函数调用栈虽然表面意思很容易理解,但是说到汇编层面,对于 call、ret 等命令的具体表现,还是有一些理解复杂度。基础汇编的角度理解函数调用过程 ,并给出有栈协程的汇编实现 。这样会对诸多高级语言的协程有进一步理解。
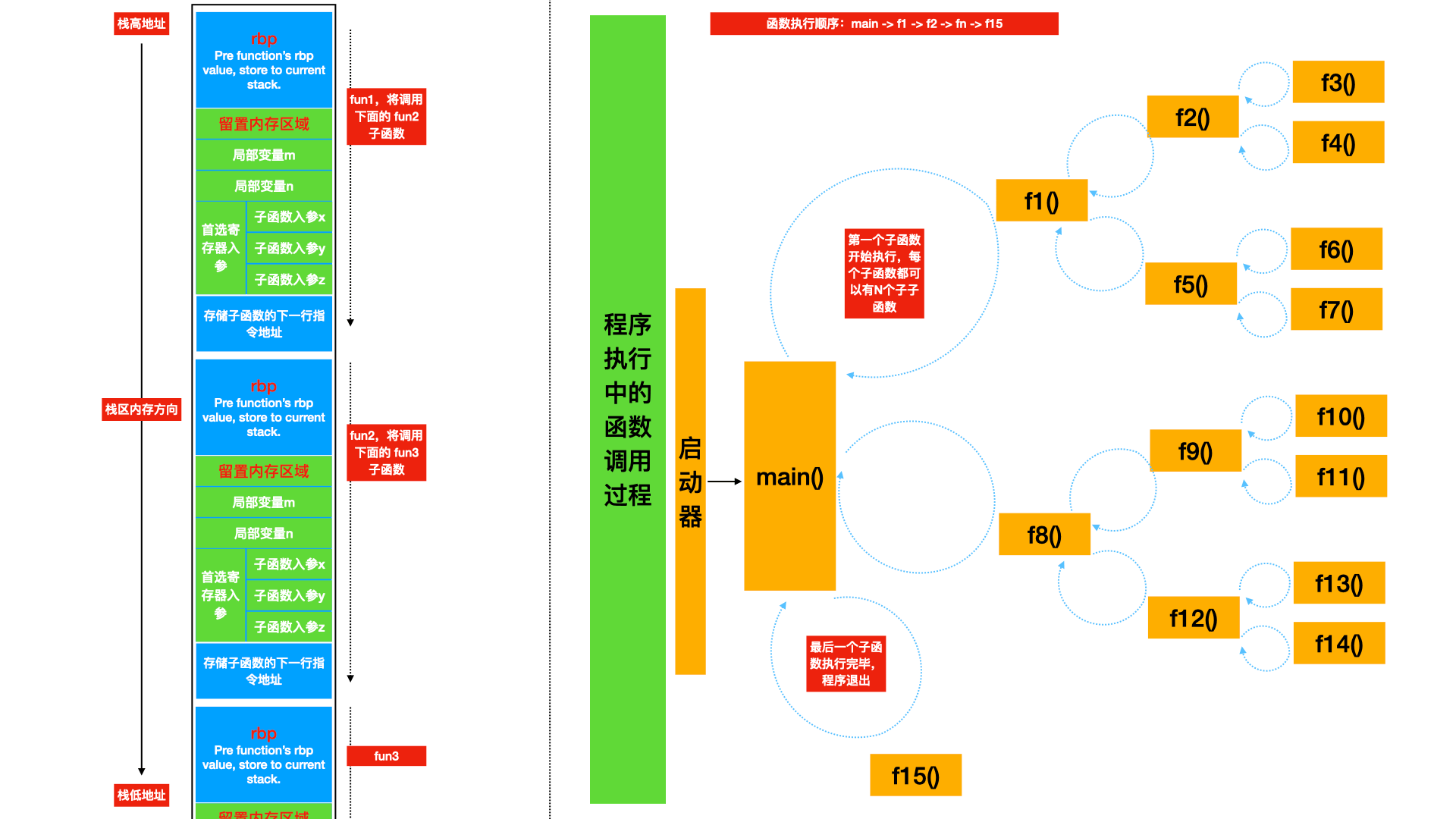
Start 函数执行过程大致如图中所示。其中函数栈的内存布局因操作系统和 cpu 架构的不同或许有差异,但不是重点。图中展示为 Mac + X86 系统。
这里就先引出一些名词,后面不在特别说明。
子函数调用前的准备 函数的作用是给予特定的输入,给出特定的输出。所以对子函数的调用,一个是传给子函数参数,一个是获取子函数的返回值。返回值在后面说,这里先说传参。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> int sub (int a, int b) { int t = a + b; printf ("The sub value is:%d\n" , t); return t; } int main (void ) { int a = 1 ; int b = 2 ; int p = sub(a, b); printf ("the return value is:%d\n" , p); return 0 ; }
示例代码中,main 对 sub 函数的调用,需要 a 和 b 两个参数,下面通过 main 的汇编,可以看下参数是如何准备起来的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 main: 0x100003f30 <+0 >: pushq %rbp 0x100003f31 <+1 >: movq %rsp, %rbp 0x100003f34 <+4 >: subq $0x10 , %rsp # 准备 0x10 大小即 16 字节的留置内存区域,用于存放各种参数 0x100003f38 <+8 >: movl $0x0 , -0x4 (%rbp) # 0 值写入,是默认预留的大小空间,无特别场景,不会使用 0x100003f3f <+15 >: movl $0x1 , -0x8 (%rbp) # 1 值写入变量 a,实际是写到栈内存中 rbp - 8 地址处 0x100003f46 <+22 >: movl $0x2 , -0xc (%rbp) # 2 值写入变量 b,实际是写到栈内存中 rbp - 12 地址处 0x100003f4d <+29 >: movl -0x8 (%rbp), %edi # 将 rbp - 8 地址处的内存值写入 edi 寄存器,即 1 写入 edi 0x100003f50 <+32 >: movl -0xc (%rbp), %esi # 将 rbp - 12 地址处的内存值写入 esi 寄存器,即 2 写入 edi 0x100003f53 <+35 >: callq 0x100003f10 ; sub at main.c:15 0x100003f58 <+40 >: movl %eax, -0x10 (%rbp) 0x100003f5b <+43 >: movl -0x10 (%rbp), %esi 0x100003f5e <+46 >: leaq 0x31 (%rip), %rdi ; "the return value is:%d\n" 0x100003f65 <+53 >: movb $0x0 , %al 0x100003f67 <+55 >: callq 0x100003f74 ; symbol stub for : printf 0x100003f6c <+60 >: xorl %eax, %eax 0x100003f6e <+62 >: addq $0x10 , %rsp 0x100003f72 <+66 >: popq %rbp 0x100003f73 <+67 >: retq
我们重点讨论 a 和 b 两个入参的准备过程,对于 push,call 等,后面会再说。上面的 <+4> 到 <+32> 行是入参的栈填充过程,到了 <+32> 行,就开始正式调用子函数了。寄存器可以用来传递参数给子函数 。
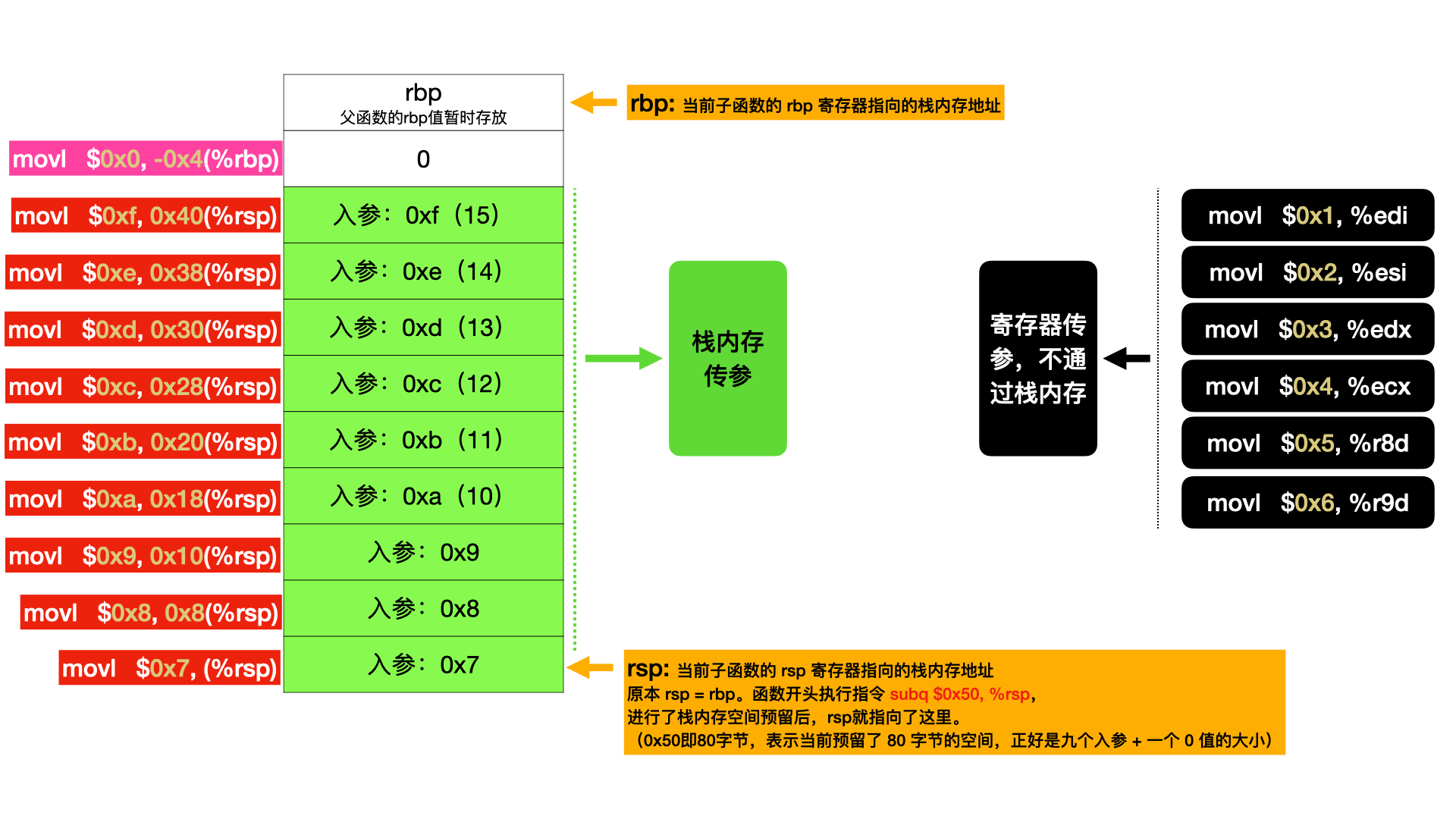
1 2 3 4 5 6 7 8 9 10 int sub (int a, int b, int c, int d, int e, int f, int g, int h, int i, int j, int k, int l, int m, int n, int o) { int t = a + b; printf ("The sub value is:%d\n" , t); return t; } int main (void ) { int p = sub(1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 ,11 ,12 ,13 ,14 ,15 ); printf ("the return value is:%d\n" , p); return 0 ; }
汇编如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 main: 0x100003ee0 <+0 >: pushq %rbp 0x100003ee1 <+1 >: movq %rsp, %rbp 0x100003ee4 <+4 >: subq $0x50 , %rsp # 预留 80 字节大小的栈内存空间 0x100003ee8 <+8 >: movl $0x0 , -0x4 (%rbp) # 0 值写入,默认预留的大小空间,无特别场景,不会使用 0x100003eef <+15 >: movl $0x1 , %edi # 参数入 寄存器 0x100003ef4 <+20 >: movl $0x2 , %esi # 参数入 寄存器 0x100003ef9 <+25 >: movl $0x3 , %edx # 参数入 寄存器 0x100003efe <+30 >: movl $0x4 , %ecx # 参数入 寄存器 0x100003f03 <+35 >: movl $0x5 , %r8d # 参数入 寄存器 0x100003f09 <+41 >: movl $0x6 , %r9d # 参数入 寄存器 0x100003f0f <+47 >: movl $0x7 , (%rsp) # 参数入 栈内存 0x100003f16 <+54 >: movl $0x8 , 0x8 (%rsp) # 参数入 栈内存 0x100003f1e <+62 >: movl $0x9 , 0x10 (%rsp) # 参数入 栈内存 0x100003f26 <+70 >: movl $0xa , 0x18 (%rsp) # 参数入 栈内存 0x100003f2e <+78 >: movl $0xb , 0x20 (%rsp) # 参数入 栈内存 0x100003f36 <+86 >: movl $0xc , 0x28 (%rsp) # 参数入 栈内存 0x100003f3e <+94 >: movl $0xd , 0x30 (%rsp) # 参数入 栈内存 0x100003f46 <+102 >: movl $0xe , 0x38 (%rsp) # 参数入 栈内存 0x100003f4e <+110 >: movl $0xf , 0x40 (%rsp) # 参数入 栈内存 0x100003f56 <+118 >: callq 0x100003e90 ; sub at main.c:10 0x100003f5b <+123 >: movl %eax, -0x8 (%rbp) 0x100003f5e <+126 >: movl -0x8 (%rbp), %esi 0x100003f61 <+129 >: leaq 0x32 (%rip), %rdi ; "the return value is:%d\n" 0x100003f68 <+136 >: movb $0x0 , %al 0x100003f6a <+138 >: callq 0x100003f78 ; symbol stub for : printf 0x100003f6f <+143 >: xorl %eax, %eax 0x100003f71 <+145 >: addq $0x50 , %rsp 0x100003f75 <+149 >: popq %rbp 0x100003f76 <+150 >: retq
可以发现,这边测试环境下,传参超过 6 个,就需要写入栈内存。超出的部分,就不能通过寄存器传参了。
在上面有 a 和 b 两个变量的例子中 (int a = 1; int b = 2; int p = sub(a, b);),数据虽然也写到了 -0x8(%rbp) 和 -0xc(%rbp) 栈内存中,但那是因为 a /b 两个变量当前函数需要使用,不得不写入栈内存,如果像下面这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int sub (int a, int b) { int t = a + b; return t; } int main (void ) { int p = sub(1 , 2 ); printf ("the return value is:%d\n" , p); return 0 ; } ############ main: 0x100003f30 <+0 >: pushq %rbp 0x100003f31 <+1 >: movq %rsp, %rbp 0x100003f34 <+4 >: subq $0x10 , %rsp 0x100003f38 <+8 >: movl $0x0 , -0x4 (%rbp) 0x100003f3f <+15 >: movl $0x1 , %edi # 直接写入 edi 寄存器,不在写入栈内存 0x100003f44 <+20 >: movl $0x2 , %esi # 直接写入 esi 寄存器,不在写入栈内存 0x100003f49 <+25 >: callq 0x100003ef0 ; sub at main.c:15
这里就很清晰了,1 和 2 两个参数,都是直接写入寄存器中的,不会再写到栈内存中。
对于 sub(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15) 的子函数调用,栈内存如下:
备注 1:
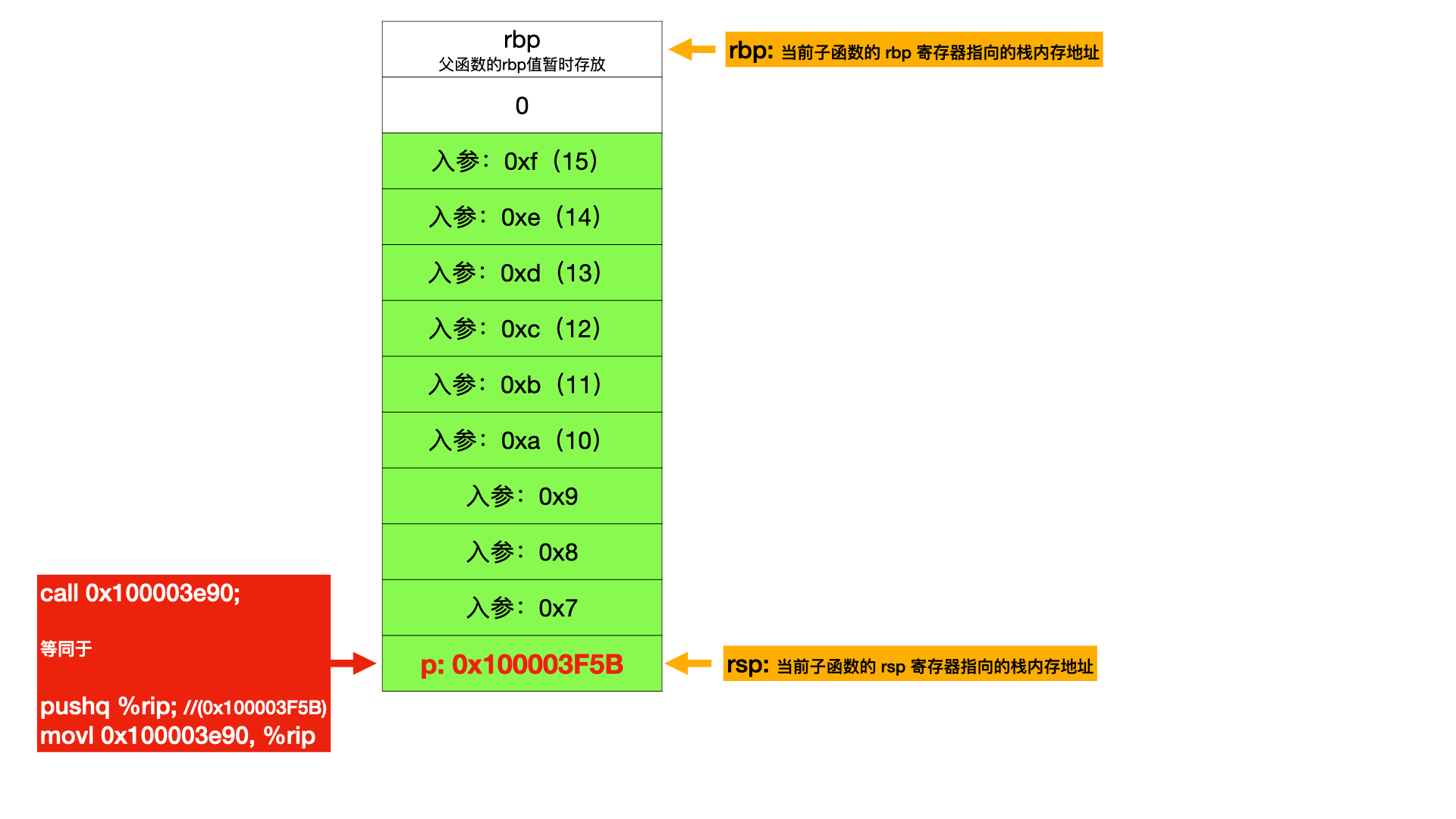
子函数被调用 通过 call 指令即可完成函数帧的切换,即可以正常调用子函数了。上面例子中 callq 0x100003e90 ; sub at main.c:10 即表示子函数跳转。
而这两个操作都是在 call 指令中完成的,所以 call 指令实际上等同于下面操作:
1 2 pushq %rip movl <子函数内存地址> %rip
对于 sub(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15) 的子函数调用,栈内存如下:
这里再说明一下,为什么要先把 ip 程序寄存器的值写入栈内存,然后又写入新的值进去。0x100003f5b。这里因为函数调转,不能执行下一条指令了,所以需要把 ip 寄存器先入栈内存暂时存储,即 pushq %rip。movl 0x100003e90, %rip。
这里还有一个隐藏的点,即 rsp 寄存器变化了。原先指向入参0x7 的,这个时候就指向下一条指令的地址 ,即 0x100003f5b 位置。rsp 之所以能够变化,是因为 pushq %rip 指令会改变 rsp 的指向,下面会说到。
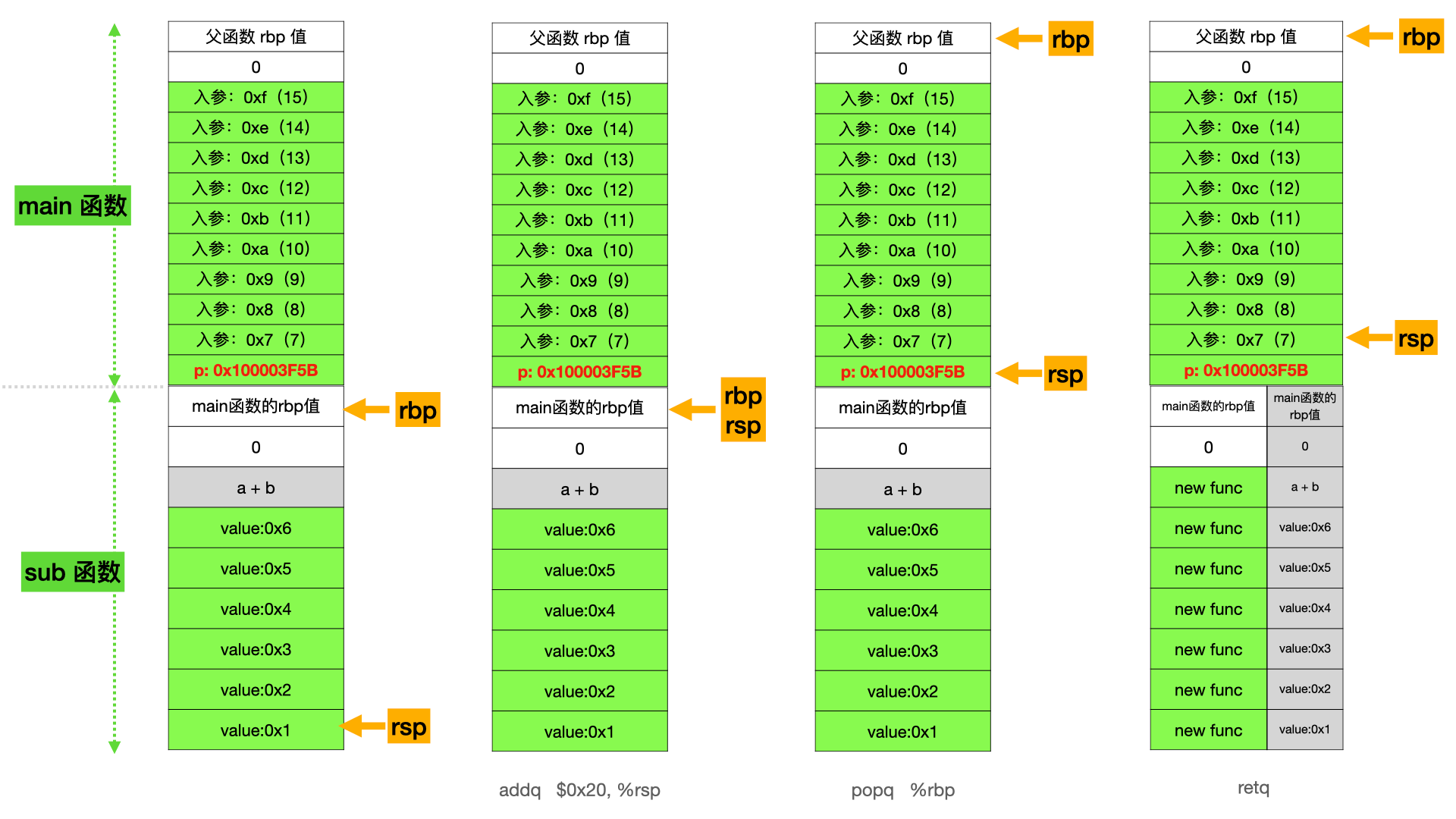
子函数执行中 这里就是重点了,rbp 和 rsp 有非常大的用途。它是函数调用栈的核心,也是理解协程的基础。
在 rbp 基础上增加值偏移,可以访问到父函数的栈内存数据(如入参)。
在 rbp 基础上减少值偏移,可以访问到子函数的栈内存数据(如局部变量)。
rbp 本身指向父函数的 rbp 的存储地址,用于子函数执行完毕后回到父函数时的 rbp 还原。
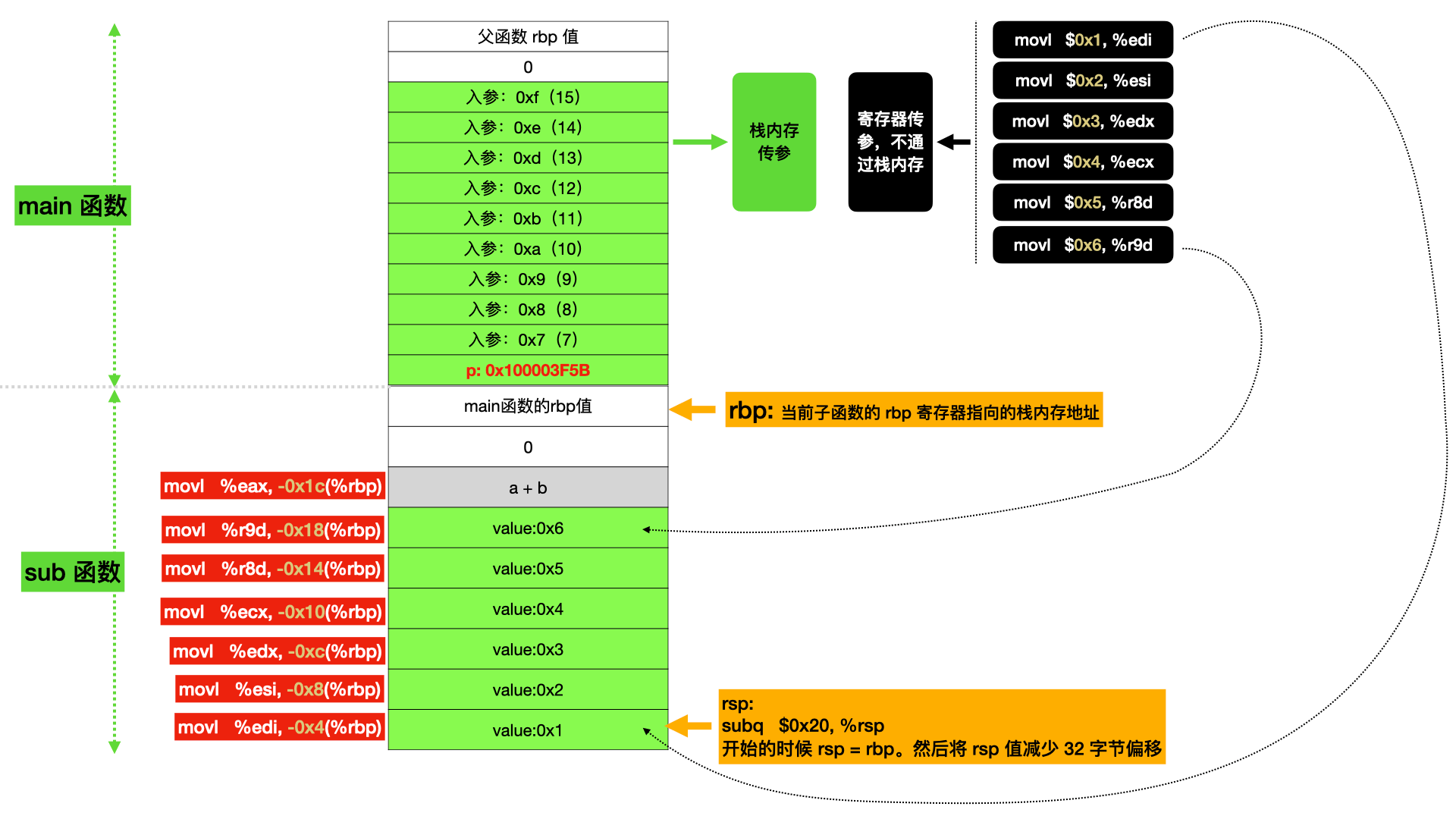
下面看下 sub 函数的汇编:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 int sub (int a, int b, int c, int d, int e, int f, int g, int h, int i, int j, int k, int l, int m, int n, int o) { int t = a + b; printf ("The return value is:%d\n" , t); return t; } sub: 0x100003e80 <+0 >: pushq %rbp # 以上,将父函数的 rbp 值存入栈底 0x100003e81 <+1 >: movq %rsp, %rbp # 以上,将当前函数的 rsp 值赋予 rbp,此时 rbp 是子函数的栈底 0x100003e84 <+4 >: subq $0x20 , %rsp # 以上,将 rsp 值减少 32 字节偏移,开辟栈预留内存空间 0x100003e88 <+8 >: movl 0x50 (%rbp), %eax 0x100003e8b <+11 >: movl 0x48 (%rbp), %eax 0x100003e8e <+14 >: movl 0x40 (%rbp), %eax 0x100003e91 <+17 >: movl 0x38 (%rbp), %eax 0x100003e94 <+20 >: movl 0x30 (%rbp), %eax 0x100003e97 <+23 >: movl 0x28 (%rbp), %eax 0x100003e9a <+26 >: movl 0x20 (%rbp), %eax 0x100003e9d <+29 >: movl 0x18 (%rbp), %eax 0x100003ea0 <+32 >: movl 0x10 (%rbp), %eax # 以上,根据 栈底 rbp 做增加值偏移,获取父函数的栈内存数据,即入参 0x100003ea3 <+35 >: movl %edi, -0x4 (%rbp) 0x100003ea6 <+38 >: movl %esi, -0x8 (%rbp) 0x100003ea9 <+41 >: movl %edx, -0xc (%rbp) 0x100003eac <+44 >: movl %ecx, -0x10 (%rbp) 0x100003eaf <+47 >: movl %r8d, -0x14 (%rbp) 0x100003eb3 <+51 >: movl %r9d, -0x18 (%rbp) # 以上,将入参寄存器的值存入当前栈内存空间,做减小值偏移 0x100003eb7 <+55 >: movl -0x4 (%rbp), %eax 0x100003eba <+58 >: addl -0x8 (%rbp), %eax # 以上,完成 a + b 操作 0x100003ebd <+61 >: movl %eax, -0x1c (%rbp) # 以上,将 a + b 的结果,存入栈内存空间 0x100003ec0 <+64 >: movl -0x1c (%rbp), %esi 0x100003ec3 <+67 >: leaq 0xd4 (%rip), %rdi ; "The return value is:%d\n" 0x100003eca <+74 >: movb $0x0 , %al 0x100003ecc <+76 >: callq 0x100003f7e ; symbol stub for : printf # 以上,调用 printf 函数开始打印 a + b 的值 0x100003ed1 <+81 >: movl -0x1c (%rbp), %eax 0x100003ed4 <+84 >: addq $0x20 , %rsp 0x100003ed8 <+88 >: popq %rbp 0x100003ed9 <+89 >: retq # 以上,是子函数执行结束后的父函数还原,下一趴说
汇编注释做了说明,主要就是 rbp 值和 rsp 值的变化,如下所示:
这里有一个点,从汇编里面不太容易看出来 rsp 的变化。在子函数没有调用之前,rsp 的值是指向 main 函数栈顶的 p: 0x100003F5B。在调用 pushq %rbp 将父函数的 rbp 值存入栈底后,rsp 的值就已经变化了。因为 push 实际上是完成了两个工作,如下:
1 2 3 4 5 6 pushq %rbp = subq $0x8 , %rsp movl. %rbp, %rsp
这两个步骤,一个将 rsp 减大小偏移 8 个字节,一个将 父函数的 rbp 值写入到偏移后的栈内存里面。
然后执行 movq %rsp, %rbp 是为了将 rbp 置为当前子函数栈的栈底,即此时 rbp = rsp。到这里,子函数栈的两个重要参数 rbp 和 rsp 就已经设置好了。subq $0x20, %rsp,预留内存空间的方式就是将 rsp 做减大小偏移。
有一个注意点,就是预留大小并不一定非要 rsp 做减大小偏移 ,其实只要能够持续稳定的访问到一个栈内存地址即可,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int sub (int a, int b, int c, int d, int e, int f, int g, int h, int i, int j, int k, int l, int m, int n, int o) { int t = a + b; return t; } `sub: 0x100003e90 <+0 >: pushq %rbp 0x100003e91 <+1 >: movq %rsp, %rbp 0x100003e94 <+4 >: movl 0x50 (%rbp), %eax 0x100003e97 <+7 >: movl 0x48 (%rbp), %eax 0x100003e9a <+10 >: movl 0x40 (%rbp), %eax 0x100003e9d <+13 >: movl 0x38 (%rbp), %eax 0x100003ea0 <+16 >: movl 0x30 (%rbp), %eax 0x100003ea3 <+19 >: movl 0x28 (%rbp), %eax 0x100003ea6 <+22 >: movl 0x20 (%rbp), %eax 0x100003ea9 <+25 >: movl 0x18 (%rbp), %eax 0x100003eac <+28 >: movl 0x10 (%rbp), %eax 0x100003eaf <+31 >: movl %edi, -0x4 (%rbp) 0x100003eb2 <+34 >: movl %esi, -0x8 (%rbp) 0x100003eb5 <+37 >: movl %edx, -0xc (%rbp) 0x100003eb8 <+40 >: movl %ecx, -0x10 (%rbp) 0x100003ebb <+43 >: movl %r8d, -0x14 (%rbp) 0x100003ebf <+47 >: movl %r9d, -0x18 (%rbp) 0x100003ec3 <+51 >: movl -0x4 (%rbp), %eax 0x100003ec6 <+54 >: addl -0x8 (%rbp), %eax 0x100003ec9 <+57 >: movl %eax, -0x1c (%rbp) 0x100003ecc <+60 >: movl -0x1c (%rbp), %eax 0x100003ecf <+63 >: popq %rbp 0x100003ed0 <+64 >: retq
上面的 sub 函数,注释掉 printf 子函数调用。这个时候,就不会有 subq $0x20, %rsp 和 addq $0x20, %rsp 两个 rsp 减大小偏移的操作了。因为 sub 就是当前函数调用栈的最后一个子函数,它可以保障当前函数执行过程中的栈数据是稳定可靠的,因为不会再有子函数来打扰它。但是 sub 函数依旧可以通过 -0x4(%rbp) 方式访问当前栈内存空间。
子函数执行结束后 快要接近尾声了。
子函数需要把返回值返回到父函数,是通过 eax 寄存器实现的。
1 2 3 4 5 6 7 8 9 10 11 12 sub: 0x100003eb7 <+55 >: movl -0x4 (%rbp), %eax 0x100003eba <+58 >: addl -0x8 (%rbp), %eax # 以上,完成 a + b 操作 0x100003ebd <+61 >: movl %eax, -0x1c (%rbp) # 以上,将 a + b 的结果,存入栈内存空间 0x100003ed1 <+81 >: movl -0x1c (%rbp), %eax # 以上,从栈内存空间中取出返回值,存入 eax 寄存器。父函数通过eax 拿到子函数的返回值。 main: 0x100003f5b <+123 >: movl %eax, -0x8 (%rbp) # 父函数拿到 eax 返回值,目前是写入栈内存。也可以直接使用,看代码逻辑决定。
目前子函数快要执行完毕后,参考上面的汇编,最后还需要执行三个指令:
1 2 3 4 0x100003ed4 <+84 >: addq $0x20 , %rsp0x100003ed8 <+88 >: popq %rbp0x100003ed9 <+89 >: retq# 以上,是子函数执行结束后的父函数还原
其中做了这么几件事情:
还原父函数的 rbp
还原父函数的 rsp
使得父函数继续执行下去
其中 pop 和 ret 也有多个意图,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 popq %rbp = movl %rsp, %rbp addq $0x8 , %rsp ------------ retq = movl %rsp, %rip addq $0x8 , %rsp
可以发现,pop 和 ret 都会操作 rsp 寄存器,将 rsp 寄存器的值做增大小偏移,从而还原到父函数的 rsp 状态。
最后将 call 指令存储到栈内存的下一行指令地址写回到 ip 寄存器,使得 CPU 从子函数调用处继续执行下去。
有栈协程如何实现 函数调用的过程,核心在于维护一个子函数的栈,在这个栈里面,会同样使用父函数 (父栈) 已经使用过的寄存器等硬件而互不干扰,还会将父栈必要的信息给予保留,如 rbp。
而协程的实现,可以在父子函数之间不停的跳跃,它的实现依旧可以通过函数调用栈来完成。
如果要实现这种效果,需要下面几个点要先解决:
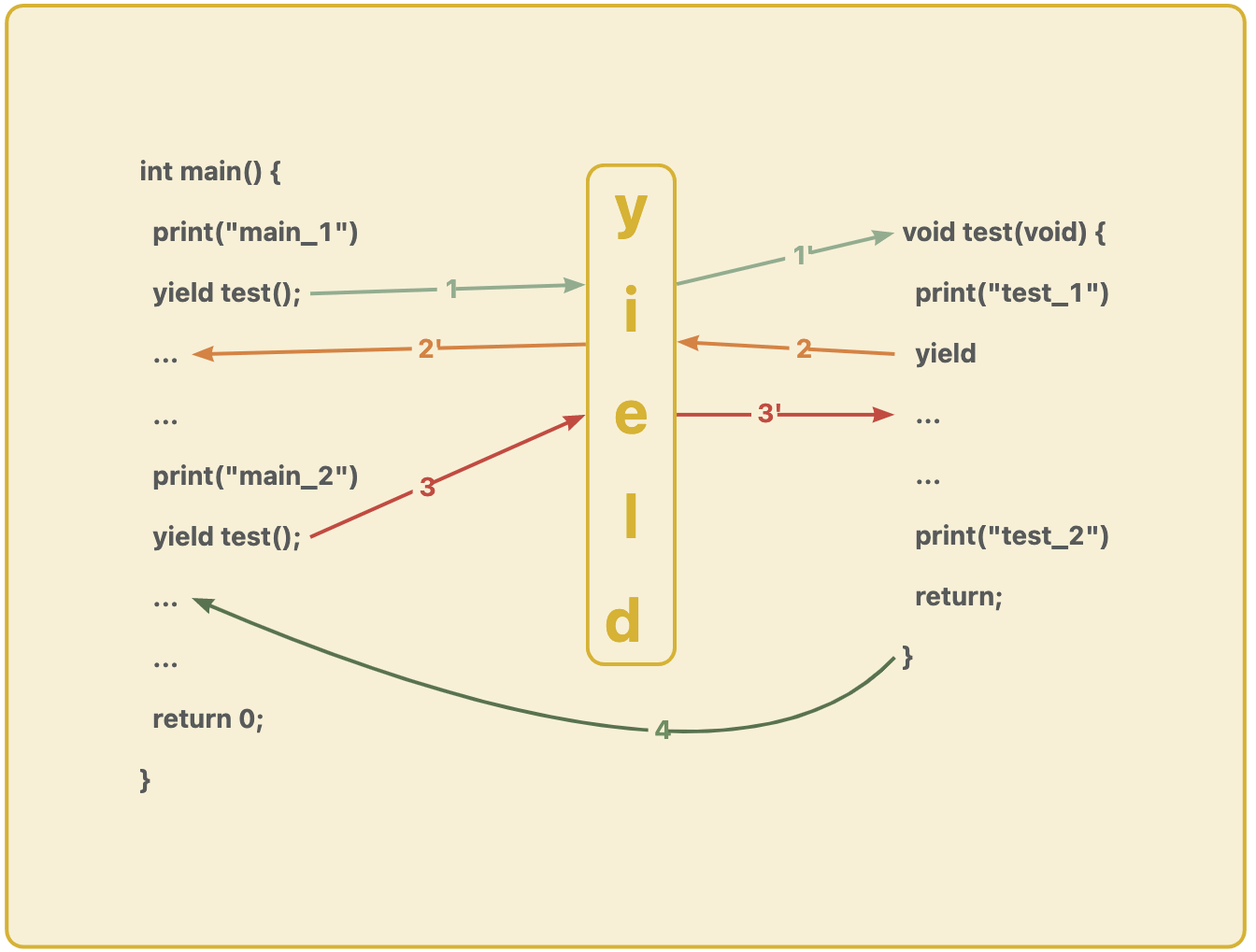
两个函数不停跳跃,一定有一个地方实现了 ret 指令。这个 ret 指令实现的地方,也就是 yield (一般都通过这个来让出当前协程) 实现的地方。
yield 无法在当前函数中实现 ret 指令。因为 yield 如果直接表达了 ret (yield 汇编结果),那么 yield 就具有和 return 一样的效果,即当前函数意义上执行完毕了。
所以,yield 或许可以被实现为一个中间函数。这个中间函数内部实现 ret 指令,并强制跳转到另一个函数处。
在进入 yield 之前,先回顾一下上面提到的函数栈中使用的汇编指令。因为其中有一个关键寄存器 rsp 需要重点说明下。用最简单的一个例子来看:
1 2 3 4 5 #include <stdio.h> void test(void) { } int main(int argc, const char * argv[]) { test(); return 0; }
这里 test 函数的汇编如下:
1 2 3 4 5 TestProject`test: 0x100003f70 <+0>: pushq %rbp 0x100003f71 <+1>: movq %rsp, %rbp 0x100003f74 <+4>: popq %rbp 0x100003f75 <+5>: retq
在 main 里面进入 test 函数后,什么都没有执行,汇编非常简洁。这里说一下 rsp 为什么非常重要:
rsp 在当前栈向下增长的过程中,表示当前栈的内存空间。
rsp 代替 rbp。rbp 是栈底寄存器,上面说到可以对它增减偏移以连接父函数和子函数 。rbp 也是可以通过 rsp 来间接获取的。上面子函数执行结束后章节中有一个汇编 addq $0x20, %rsp,就是将 rsp 移动到 rbp 的位置。可以在使用 rbp 的时候,通过 0x50(%rbp) 来间接拿到栈底点。
rsp 决定最后的回跳地址。ret 指令执行的过程,是对 rsp 操作的。详见上面的 movl %rsp, %rip & addq $0x8, %rsp
所以,如果在 yield 中间函数的设计中,我们若能够巧妙的设置 rsp,就可以让当前 yield 回跳到任意需要的位置,从而实现上面图中的协程效果。比如下面的伪码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 TestProject`yield: 0x100003f70 <+0>: pushq %rbp 0x100003f71 <+1>: movq %rsp, %rbp // 上面两个用于将父函数 rbp 存储,当前 rsp 置于栈底,即操作 rsp 和操作 rbp 等价。 mov %rsp, addressM // 将父函数的 rbp 暂存 M 地址中。通过这个缓存的 M,可以拿到父函数的回跳地址。(rbp - 1 位置存储回跳执行地址,IP 程序计数器的值。) mov addressN, %rsp // 将 rsp 修改为新函数的钩子地址(需要特别配制) 0x100003f74 <+4>: popq %rbp 0x100003f75 <+5>: retq // 这时候,pop %rbp 会将钩子地址处的相关数据设置到 rbp,作为新的栈底。 // ret 会将钩子地址处的相关数据设置为 IP 程序计数器并跳转过去 // rsp 已经在上一步被钩子地址填充好 // 函数跳转的三要素,基本都配置完成了,坐等跳转发生。
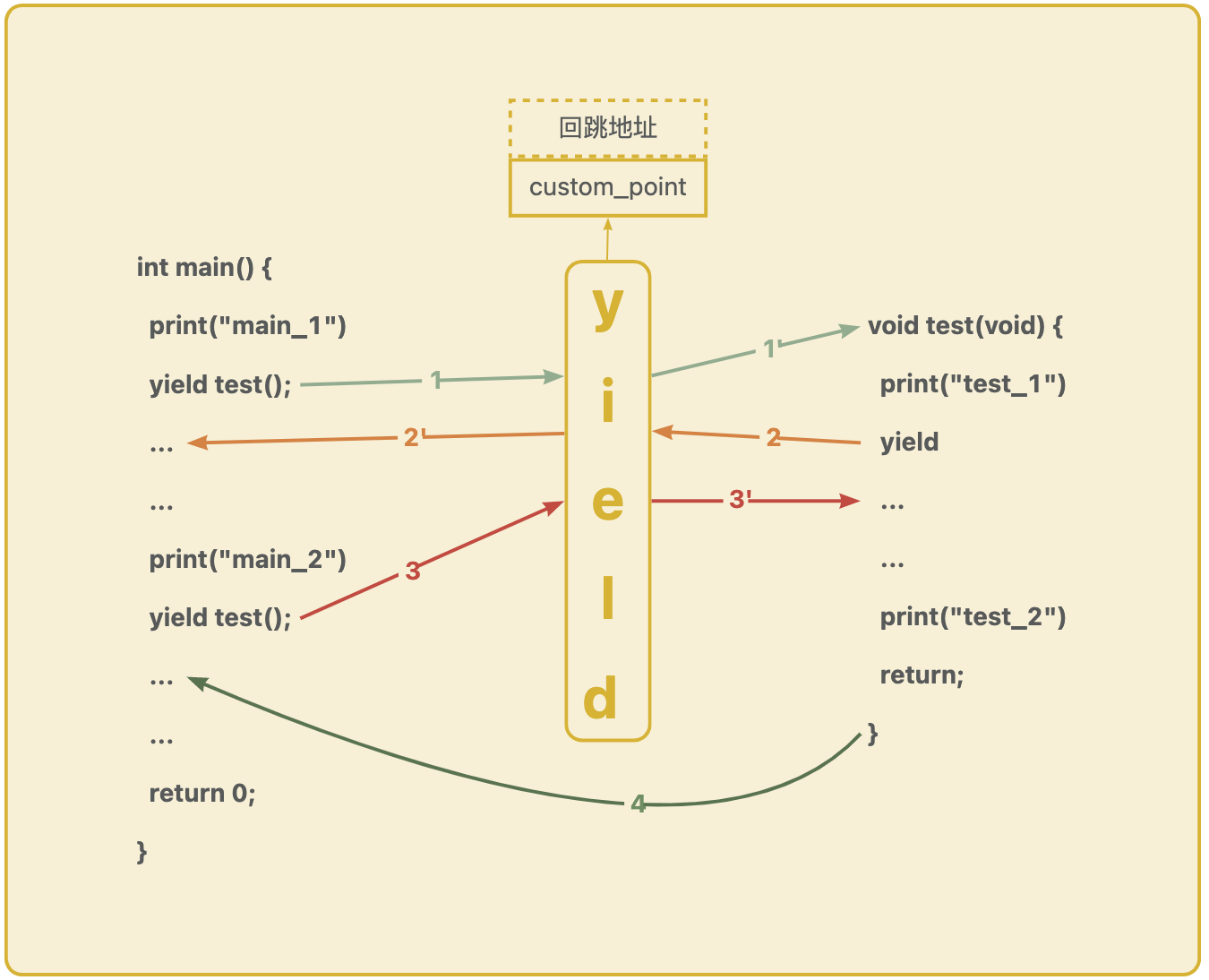
如上面注释里面说明的,只需要有一个巧妙的数据,这份数据能够被 pop rbp 和 ret 的执行逻辑获取到。那么,只需要控制 rsp 以指向这份巧妙的数据,就可以实现自定义跳转。
这里,找一个全局内存区域 custom_point,用于存放每次 yield 时候 rsp 数据。custom_point 中取出老数据并设置给 rsp,然后再将 _rsp 存储进 custom_point,最后坐等 ret 跳转发生。
图中第二步,test () yield 到 main () 的时候,yield 拿到 test () 的 rbp 并存储。(rbp -1 即这一次的回跳地址,图中的 ... 部分)
图中第三步,main () yield 到 test () 的时候,yield 拿到先前存储的 test () 的 rbp 并设置到 rsp 里面,ret 的时候直接跳转到 ... 部分
如此,就可以不间断的完成两个函数之间的跳转。这也是有栈协程的方案。
原来,取蚕丝的时候,需要把蚕宝用热水杀死在茧内,以获得完整的丝。