【Swift】中文词语纠错
一直有一个写字痛点,就是错别字。尤其在发帖子和写文章这样的正式场合,错别字会引起很大的误解,而每次检查都会很吃力。
试用了人气较高的 “写作猫” 和 “火龙果” 两个纠错平台,都有很大的局限性,并不适合我这样的人使用。
写作猫的缺点是 word 走天下,一点也不 nice。
火龙果的缺点是没有纠错能力,我用测试文档只检测出来两个不存在的英文错误。
它们都不支持 markdown 检测。
付费较高,对于非高频使用人员不友好。
于是,尝试自己写一个纠错工具,目前做了开源,支持 CLI 和 GUI,详见:HLVSentence、HLVZhCorrect。
技术方案是:检测文本文件 -> 文本分句 -> 词语检测 -> 工具集成。
遇到的核心问题有:
- 准确识别文本文件。文本文件无 Magic Number 二进制特征,如何准确识别当前文件为文本文件并读取内容。
- 文本分句校准。对于纯中文场景,通过常用的标点符号即可正则分句。但一般会参杂英文、特殊符号,还有 markdown。
- 中文纠错检测和校准。找了不少方案,最后选择 pycorrector 提供的中文纠错模型。工具需要和 python 环境做对接,并对待检测文本做进一步校准以满足模型。
- 非终端环境和 python 脚本互联。需要支持 python 虚拟安装环境。
- SwiftUI 开发 “命令行 CLI 工具” 和 “Mac 菜单栏工具”,将工具对接 brew 平台。
下面是开发文本纠错工具的一些历程。
Demo 演示
可查阅 HLVSentence、HLVZhCorrect 两个项目的 readme 主页,查看 CLI 和 GUI 的效果和使用说明。
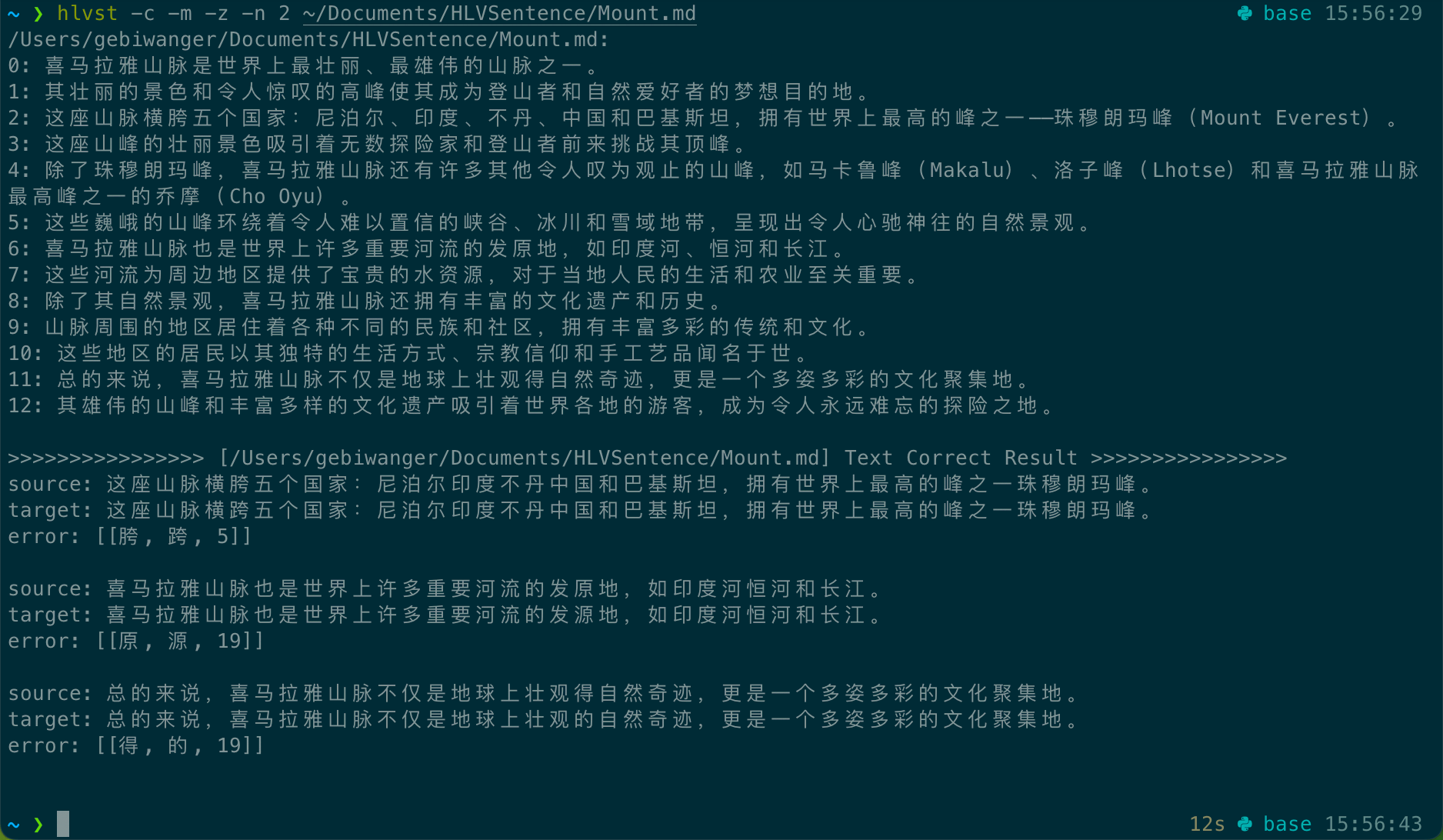
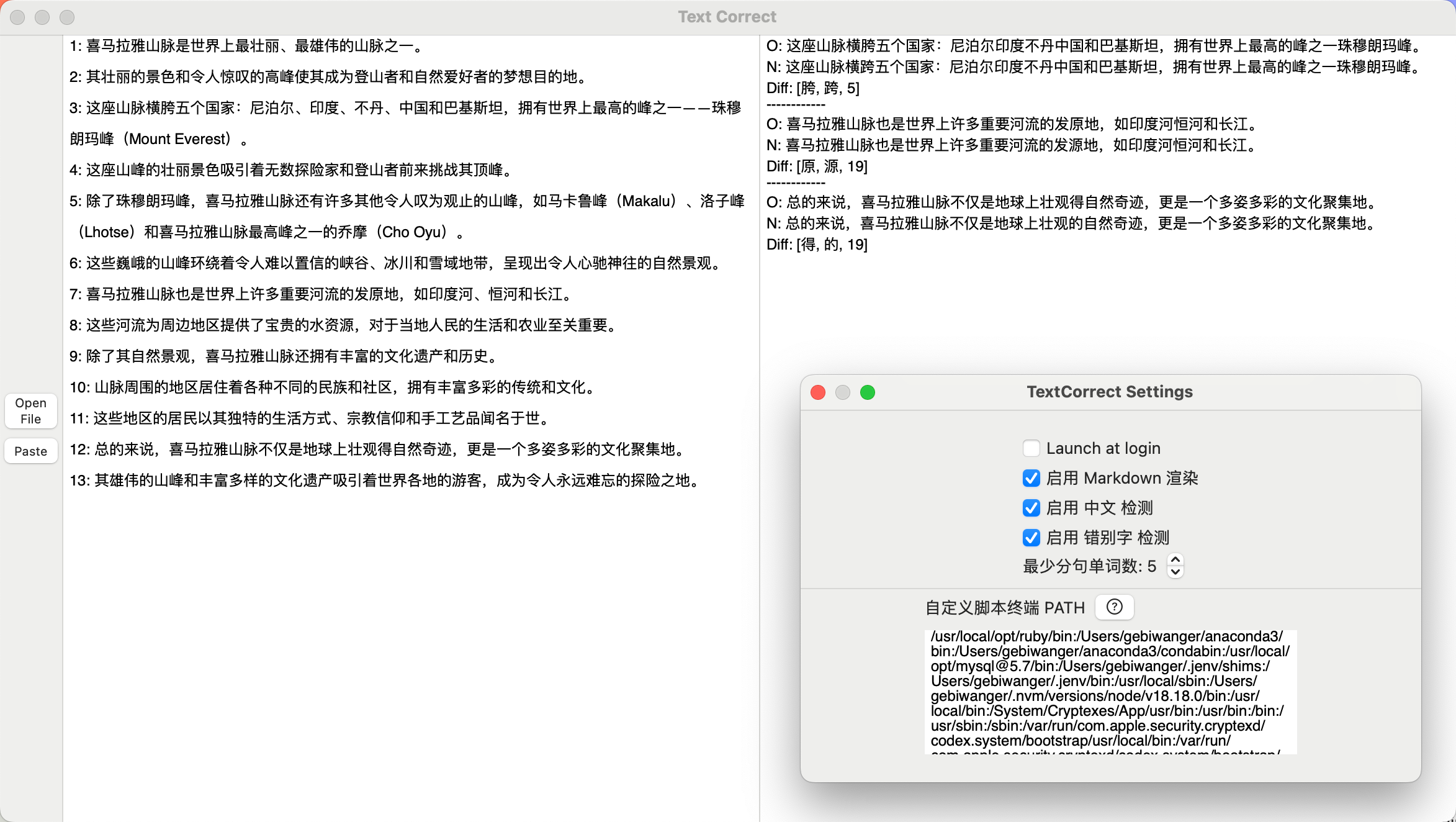
文本文件识别
对于具有特定使用场景的二进制文件,它们不需要遵循 Unicode 字符集规范。因为使用场景专一,一般都会通过 Magic Number 对文件类型进行标识,如 ELF、Zip 等。
但对于一个文件是否是文本文件,并没有完全行之有效的识别方案。只能通过尝试去理解内容,这是有一定误差的。
对于文本文件所具有的识别属性,可以从以下几点考虑:
- 文件后缀。【特定场景下稳定,对用户信任】
- magic number 排除。【文本文件均无稳定的 magic number】
- 编码识别。【文本文件一定有一致的编码和解码方案】
通过文本编码可以最为精确的识别当前文件是否是文本文件,从而进一步依靠对应的编码来读取文本内容。但这也会有一些问题:
- 性能问题。文本文件一般较小,可以进行全量解码。但待解码的文件可能是图片或者压缩包,这会有极大的性能损耗。
- 二进制中存在文本标记。二进制文件中部分位置可能插入文本,用于记录一些信息。如果读取部分内容且正好读取了这一部分,则有一定的误判概率。
所以,有一个可行的方案:
- 先判断有没有 magic number。如果有,则可以识别到当前文件的具体类型。
一般只要有 maigc,就不再是文本文件了。 - 再对文件内容进行多个位置的截取解码。根据文件大小
动态设置采样点,且所有采样点解码全部通过,则判定为文本文件。
Swift 文本文件识别 源码详见:HLVFileDump
对于文本编码的详细介绍可查阅 计算机字符编码与内存编码
文本分句
纯中文环境下的分句,比较好实现。只需要控制将?、;等几个特别的断句符号进行识别即可。
但很少有纯中文的段落,一般都是中英文混杂,而且还有个数算术符号。如下面几个例子:
今天的温度是 25.3°C,天空晴朗,风速约 10 mph.,这里末尾是英文的.收尾,且数字中含有.无法做断句。这里只能通过 NLP 语言模型进行分句,Apple 提供了NaturalLanguage物料库,可以在多语言混合的场景下,进行语句分割,且能够处理数字符号。今天天气不错(适合出游),你要参加吗?,这里 NLP 就不能很好识别,会把中文的(进行分句,导致()两个字符被分割到两个分句里面。1. 吃饭 2. 睡觉 3. 打豆豆,这样有数字前缀或者其他特殊字符前后缀的,在分句后理应去除序号或者特殊描述符号,只保留汉字内容。这个 NLP 能初步识别,但也有误差,基本够用。- 特殊标记符号如
\t等,需要特别处理。它们会影响到分句的质量。
这里的一个可行方案是:
- 先根据中文符号进行一次分句。此时结果基本符合中文语意,但中英文和符号混杂的地方无法分割。
- 将上一步的分句结果使用 NLP 二次分句,此时基本符合分句诉求,偏差不大。
但是在可行方案执行前,还有一个重要的点,是 NLP 对 markdown 识别不敏感,误差率较高。还需要先进行 markdown 的去格式化。
文本纠错
找了很多文本纠错开源方案,大多不理想。甚至文章开头说到的商业平台,测试下来也没有很优秀。
一个很主要的点,是纠错是针对单词而非语境的。针对单词的纠错通过大量的单词匹配即可,但误差率较高。
最后使用的是 python3 实现的 pycorrector 模型,能够部分识别语境。
对模型参数进行一些调整处理后,目前能够做到:
- 如果有错,非常大的概率是能够被检测到。
- 如果没错,有小部分概率认为有错。
就像布隆过滤器一样,没有漏,也是可以的。又不是不能用。
当然,模型对数据更严格,稍有不慎,就检测失败了。最大的问题是不支持英文和特殊符号。
所有在文本纠错的时候,又对上面的分句内容进行中文提取,然后交由 pycorrector 检测。
python 环境数据互通
前面分句的结果在 Swift 可执行程序的内存里,后面需要交用 python 脚本执行并拿到处理结果。
一个可行的办法是 app 中嵌入 python 解释器,但这会凭空增加复杂度,且不好维护 pycorrector 模型库。
最后通过 SwiftShell 高效的命令行工具 实现了数据互通。
因为 app 环境中缺失终端环境变量,这在使用 Conda python 虚拟环境的时候会找不到 python 可执行三方库。
最后的解决方案是委屈用户,需要自行通过 echo $PATH 获取终端 path 后设置到 app 中。
对于 CLI 环境倒比较友好,因为 CLI 本来就是在终端中运行的,已经拥有了终端上下文 Env,没有遇到太多的问题。
CLI 和 SwiftUI
Swift 开发 CLI 命令行,整体还是比较快速简便的,官方有较好的支持。
入门可以参考:Swift 脚本开发环境搭建,当前项目也是完全按照入门说明来操作的。尤其文中的 不换行更新上一次的输出结果 和 异步等待,在命令行开发过程中很有用。
SwiftUI 开发 Mac 还是有不少概念需要理清。
AppKit 和 UIKit 有很大的差异,比如 Window/WindowController/NSMenu/NSStatus 等。SwiftUI 又要抹平两者的差异,所以 SwiftUI 整体上和 AppKit/UIKit 都有较大差异。
建议一个入门方式,是通过 Xcode 的 Development Documentation 快速查看 SwiftUI 的编写规则,混个脸熟。
然后在 Github 上面搜索 Api 找到一些比较新的 SwiftUI 项目阅读源码。
最后,频繁的咨询 ChatGPT,有时候它给的答案并不对,但能给一个大致的方向。
brew
可参考当前工程的私有配置:homebrew-tap。
brew 自定义仓库等相关资料较少,本人也没有进一步学习。
目前把 CLI 和 GUI 都部署到了自定义仓库中,有需要的可以简单参考下。
App Store 真的做到了 “花开两朵,各表一支”。
在 Mac 上,Mac App Store (MAS) 犹如鸡肋,复杂的沙盒安全形同虚设。
Apple 看着 MAS 生意惨淡,却毫无作为。既不能做为平台为优秀的软件做宣传,也阻止不了垃圾软件的恶意收费。