计算机字符编码与内存编码 - Unicode、UTF8、String
只要使用电子产品,每时每刻都在和字符打交道。目之所及的字符,在存储、显示、执行等环节都离不开编码的支持。
但对于字符编码,也会有一些误区,比如:Unicode 和 UTF 是否都是编码、字节和编码的关系、āáǎà 的音标字符表达、内存字符编码 等等。
本文将循序渐进的,从 ASCII/ Unicode 介绍到 UTF8/16/32,以及文本二进制存储和 URL 编码 / 多次编码等场景,最后解释内存中字符串的编码格式。
每个环节都通过二进制调试的方式给予实际的场景输出,争取一遍将编码吃透。
Unicode
ASCII 是大学计算机教科书入门知识点,如果不联系上码位和 Unicode ,还是不好理解的。知道有这个东西在,但是怎么玩的却不是很清楚。
比如,C 语言是古老的伟大语言,印象中 C 语言教程都使用的 ASCII 字符,没有出现中文。那么 C 语言可以通过 printf 输出中文吗?
ASCII 和 Unicode 都是字符集,又称码表,字符集可以看做一个数组,里面的每个元素称为 码位 / 码点 /Code Point。
字符集是约定俗成的一套全世界都默认遵守的规则矩阵,这套规则矩阵里面的每个元素(码位),都表示一个特定的符号含义且不可改变。
ASCII 并不是表示 0-9 或者 a-z 这些我们肉眼看到的符号。这些符号是对于人类友好的视觉表达。
比如 @ 字符,可以脑海里回忆一下,这些年是不是见过很多样式的 @ 符号。但这些不同的视觉表达并不是 ASCII。@ 字母的 ASCII 码位是 0x40 (64),这个才是 ASCII 的含义。即 ASCII 定义了 0x40 这个码位只能用来表达 @ 这个字母的含义,不能表示 a/b 或其他。
从 ASCII 进化到 Unicode,就是增加了很多码位,以建立全世界的规则矩阵,大家都得遵守。
emoji 等各种表情符号就是 Unicode 里面的特定码位。应用层识别到具体的表情码位后,做的符号映射和视觉显示。
切换字体,也同样是对同一个码位,做不同的视觉表达。
所以,这里很重要的一点,是对 码位 的理解。码位才是每一个字符的互联网流通语言。后面介绍的文本文件存储、二进制文件存储等,都离不开码位。
对于字符来说,计算机也只对码位做存储,在没有 Unicode 的时候,计算机存储的就是 ASCII 里面的共计 256 个码位 (00000000 - 11111111)。
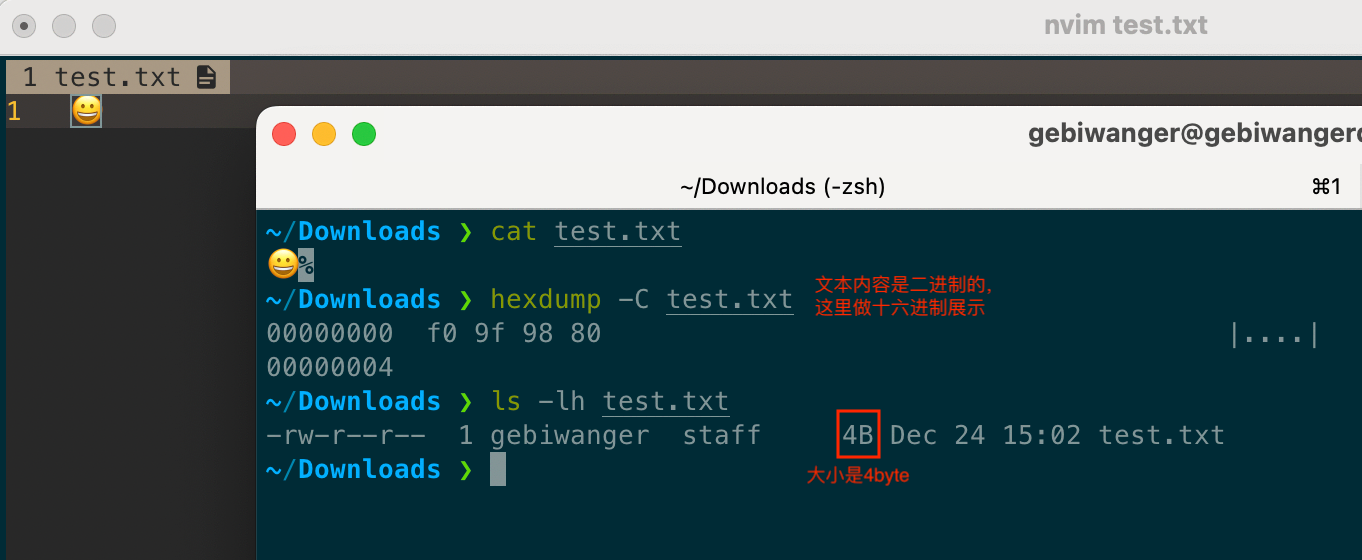
下面例子中,将 abcde 存储到文件中,共计 5 个字节。通过 xxd 命令确认每个字节的存储内容都是这些字母的 ASCII 码位。(后面统一使用十六进制 hexdump 查看)。
1 | > cat test.txt |
有了 Unicode 之后,当然也可以对 Unicode 的码位做存储,这是最简单的复刻 ASCII 的模式,但这有一些问题。
Unicode 采用平面码位设计,共计 17 个平面,每个平面有 65536 个码位,共计 1114112 个码位。
二进制是:xxxxx 00000000 00000000 - xxxxx 11111111 11111111。xx 表示平面,从 0 - 16,范围是:00000 - 10000,绝大部分字符的 xx 都是 00000,称为 零平面。
如果要将 Unicode 的码位做存储,为了补齐每个字节,那么每个码位都需要 3 字节的存储空间。
这对于磁盘和内存都无法接受,尤其英文是世界的流通语言,在 ASCII 的时候,它们仅需 1 个字节的存储空间。
所以,这就需要对 Unicode 的码位进行压缩,也就是下面要说的 UTF 编码了。
再进入到下面之前,先来熟悉几个 Unicode 码位,后面会频繁的使用这几个字符做说明。
| 字符 | Unicode 码位 十六进制 | Unicode 码位 二进制 |
|---|---|---|
| a | 0x61 | 00000 00000000 01100001 |
| 中 | 0x4e2d | 00000 01001110 00101101 |
| 😀 | 0x1f600 | 00001 11110110 00000000 |
UTF
UTF,是字符编码,是一套算法实现,实际上是对码位进行编码。
它们服务于前面说到的 Unicode 字符集,具体职责是:如何对码位进行压缩,以节省空间,并兼顾效率 (编码 & 解码) 。
这里介绍一下 UTF-8 和 UTF-16。
UTF-8
UTF-8 使用多字节来表达一个 Unicode 码位
| 字节数 | Unicode 码位 | 十进制 | UTF-8 编码 |
|---|---|---|---|
| 1 | 000000-00007F | 0-127 | 0xxxxxxx |
| 2 | 000080-0007FF | 128-2047 | 110xxxxx 10xxxxxx |
| 3 | 000800-00FFFF | 2048-65535 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 010000-10FFFF | 65536-1114111 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
这里举几个例子,可以详细的看下:
| 符号 | 码位 | 字节 | UTF-8 编码 | 十六进制 |
|---|---|---|---|---|
| a | 00000000 00000000 01100001(0x61) | 1 | 01100001 | 0x61 |
| 中 | 00000000 01001110 00101101(0x4E2D) | 3 | <1110>0100 <10>111000 <10>101101 | 0xE4B8AD |
| 😀 | 00000001 11110110 00000000(0x1F600) | 4 | <11110>000 <10>011111 <10>011000 <10>000000 | 0xF09F9880 |
可以换算一下,将 UTF-8 的二进制编码,去掉前面的标记位,就是原本的码位二进制。
UTF-16
UTF-16 是固定编码,要么是 2 字节,要么是 4 字节,根据平面来决定。对于第一个平面 (零平面) 均使用 2 字节,其他的使用 4 字节。
但是 UTF-16 有个默认 2 字节前缀,即最小也是 4 字节。还是上面的例子:
| 符号 | 码位 | 字节 | UTF-8 编码 | 十六进制 |
|---|---|---|---|---|
| a | 00000000 00000000 01100001(0x61) | 2 | 00000000 01100001 | 0x0061 |
| 中 | 00000000 01001110 00101101(0x4E2D) | 2 | 01001110 00101101 | 0x4E2D |
| 😀 | 00000001 11110110 00000000(0x1F600) | 4 | <11011>000 00111101 <110111>10 00000000 | 0xD83D 0xDE00 |
这里有个小小的注意点,对于 UTF16 来说,零平面的码点,码位和 UTF16 值,是一样的。这一点对于后面要说到的 内存编码 很重要,这里先了解下,后面再细说。
UTF 小结
UTF32 就不介绍了,用的也少,4 个固定字节大小,也没什么特别要说的。比较下 UTF8 和 UTF16 的差异:
- UTF-8 占用空间最小,但是解析速度低,因为不能按序解析字节,UTF-8 对字节大小是变化非常大的。(空间小,适合磁盘存储)
- UTF-16 占用空间中等,解析速度快。因为更多的码位用 2 个字节表示,字节大小基本固定(少部分字符通过 4 个字节表示),解析非常快。(速度快,适合编解码)
- UTF-32 占用空间最大,解析速度最快。一个码位用 4 个字节表示,字节大小全部固定,解析非常快。(空间太大,基本不用)
整体来说,UTF8 对英文场景比较合适,可以显著的减少体积,因为英文基本都是 1 字节来表达。
而 UTF16 对中文场景比较合适,中文在 UTF8 一般都需要 3 字节,在 UTF16 里面一般只需要 2 字节。
这种差异不仅体现在存储上,在内存中也会有体现。比如程序中比较 中、文 两个汉字的大小,对于 UTF8 需要比较 3 个字节,而 UTF16 只需要比较 2 字节。这点在下面的内存编码中会介绍。
URL
对字符非常敏感的一个环境,就是 URL。URL 对组成其内容的元素要求非常严格,只允许下面这些字符:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
a b c d e f g h i j k l m n o p q r s t u v w x y z
0 1 2 3 4 5 6 7 8 9
- _ . ~
ASCII 字符集也没有全部包含,只有上面这些字符是可以在 url 里面直接使用的。不在这个列表里面的,全部都需要进行百分号转码。
百分号转码是 URL 特有的一套规则,默认使用 UTF-8 作为字符编码依据,对编码后的字节产物,进行百分号分割。
百分号转码后还需要还原回去,这套流程分别叫做 URL Encoding 和 URL Decoding。
所以,对 URL 来说,它使用的编解码是 URL Encoding 和 URL Decoding,这套编码内部通过百分号拼接 UTF-8 字节来实现。
举个例子:
http://www.xx.com/中http%3a%2f%2fwww.xx.com%2f%e4%b8%ad
原始 url 里面的 :、/、中 均被转码了。其中 中 的 UTF-8 形式是 0xE4B8AD,上面有介绍过。这里会通过 % 号进行每个字节分割。
这里有个小的疑惑点,即 % 号本身,并不是 URL 允许的字符,但是它可以直接用在 URL 中。举个例子:
http://www.xx.com/%http%3a%2f%2fwww.xx.com%2f%25
这里可以发现,% 本身在 URL Encoding 中也会被转成 %25,因为它的 UTF-8 字节是 0x25。
这也是 URL Encoding 规则的定义,通过 UTF-8 编码的字节,需要通过 % 进行字节分割。% 虽然不是 URL 允许的字符,但可以出现在 URL 中。
如此之后,URL 实际上可以被多次 encoding,每次 encoding 的时候 % 都会被换成 %25。
对 % URL Encoding 5 次之后结果是:%25252525。如果需要拿到最开始的 % 符号,也同样需要对应 URL Decoding 5 次。
所以开发过程中,Encoding 和 Decoding 的次数需要一致,这个非常重要。否则就拿不到正确的 URL。
音调
对于音调来说,每个字母都有 4 个音调。为 āáǎà 每个字符都设置一个码位有些不合适。而且除了音调,还有其他一些场景,也具有同样的现象。
Unicode 设计上,会通过两个码位来表示一个字符。即码位和字符并不总是 1:1 的关系,有时候是 2:1。
比如,ā字符,就是由 a 码位 和 ˉ 码位连续组合。
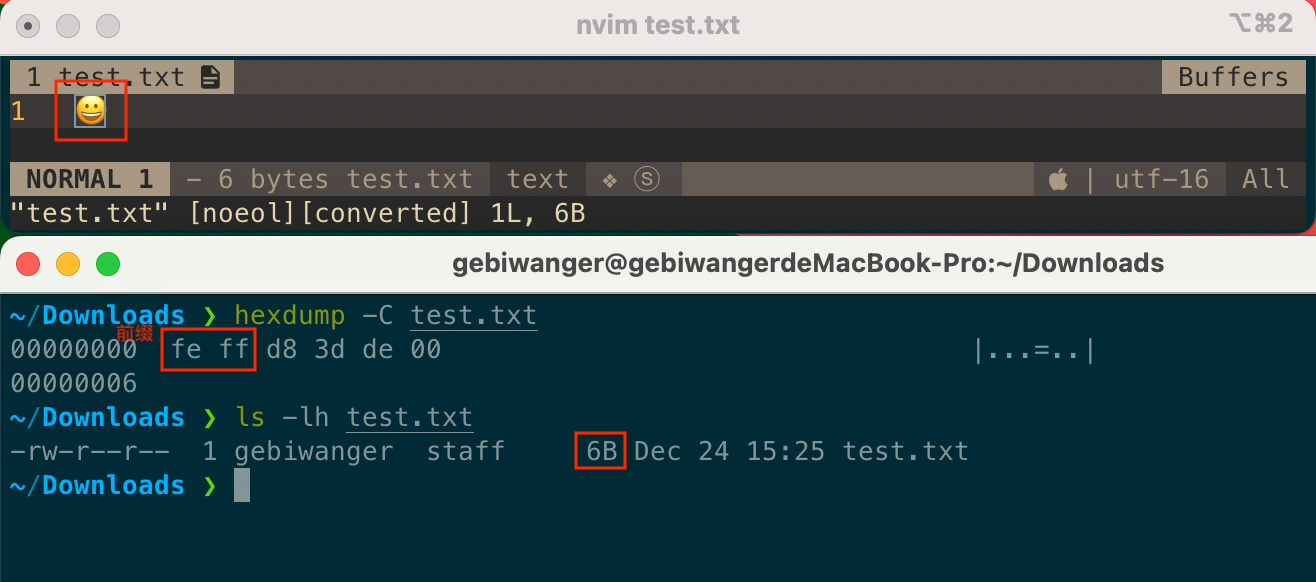
1 | > cat test.txt |
其中,a 和 ˉ 的 Unicode 码位分别是:
| 符号 | 码位 | 字节 | UTF-8 编码 | 十六进制 |
|---|---|---|---|---|
| a | 00000000 00000000 01100001(0x61) | 1 | 01100001 | 0x61 |
| ˉ | 00000000 00000011 00000100(0x0304) | 2 | <110>01100 <10>000100 | 0xcc84 |
存储的时候,两个码位还是单独存储的,上面 wc 命令查看共计 3 字节。只是展示的时候,需要应用层做识别,将音调显示在前面字母的顶部。
注意,两个码位组合代表一个字符,这是 Unicode 的规定,需要使用方遵守约定。
但 Unicode 本身并没有一套计算公式,将两个码位组合成一个码位。实际上就是两个码位按照前后顺序写入即可。
文本文件的识别
我们认为的文本文件,一般都是通过特定文本编码写入文本的文件,比如 .txt 或者 .m/.java 等文件。而非 .zip/.jpg 等文件。
对于文件而言,存储的内容都是二进制。虽然可以根据后缀认为某个文件是文本文件,但鉴于后缀也可以更改,所以这并不准确。
有一种方案是读取文件头的 magic number。但这种方案对于识别文件二进制类型比较有用,并不能识别出文本文件。因为文本文件一般都是没有特定的 magic number 的。
对于图片 / 视频等文件,读取它们的二进制内容和读取 .txt 等文本文件的技术方案一致。
不过对于图片等二进制,显然无法进行有效的 UTF 解码,所以读取后会是乱码。
对同一个文件进行一致的编码和解码,这样写入的二进制就具有一定的规则。读取的时候按照同样的规则进行解析,当然可以识别出当初写入的内容。
当然,可以对文件的二进制内容全部读出来,然后通过 UTF 进行解码,若能解出来,那就是文本文件。
这是稳定的方案,但具有极大的性能损耗。因为一个图片或者视频,它的二进制内容是非常多的,IO 成本过大。
有一个比较小巧的技术方案,即对文本内容主动进行多个位置的截取解码,以较小的性能开销来对文本文件进行识别。
比如从 文件头 N 偏移的位置截取 10 个字节数据。对这 10 字节进行不同维度的解码。
只要能有一次解出来,说明这 10 字节数据是符合文本编码规范的。(大概率无法一次解出。因为 10 字节里面只有一部分是完整的编码数据,两头很可能是被截断的,无法被解码)
同样的操作可以进行 M 次,需要 M 次全部命中,才能认为当前文件的确是文本文件。合理的设置 M 值,对于真的文本文件会具有很高的识别效率。
但只要有一次不命中,既可以确认当前文件不是文本文件。即非文本文件,可以一次命中,效率极高。
这样,也可以过滤图片文件中插入文本这种操作。
这种方案以读取少量的文本内容和多次匹配作为代价,可以比较稳定的确认当前文件是否是文本文件。
源代码可参考:HLVFileDump
内存字符编码
终于要说到内存中的字符编码了。这是非常重要的一环,也是很多人对于字符编码的卡点瓶颈所在。
前面说的字符使用 UTF 编码,都是以写入文本来说明的,主要阐述的是 UTF 编码的存储能力。
这一方面 UTF-8 通过多字节能力,可以非常有效的压缩文件大小。这在磁盘、网络传输等方面是绝对的王者。
但是在程序运行过程中,比如字符串大小匹配场景,也会对字符串进行操作。这时候的字符,在内存中是什么样的表现呢?
它一定会有一个表现形式,否则它就没法存在。
它可以通过码位 二进制的形式在内存中表达。上面也提到过磁盘存储也可以直接存储码位,但固定 3 字节的大小太费存储了,在内存这里显然更拘谨,所以更不合适。
也没更多选项了,要么 UTF-8,要么 UTF-16。因为 UTF-32 是 4 字节,那还不如直接存储码位了。
实际上,在内存中对于字符使用 UTF 的那个存储,不是由操作系统决定的,而是由编程语言决定的。对于高级语言一般都使用 UTF-16,但 C 语言使用 UTF-8。
在介绍内存编码之前,还是先简单说明一下二进制文件吧。文本文件属于二进制文件,但二进制文件具有更多的表现能力。
理解了它们,除了方便理解后面的内存字符编码,也对文件中的字节有更好的认识 (对于本文而言,这属于番外内容)。
二进制文件
所有文件都是二进制文件。
高级语言对文件进行读写的时候,需要通过内核塌陷的模式,调用操作系统 api 拿到文件句柄然后操作 read/write api。
这里 read 和 write 的数据,都是 Data 二进制。即文件、文件系统、操作系统、计算机,只理解二进制,不理解具体的字符。
对于二进制文件,也有很多种用途。比如:
文本文件,主要用来记录文字,将文字编码后写入,解码后还原。每个字节都是一致的含义,即都表示文字 (也可以认为没有含义)。
图片 / 视频文件,主要用来存储特定格式的数据。它的每个字节所表达的含义可能都不一样,比如 m-n 字节的数据表示地理位置,i-j 字节的数据表示拍摄机器的型号等。
可执行文件,如 Twitter,主要用来严丝合缝的存储自身需要的数据。它不需要被外部读取,它本身可运行读取自己。比如 ELF 文件,每个 section、每个段、符号表等,都需要存储在特定的区域。
这样看下来,从文件的角度来看,都是二进制数据,没有差别。但是对文件使用者来说,二进制文件的含义千差万别。
在很多年前,我希望同事将 jpg 图片改成 png 图片。拿到 png 图片后程序的 bug 依旧没有解决。最后排查发现同事把 .jpg 的后缀改成了 .png :(
程序走 .png 的逻辑,但内部数据是 .jpg 的格式,这就会导致无法解析。
值编码
说到内存编码,是针对刚才提到的可执行二进制文件来说的。因为文件执行起来后,才会使用字符和内存。
对于下面三种场景,同样的字符 1,具有同样的字节大小,但使用方式一点都不一样:
1 | int8 i = 1; |
对于 1 字符,在 二进制数、ASCII 和 Unicode 中分别是如下定义:
1 | 数字二进制 int8:00000001(0x1) |
编译器需要对 int 类型的 1 进行数字操作,通过数字二进制就可以表达,不需要使用字符集码位。
对于 char 类型,编译器明确该类型只需要满足 ASCII,直接使用 ASCII 码位即可。
对于 String 类型,下面细说。
这就是值编码。即这个字符使用什么编码,是和它的类型有关,编译器最终会决定编码类型。
内存字符编码
在文本文件的时候,文件使用 UTF8 编码,但是读取文件的时候还需要解码,目的是解出码位,通过码位识别当前字符是哪个坑位,以做应用层显示。
但对于可执行程序而言,内存中的数据可以从可执行文件中读取,且不需要解码。即可执行文件中该字符是什么内容,原封不动的读取放入内存或者寄存器即可。
这样的目的是省去解码操作,直接进行二进制的读取即可,可执行文件是速度优先,整个编译器都在为速度服务。
所以对于上面的 String 类型,在内存中使用何种编码,直接通过查看可执行文件来确认。下面开始准备物料进行分析:
1 | // Swift |
选了三个不同的语言,字符串末尾增加了 1/2/3 标记。下面看下编译产物:
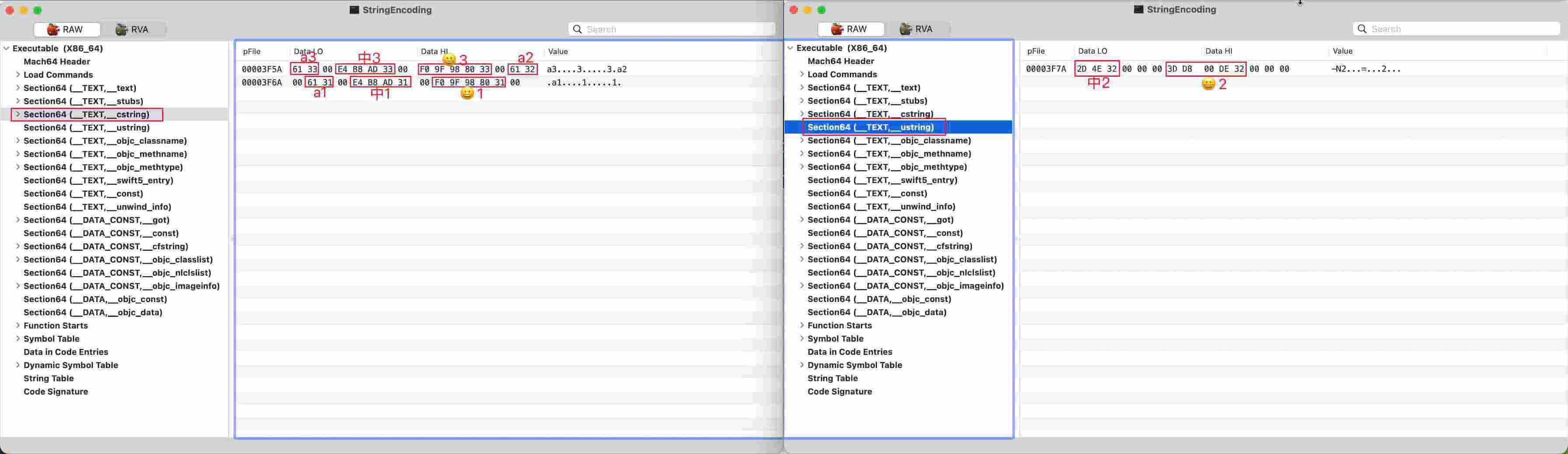
显然,内存中各种高级语言也是使用了 UTF 编码,这没得选择,Unicode 和 UTF 是绝配。
- C 语言统一使用 UTF8 编码
- Objective-C 同时使用了 UTF8 和 UTF16
- Swift 使用了 UTF8(查阅资料说 Swift 也会在某些场景下使用 UTF16,没能复现)
但各类语言的内存编码使用情况并不是一边倒的偏向某一方。
比如 Java/Python/JS 使用的是 UTF16,Go/Swift 使用的是 UTF8。还有些是两者同时使用如 Objective-C。
在内存中使用 UTF8 或者 UTF16,主要考虑的并不是存储和编解码性能。
因为在程序运行过程中操作的字符频率并不会很多,远远不如一个 .txt 或者 .png 里面动不动几十 K 或者几十 M。
内存中在乎的是字节操作性能。在算法执行过程中,对字符的 比较 / 截取 / 复制 等操作,那是越快越好。
在配置相同的情况下,哪个编码的字节小,哪个就会快一些。
比如对 a、b 两个字符进行比较,若使用 UTF8,则只需要比较 1 个字节。若使用 UTF16,则需要比较 2 个字节。
对于 中、文 两个字符比较,UTF8 需要比较 3 个字节,UTF16 需要比较 2 个字节。
因为 Unicode 码位的不同位置区块,是偏向不同国家语言的。比如英文主要集中在前面的 ASCII 部分,中文就比较靠后。
在 UTF8 场景,英文肯定占有优势,字符串操作的字节数直接比中文少了一大半。
但大家又集中处于 零平面 区块,在 UTF16 里面基本所有国家的字符都是 2 字节,从上帝视角来看这又比较公平。
最好的办法当然是根据文本内容的不同,选择不同的编码。
目前 Objective-C 的做法是:若字符中全是 ASCII,则使用 UTF8。只要有不是 ASCII 的字符,则使用 UTF16。这是一定程度上的优化。
听说 Swift 可以根据内容,智能的选择哪一个更合适 (若英文偏多则使用 UTF8 这样子),但本地没能复现。但显然这是最优解。
体毛具有生长期、休止期。头发的生长期很长,可以持续 2-6 年。腿毛的生长期只有几个月。
生长期结束后就不长了,休止期会退毛,然后毛囊长出新的毛发。重复生长期过程。
所以头发可以很长但是腿毛就很短。