是哪个等等额外的信息。
然后就将该数据结构存入 hashMap 中。为了 HashMap 的安全,对 hashMap 的修改本身还要加一层互斥锁。
所以 synchronized 肯定是比其他锁要慢的,慢的主要原因是需要额外的存储 / 读取 synchronized 要保护的那个对象的信息。HashMap 从数据结构上设计的再高效,可还是需要额外时间的。
这里 synchronized 还有一个使用风险,即 synchronized 锁的是对象。如果被锁的对象变成 nil 了,那么这个锁就不在生效了。获取 nil 的锁,会直接返回获取锁成功。
所以在考虑 synchronized 锁的对象的时候,一定要小心,不是什么对象都可以用来上锁的。还要防止对象被释放,开始有锁后面无锁的情况。
无锁 CAS
无锁又能够保障共享数据安全,其实是有些不现实的。Java 里面的 CAS 是为了保障业务代码的安全性问题,但是业务代码是非原子性的。上面已经举了很多例子阐述了非原子性操作在并发 & 并行上的不安全。
这里的无锁,其实指的是操作系统层面的无锁。就是说,其实有一把硬件层面的锁,在保障着业务代码处于原子性的操作之下。
硬件锁前面也分析过了,就是 lock,依靠总线锁或者缓存锁实现的原子性并行安全操作。lock 是用来锁单核场景下数据安全指令的,CAS 就是用到了 cmpxchg 比较交换指令。
cmpxchg 的使用在 “单核 - 原子操作 - cmpxchg” 已经详细说了,下面看看 Java 里面的 atomicInteger 的递增如何通过不加编程锁实现:
1 | // cmpxchg 比较交换指令 |
其实 Java 的 atomicInteger 实现,还是有不少损耗的。JVM 也是像上面代码一样,内部通过 do-while 循环实现的递增等安全操作。cmpxchg 不仅仅可以完成上面的操作,因为其特殊的 “比较交换” 的功能,可以在很多场景建立一个比较有效的数据安全隔离区。很多组件业务也都是通过 cmpxchg 建立比普通锁更加高效的原子性操作。
听说 CAS 的容易忽略的小问题很多,除了 ABA 问题,还有其他很多坑,一般不建议使用 CAS 做无锁。
对于 Java 的 CAS 实现,我是有个疑问,其实指令也提供了递增的原子操作指令,可以不用走 do-while 循环的,不知道为什么 JVM 没有用。
1 | __asm__ __volatile__ ("lock; addl &lock, n");// n 可以为一个整数,原子的将 lock 内存地址 +n |
高效解决共享数据安全的典范
关于锁,还有一个中断问题,我们只要在锁的前后关闭中断打开中断,就可以解决可能会因为中断导致的锁的获取紊乱。一般锁都已经做了中断处理。
1 | // 关闭中断 |
还有一个锁默认会做了的事情,就是可见性。所有的锁,都保持着比如 ARM 架构的 acquire 和 release 语义,和 Happens-before 类似。锁的实现里面,也和 valotile 一样增加了内存屏障。
而且,锁也会在获得锁和释放锁的前后,防止编译器或者解释器优化,以防止有序性。
这里要特别说明一单,可见性和有序性的处理,只针对获取锁之前和释放锁之后。被锁保护起来的区域,是没有做有序性和可见性的。因为这块区域有锁保护,都是单线程执行,基本可以保障安全。但也有例外,比如一会要说到的 “双重检查锁” 问题。
所以,有序性、可见性、原子性是递进的解决方案,他们的解决方案有包含。即如果要解决可见性问题,那么有序性问题就一定要先解决。如果要解决原子性问题,那么可见性也要先解决。
数据安全的处理方式随着范围的增加,效率也递减。所以数据安全处理第一步,就是不要跨范围处理,即能通过有序性解决,则不要通过可见性 / 原子性解决。能通过可见性解决,也不要通过原子性解决。
下面用 Java 里的双重锁验证,来做一个共享数据安全的说明:
1 | public class Singleton { |
上面是一个单例模式的 Singleton 单例对象获取,在多线程场景下可能会出错。因为两个同时获取 uniqueSingleton 均为 null,导致单例被创建两遍。
为了保障安全,就进一步的加锁:
1 | public synchronized Singleton getInstance() { |
增加 synchronized 锁之后,是数据安全的。但是每一个获取单例的线程都需要验证下锁,也会有性能开销。就进一步提出了双重检查,以降低原子性的覆盖区域:
1 | public class Singleton { |
这样就是的锁的覆盖范围最低了。只有初次一同获取单例对象的线程可能会加锁,后期获取单例的线程都是无锁的。
但是上面的双重检查还不是安全的。上面说到锁解决的有序性和可见性的解决方案是加锁前和释放锁后,对于锁的保护区域是没有的。这里的风险是 uniqueSingleton = new Singleton(); 本来应该被如下执行:
- 创建内存
- 初始化内存(初始化变量等)
- 给 uniqueSingleton 赋值创建内存的内存地址
但是因为有序性问题,前面的 2、3 有可能被颠倒,就会导致 A 线程给 uniqueSingleton 赋值了内存地址,但是还没初始化。这个时候 B 线程就会发现 uniqueSingleton 不为 null,那么在 B 正常使用 uniqueSingleton 的时候,就可能因为变量还未初始化导致 crash 等异常。
所以呢,volatile 来帮忙:将 uniqueSingleton 被 volatile 修饰后,就可以防止有序性问题,上面的 2 和 3 操作就不会颠倒了。1
private volatile static Singleton uniqueSingleton;
这样,“双重检测锁” 下的单例,就非常高效了。
iOS 的单例比 Java 的好用一些:
1 | + (id)sharedInstance { |
dispatch_once 直接做到了 “双重检测锁” 级别,开发人员直接用就好了。锁、有序性,都已经默认处理好了。dispatch_once 不和 Java 一样使用的 synchronized 锁,而是使用了上面提到的无锁方案。使用了 os_atomic_cmpxchg 和 os_atomic_xchg,所以 iOS 的单例和 Java 有一点不同,就是等待队列。synchronized 是有等待队列的,所以没抢到锁的线程应该会睡眠等待。dispatch_once 使用的原子指令,好像是没有做等待队列,和自旋锁有点相似,没抢到锁的线程会不断的重试。当然,前面说自旋锁的时候也说过,这种方式是最高效的,就是有点费 CPU。所以 dispatch_once 里面不要做复杂操作。
锁与数据结构的必要性
现实场景下,有序性和可见性都是顺带被解决的,大家都是用锁。因为锁在解决原子性的同时,都强制处理了加锁前和解锁后的有序性与可见性。所以锁是并发 & 并行编程下的万能钥匙,但也很容易产生性能瓶颈。
高级语言提供的锁的种类很多,选择一个业务场景大致需要的锁,然后搜一下这个锁的坑,基本上就可以避免很多意外了。把刚才的话再反过来说一下好加强记忆:要搜一下需要的锁有哪些坑,否则就会掉到很多坑里面。
通过严格控制原子性的粒度,不需要加锁的任务不要放进锁里。还可以用不同的锁对受保护资源进行精细化管理,能够提升性能,叫细粒度锁。
毕竟锁的性能真的不高,单线程完全没办法享受到近十年时间的 CPU 快速迭代的红利。
前面我们说 synchronized 的实现的时候,说到 synchronized 需要锁一个对象,那么在加锁和解锁过程中,这个对象就需要根据一定的规则存储到一块内存区域,然后再通过相同的规则从内存区域拿到这个对象。那么存储这个对象的内存区域,就很可能会成为 synchronized 的性能瓶颈。
在锁的内部要保障性能,被锁住的资源也要保障性能。否则就会出现高并发 & 高并行场景下,获得锁的线程一个时间片处理不完,睡眠一下,可能几个时间片又过去了。后面等待的睡眠线程又不断积压。
那现在就卷起来了,并发场景如果确定需要高性能,除了要选用高效率的锁,更优的数据结构和算法,也是关键。
用 iOS 里面的 YYCache 的内存缓存举例,YYCache 使用 pthread_mutex 互斥锁,原子性粒度控制的很小,在对数据进行操作的时候才开始加锁和解锁。
缓存使用来 LRU 算法,通过双向链表来实现数据对增和删的复杂度为 O (1)。
但是链表的查询复杂度是比较高的,因为链表无法做随机寻址,也没法用数组的空间局部性缓存加速。
所以作者通过空间换时间的方式,引入了 hash map,将缓存数据存入 hash map 中实现查询复杂度为 O (1)。
这样,整体内存缓存的数据的操作复杂度都将为 O (1)。
iOS Runtime 里面也是各种 hash table 和 hash map table 的使用,hash 函数为了高效,也尽可能使用位操作来计算索引值。
俄乌战争,我肯定是站在乌方的。但是我的角度是人民,而非国家。
俄方被制裁的严重,外企也走了,俄方的百姓也是极大的受害者。
乌方的百姓,很多都离开了家乡,他们更是战争的受害者。
我反对战争,因为受害者永远是人民和士兵。
只有领袖和将军,那些一心要扬名立万的恶魔,是我厌恶的根源。
国内的很多女性,对待普京的态度简直就是丈夫,虽然让我很心痛,但也理解你们,毕竟认知体系被圈养,这样也挺好,总比疯癫了好。
但是一个拿核威胁说事的领袖,会让我担心起自己的亲人和我自己。我想活着,也希望亲人活着。所以在我心中,普京是恶魔。
还有呢,我希望俄罗斯的老奶粉,不要再运到国内被那些俄粉们给孩子喝了。那不是奶粉,那不是奶粉,那不是奶粉。查查资料长长眼睛吧,为了孩子。
最近,很不太平,今年,应该又是更疯狂的一年吧。